
Bien qu’il ne semble pas aussi essentiel à la sécurité que la protection contre les malwares et la détection des violations, le filtrage de contenu Web joue un rôle important pour garantir la conformité réglementaire, la sécurité des lieux de travail ainsi que la sécurité des réseaux. Contrairement à la classification de sécurité des URL, qui filtre les contenus malveillants tels que les malwares ou le phishing, le filtrage Web doit étiqueter le contenu en fonction non pas des mécanismes d’attaque mais de la nature de son contenu, un problème beaucoup plus global que la simple vérification des schémas malveillants dans le contenu lié à une URL.
Les étiquettes de catégorie des sites Web décrivent généralement le contenu ou l’objectif du site. Certaines catégories sont des classifications larges telles que “entreprises”, “ordinateurs et Internet”, “nourriture et restauration” et “divertissement”. D’autres se concentrent sur un objectif précis, comme “opérations bancaires”, “shopping”, “moteurs de recherche”, “réseaux sociaux”, “recherche d’emploi” et “éducation”. Et puis il y a des catégories qui peuvent inclure des contenus préoccupants : par exemple “sexuellement explicite”, “alcool”, “marijuana” et “armes”, par exemple. Les entreprises peuvent choisir de définir diverses politiques pour filtrer ou évaluer les types de site Web accessibles à partir de leurs réseaux.
Sophos X-Ops a recherché des moyens d’appliquer l’apprentissage automatique basé sur les grands modèles de langage (LLM : Large Language Models) au filtrage Web pour aider à prendre en compte la “longue traîne” des sites Web, ces millions de domaines qui ont relativement peu de visiteurs et peu ou pas de visibilité pour les analystes humains. En réalité, les LLM eux-mêmes ne sont pas vraiment prévus pour ce type d’utilisation en raison de leur taille et du coût des ressources de calcul. Mais ils peuvent être utilisés à leur tour comme modèles “formateurs” pour entrainer des modèles plus petits à la catégorisation, réduisant ainsi les ressources de calcul nécessaires afin de générer instantanément des étiquettes (labels) pour les domaines nouvellement rencontrés.
En utilisant des LLM (Large Language Models) tels que GPT-3 d’OpenAI et T5 Large de Google, l’équipe SophosAI a pu entraîner des modèles beaucoup plus petits pour classer instantanément des URL jamais filtrées auparavant. Plus important encore, la méthodologie utilisée ici pourrait servir à créer de petits modèles économiquement déployables basés sur la sortie des LLM afin de mener d’autres tâches de sécurité.
Les recherches de l’équipe, détaillées dans un article récemment publié intitulé “Web Content Filtering Through Knowledge Distillation of Large Language Models“, explorent les moyens par lesquels les LLM (Large Language Models) pourraient être utilisés pour renforcer la classification existante des sites, mise en œuvre aujourd’hui par l’homme. L’objectif serait alors de créer des systèmes déployables afin d’effectuer une sorte d’étiquetage (labeling) en temps réel d’URL jamais observées auparavant.
Le problème de la “longue traîne”
La catégorisation des sites s’est largement appuyée sur le mapping domaine-catégorie basé sur des règles, au niveau duquel des signatures élaborées par des analystes sont utilisées pour rechercher des signes caractéristiques dans les URL afin d’attribuer rapidement des étiquettes à de nouveaux domaines. Ce type de mapping est essentiel pour identifier rapidement les URL concernant des sites bien connus et empêcher ainsi les faux positifs qui peuvent bloquer des contenus importants. L’identification humaine manuelle des modèles de classification de site est intégrée à l’ensemble des fonctionnalités des outils de mapping de domaine.
Le problème vient de la “longue traîne” des sites Web, ces domaines moins visités qui ne reçoivent généralement pas de signatures. Avec l’émergence quotidienne de milliers de nouveaux sites Web et avec plus d’un milliard de sites Web existants, la maintenance et la mise en œuvre manuelle des approches basées sur les signatures pour la longue traîne sont devenues de plus en plus difficiles. La forte baisse de l’étiquetage pour les domaines moins visités est évidente alors que les sites bien connus et à fort trafic obtiennent une couverture de près de 100 % dans la plupart des schémas d’identification. Comme le montre le diagramme ci-dessous, la proportion de domaines étiquetés par les analystes commence à chuter rapidement au-delà des cent domaines les plus visités. Les sites classés en dessous du top 5000 ont moins de 50 % de chances d’avoir été étiquetés pour leur contenu.
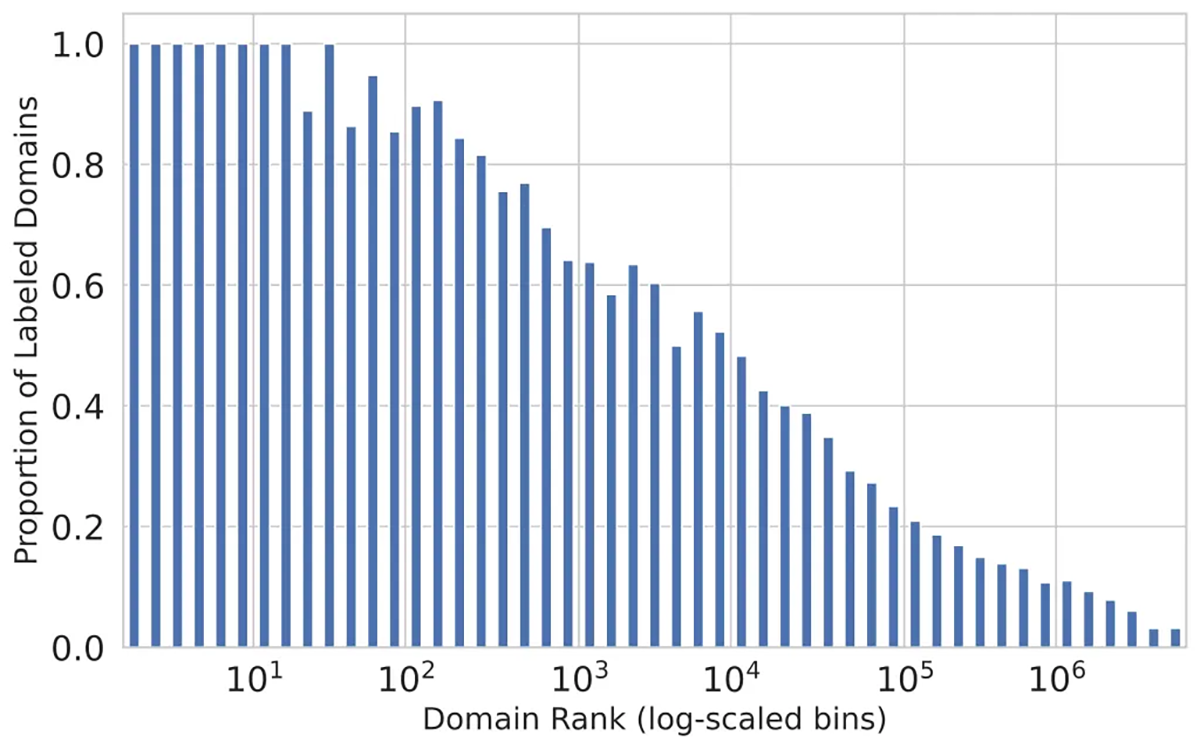
Figure 1 : Étiquetage du contenu relatif à la popularité des domaines, obtenu à partir de la télémétrie. Une façon de résoudre ce problème consiste à utiliser l’apprentissage automatique pour traiter des domaines auparavant non étiquetés. Mais jusqu’à présent, la plupart des efforts d’apprentissage automatique (tels que Microsoft URLTran) ont utilisé des modèles de deep learning pour se focaliser sur la détection des menaces de sécurité, plutôt que sur la catégorisation des sites en fonction de leur contenu. Ces modèles pourraient être recyclés pour effectuer une classification multicatégorie, mais ils nécessiteraient des ensembles de données d’entraînement extrêmement volumineux. URLTran a utilisé plus d’un million d’échantillons uniquement pour l’entraînement à la détection d’URL malveillantes.
Automatiser avec l’IA
C’est donc là qu’interviennent les LLM (Large Language Models). En effet, comme ils sont pré-entraînés sur des quantités massives de texte non étiqueté, l’équipe SophosAI a estimé que les LLM pourraient être utilisés pour effectuer un étiquetage d’URL plus précis et avec beaucoup moins de données initiales. Une fois ces modèles affinés sur les données étiquetées avec des signatures de propagation de domaine, l’équipe SophosAI a constaté que les LLM offraient un gain de 9% en matière de précision par rapport à l’architecture de pointe de Microsoft lorsqu’il s’attaquait au problème de catégorisation “longue traîne” et ne s’appuyait que sur un ensemble d’entraînement composé de milliers d’URL, plutôt que de millions.
Les LLM, utilisant des relations sémantiques entre les classes de site et les mots-clés présents dans les URL d’un ensemble de données plus petit, ont ensuite été utilisés pour créer des étiquettes destinées à un ensemble de données non étiqueté provenant de sites à longue traîne, lesquels ont ensuite été utilisés pour entraînés des modèles plus petits (BERTiny, les modèles Transformer d’URLTran basés sur BERT et le modèle convolutif 1D eXpose). Cette approche de “distillation des connaissances” (knowledge distillation) a permis à l’équipe d’atteindre des performances similaires à celles des LLM avec des modèles 175 fois plus petits, réduisant ainsi le nombre de paramètres de 770 millions à seulement 4 millions.
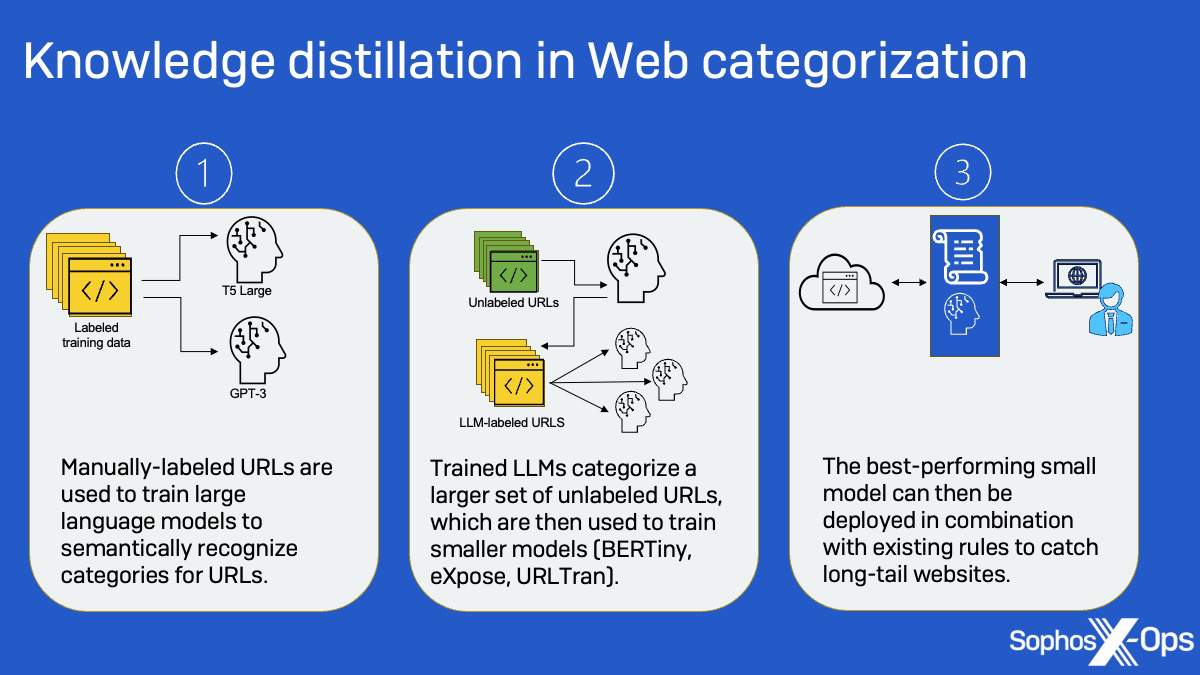
Figure 2 : Comment la distillation des connaissances a été utilisée pour créer des modèles déployables.
Bien que les ensembles de modèles les plus précis créés aient obtenu de bien meilleurs résultats que les modèles entraînés uniquement par “deep learning”, leur précision n’atteint pas la perfection, même les meilleurs modèles ont obtenu une précision inférieure à 50 %. De nombreuses URL n’ont pas été correctement étiquetées simplement parce qu’elles n’avaient pas suffisamment de “signaux” intégrés, tandis que d’autres avaient des mots-clés qui pouvaient être associés à plusieurs classifications, créant ainsi une incertitude qui ne pouvait être clarifiée que par un examen plus approfondi du contenu lié à l’URL en question.
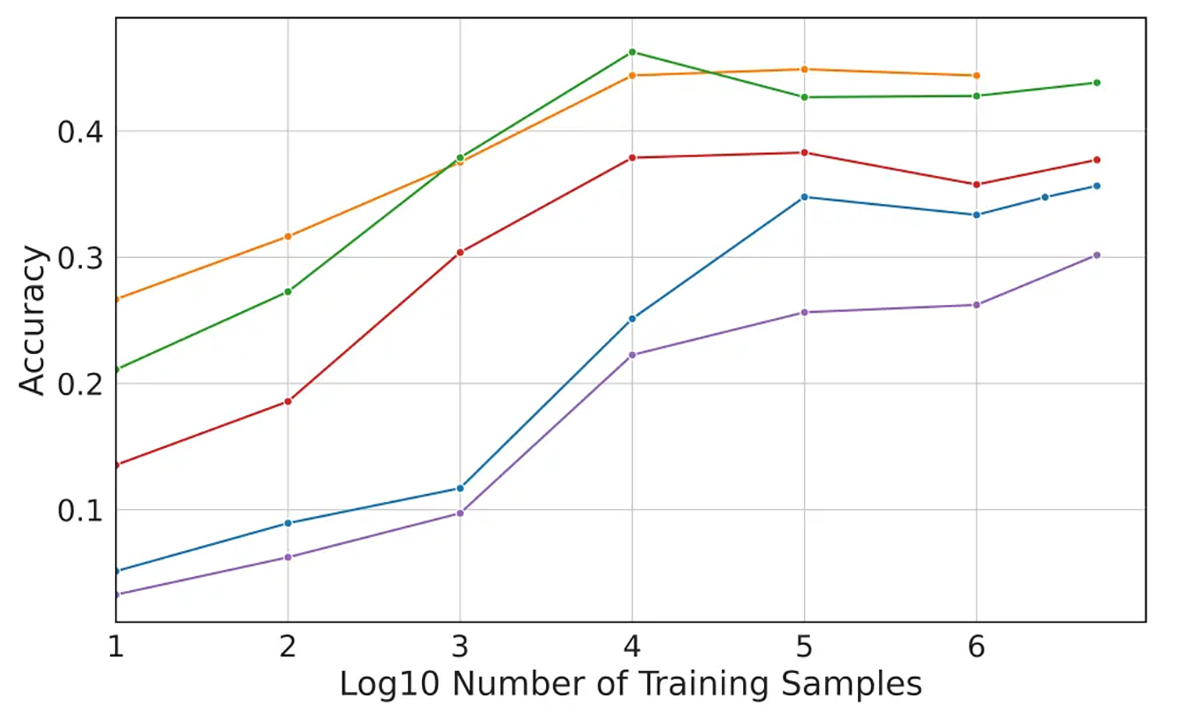
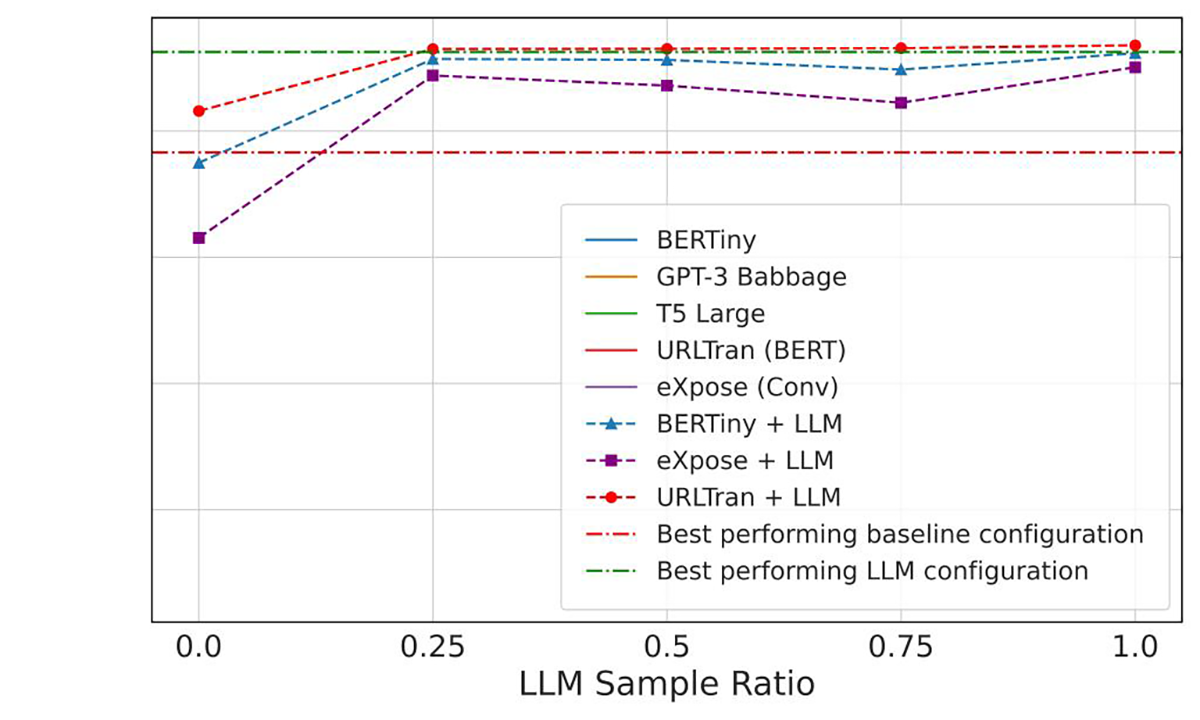
Figures 3 et 4 : Une représentation précise des modèles entraînés. Les LLM ont surpassé les modèles plus petits entraînés par deep learning, mais les modèles plus petits ont approché le même niveau de précision lorsque les LLM ont été utilisés comme modèles d’apprentissage (l’axe Y dans les deux graphiques a une précision de 0 à 0,5).
Cependant, le modèle T5 Large a relativement bien fonctionné sur les catégories qui étaient potentiellement filtrées, comme le montre la matrice de confusion ci-dessous, les sites de jeux d’argent et de partage peer-to-peer ont un étiquetage presque parfait sur les données de test. Les sites liés à l’alcool, aux armes et à la pornographie avaient également des taux de détection de vrais positifs supérieurs à 60 %.

Figure 5. Une matrice de confusion montrant la relation entre les étiquettes attribuées par le modèle T5 Large aux URL de test et leurs véritables étiquettes attribuées manuellement,
L’équipe SophosAI a suggéré plusieurs façons d’améliorer cette précision à l’avenir. Premièrement, permettre l’attribution de plusieurs catégories à un site éliminerait les problèmes de chevauchement de catégorie. Enrichir les exemples d’URL avec du code HTML et des images récupérés à partir de ces dernières pourrait également permettre une meilleure reconnaissance de leur catégorisation, et les nouveaux LLM, tels que GPT-4, pourraient être utilisés comme formateur.
Combinée aux processus existants, cette forme de classification basée sur l’IA peut grandement améliorer la gestion des sites Web à longue traîne. Et il existe d’autres tâches liées à la sécurité auxquelles la méthodologie de “distillation des connaissances” testée dans cette expérience pourrait être appliquée.
Pour obtenir plus de détails, consultez l’article rédigé par Tamas Voros, Sean Bergeron et Konstantin Berlin, Head of SophosAI, en vous rendant sur sur arxiv.org.
Billet inspiré de And I Shall Call It Mini-Me GPT: Using Large Language Models to Classify the Uncharted Web, sur le Blog Sophos.
Qu’en pensez-vous ? Laissez un commentaire.