
La technologie d’apprentissage automatique (Machine Learning) basée sur les LLM (Large Language Models) se développe rapidement, avec plusieurs architectures open source et propriétaires concurrentes désormais disponibles. En plus des tâches impliquant la génération de texte associées à des plateformes telles que ChatGPT, les LLM se sont avérés utiles dans de nombreuses applications de traitement de texte, allant de l’aide à l’écriture de code jusqu’à la catégorisation du contenu.
SophosAI a étudié plusieurs façons d’utiliser les LLM au travers de tâches liées à la cybersécurité. Mais étant donné la variété des LLM disponibles, les chercheurs sont confrontés à une question difficile : comment déterminer quel modèle est le mieux adapté à un problème d’apprentissage automatique (machine learning) particulier. Une bonne méthode pour sélectionner un modèle consiste à créer des tâches de référence/benchmark : à savoir des problèmes typiques qui peuvent être utilisés pour évaluer facilement et rapidement les capacités du modèle.
Actuellement, les LLM sont évalués sur certains critères, mais ces tests évaluent uniquement les capacités générales de ces modèles au niveau de tâches basiques en matière de traitement automatique du langage naturel (NLP). Le classement (Leaderboard) Huggingface Open LLM (Large Language Model) utilise sept critères distincts pour évaluer tous les modèles open source accessibles sur Huggingface.
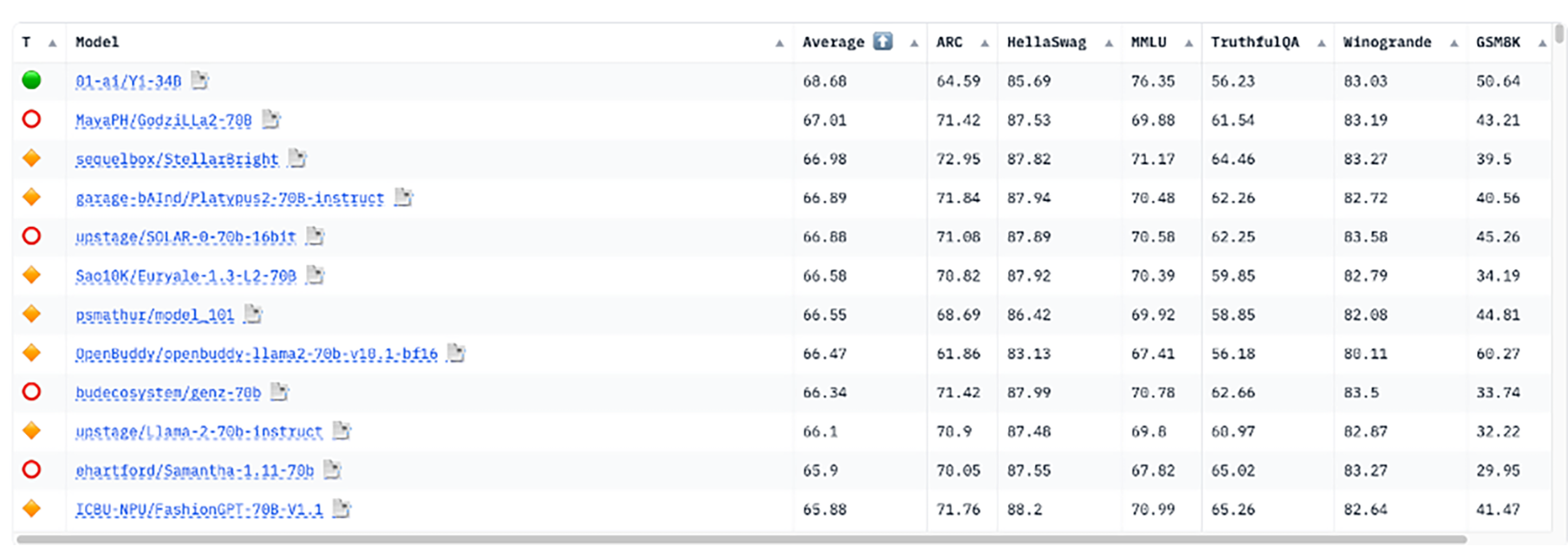
Figure 1 : Classement (Leaderboard) Open LLM Huggingface
Cependant, les performances concernant ces tâches de référence/benchmark peuvent ne pas refléter avec précision l’efficacité des modèles dans des contextes de cybersécurité. Étant donné que ces tâches sont généralisées, elles peuvent ne pas révéler de disparités en matière d’expertise spécifique à la sécurité entre les modèles résultant de leurs données d’entraînement.
Pour surmonter ce problème, nous avons décidé de créer un ensemble de trois références (benchmarks) basées sur des tâches que nous considérons comme des avantages essentiels pour la plupart des applications de cybersécurité défensive basées sur les LLM :
- Capacité à agir en tant qu’assistant d’investigation des incidents en convertissant les questions en langage naturel au niveau de la télémétrie en instructions SQL.
- Capacité à générer des synthèses d’incidents à partir des données du SOC (Security Operations Center).
- Capacité à évaluer la gravité de l’incident.
Ces références/benchmarks servent deux objectifs : identifier les modèles de base ayant un potentiel en matière d’ajustement, puis évaluer les performances prêtes à l’emploi (non ajustées) de ces modèles. Nous avons testé 14 modèles par rapport à ces références, dont trois versions (de tailles différentes) des modèles suivants : LlaMa2 et CodeLlaMa de Meta. Nous avons choisi les modèles suivants pour notre analyse, en les sélectionnant en fonction de critères tels que la taille du modèle, la popularité, la taille du contexte et la récence :
| Nom du modèle | Taille | Fournisseur | Taille Max. du Contexte |
| GPT-4 | 1,76T ? | OpenAI | 8K ou 32k |
| GPT-3.5-Turbo | ? | 4K ou 16k | |
| Jurassic2-Ultra | ? | AI21 Labs | 8k |
| Jurassic2-Mid | ? | 8k | |
| Claude-Instant | ? | Anthropic | 100k |
| Claude-v2 | ? | 100k | |
| Amazon-Titan-Large | 45B | Amazon | 4k |
| MPT-30B-Instruct | 30B | Mosaic ML | 8k |
| LlaMa2 (Chat-HF) | 7B, 13B, 70B | Meta | 4k |
| CodeLlaMa | 7B, 13B, 34B | 4k |
Sur les deux premières tâches, GPT-4 d’OpenAI avait clairement les meilleures performances. Mais lors de notre évaluation finale, aucun des modèles n’a été suffisamment précis pour catégoriser la gravité des incidents afin d’être meilleur que la sélection aléatoire.
Tâche 1 : Assistant d’investigation des incidents (Incident Investigation Assistant)
Dans notre première tâche de référence/benchmark, l’objectif principal était d’évaluer les performances des LLM en tant qu’assistants-analystes SOC dans l’investigation des incidents de sécurité en récupérant des informations pertinentes basées sur des requêtes en langage naturel : une tâche que nous avons déjà expérimentée. L’évaluation de la capacité des LLM à convertir des requêtes initialement en langage naturel en instructions SQL, guidée par la connaissance des schémas contextuels, permet de déterminer leur adéquation à cette tâche.
Nous avons abordé la tâche comme un problème de prompting en mode ‘few-shot’. Au départ, nous fournissons au modèle les instructions dont il a besoin pour traduire une requête en SQL. Ensuite, nous fournissons les informations au niveau du schéma pour toutes les tables de données créées pour ce problème particulier. Enfin, nous présentons trois séries d’exemple de requête et leur instruction SQL correspondante pour servir d’exemples pour le modèle, ainsi qu’une quatrième requête que le modèle doit traduire en SQL.
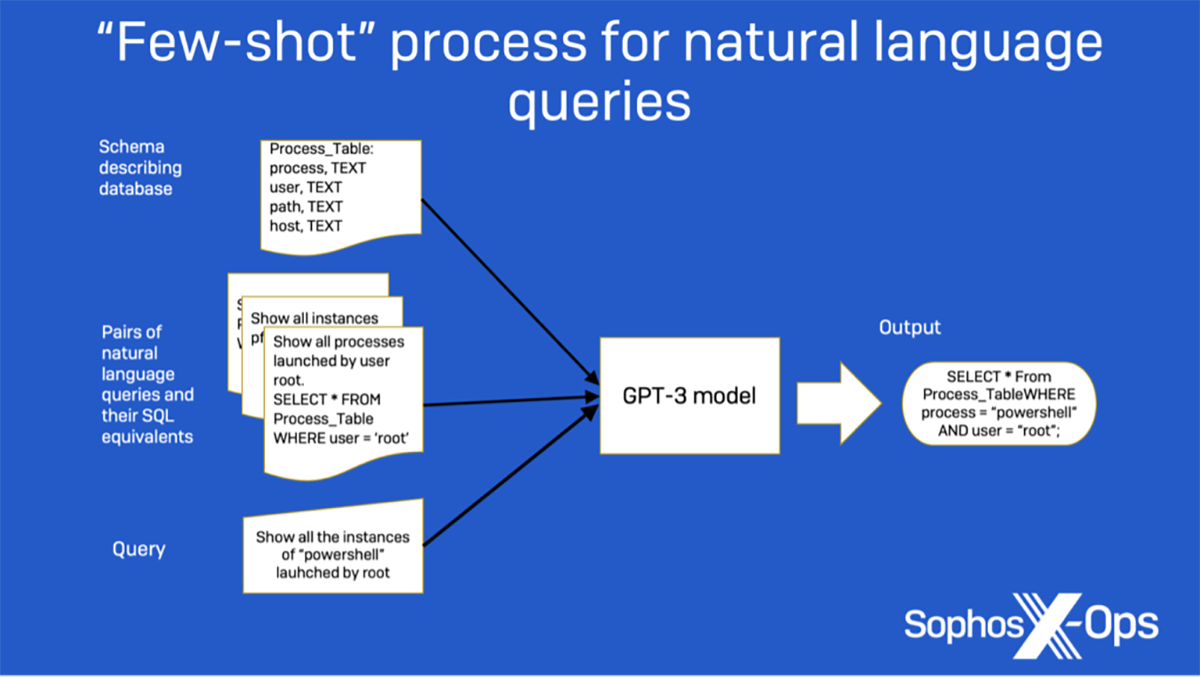
Figure 2 : Un graphique montrant l’approche “few-shot” utilisée dans notre recherche initiale sur les requêtes en langage naturel
Un exemple de prompt pour cette tâche est présenté ci-dessous :

Figure 3 : Un exemple de prompt utilisé dans le benchmark de l’assistant d’investigation des incidents
La précision de la requête générée par chaque modèle a été mesurée en vérifiant d’abord si la sortie correspondait exactement à l’instruction SQL attendue. Si la sortie SQL ne correspondait pas exactement, nous exécutions alors les requêtes en utilisant la base de données de test que nous avions créée et comparions les ensembles de données résultants avec les résultats de la requête attendue. Enfin, nous avons transmis la requête générée et la requête attendue à GPT-4 pour évaluer l’équivalence au niveau de ces dernières. Nous avons utilisé cette méthode pour évaluer les résultats de 100 requêtes pour chaque modèle.
Résultats
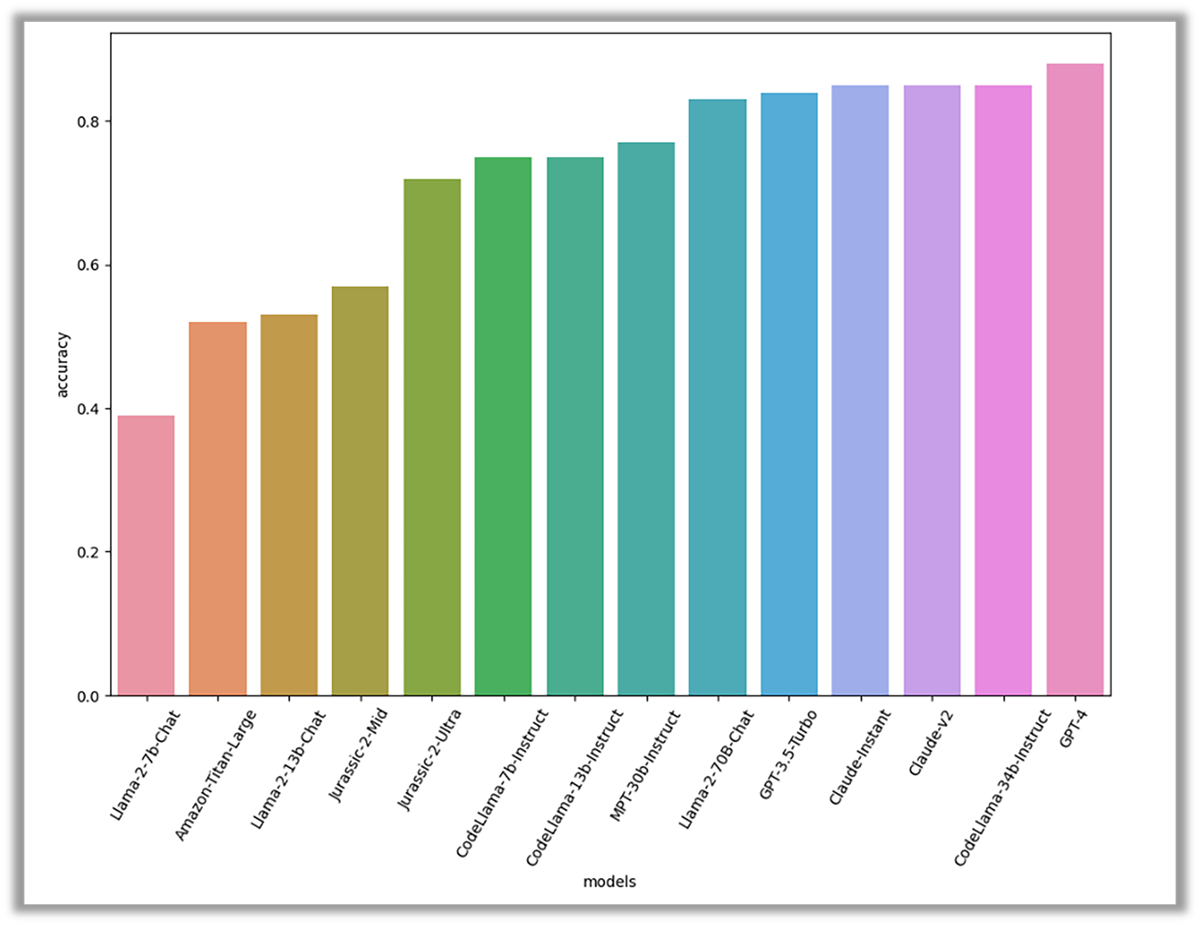
Figure 4 : Résultats du benchmark en matière de génération de requêtes ; GPT-4 d’OpenAI était le plus précis, suivi de CodeLlaMa 34b de Meta, des modèles Claude d’Anthropic et du GPT-3.5 Turbo d’OpenAI.
Selon notre évaluation, GPT-4 était le plus performant, avec un niveau de précision de 88 %, suivi de près par trois autres modèles : CodeLlama-34B-Instruct et les deux modèles Claude, le tout avec une précision de 85 %. Les performances exceptionnelles de CodeLlama dans cette tâche étaient attendues, car elle se concentrait sur la génération de code.
Dans l’ensemble, les scores de précision élevés indiquent que cette tâche est facile à réaliser pour les modèles. Ce constat suggère que ces modèles pourraient être utilisés efficacement pour aider les analystes en menaces à investiguer de manière inédite et originale les incidents de sécurité.
Tâche 2 : Synthèse de l’incident (Incident Summarization)
Dans les SOC (Security Operations Centers), les analystes en menaces investiguent quotidiennement de nombreux incidents de sécurité. Généralement, ces incidents sont présentés comme une séquence d’événements survenus au niveau d’un système endpoint ou d’un réseau utilisateur, liés à une activité suspecte détectée. Les analystes en menaces utilisent ces informations pour mener une investigation plus approfondie. Cependant, cette séquence d’événements peut souvent contenir un certain niveau de bruit et prendre du temps à être parcourue par les analystes, rendant ainsi difficile l’identification des événements majeurs. C’est là que les grands modèles de langage peuvent s’avérer utiles, car ils peuvent aider à identifier et organiser les données d’événement sur la base d’un modèle spécifique, permettant ainsi aux analystes de comprendre plus facilement ce qui se passe et déterminer les prochaines étapes.
Pour ce benchmark, nous utilisons un ensemble de données de 310 incidents au sein de notre SOC MDR (Managed Detection and Response), chacun formaté comme une série d’événements JSON avec différents schémas et attributs en fonction du capteur servant à la récupération de données. Les données ont été transmises au modèle avec des instructions pour résumer ces dernières et un modèle prédéfini pour le processus de synthèse.

Figure 5 : Le modèle utilisé afin de transmettre les données pour tester la synthèse des incidents
Nous avons utilisé cinq mesures distinctes pour évaluer les synthèses générées par chaque modèle. Tout d’abord, nous avons vérifié que les descriptions d’incident générées étaient parvenues à extraire avec succès tous les détails pertinents des données brutes d’incident en les comparant aux synthèses “étalons (gold standard)” : à savoir des descriptions initialement générées à l’aide de GPT-4, puis améliorées et corrigées à l’aide d’un examen manuel mené par les analystes de Sophos.

Figure 6 : Cette description “gold standard” a été générée par GPT-4, puis examinée et modifiée manuellement par un analyste en menaces pour en vérifier l’exactitude.
Si les données extraites ne correspondaient pas complètement, nous mesurions l’écart entre tous les détails extraits des rapports générés manuellement en calculant la plus longue sous-séquence commune (Longest Common Subsequence) et la distance de Levenshtein pour chaque fait extrait des données d’incident, et en déduisant ensuite un score moyen pour chacun modèle. Nous avons également évalué les descriptions à l’aide de la méthode BERTScore, d’un score de similarité utilisant le modèle ADA2 d’OpenAI et de la méthode d’évaluation METEOR.
Résultats

Figure 7 : Un graphique montrant les résultats de référence/benchmark en matière de synthèse des incidents (Incident Summarization) pour les huit principaux LLM
GPT-4 s’impose encore une fois comme le grand gagnant, avec des performances nettement meilleures que les autres modèles dans tous les domaines. Mais GPT-4 a un avantage anticoncurrentiel dans certaines mesures qualitatives, en particulier celles basées sur l’intégration, car l’ensemble de référence utilisé pour l’évaluation a été développé avec l’aide de GPT-4 lui-même.
Les chiffres ne décrivent pas nécessairement le processus complet utilisé par les modèles pour synthétiser les événements. Pour mieux comprendre ce qui s’est passé avec chaque modèle, nous avons examiné les descriptions générées par ces derniers et les avons évaluées qualitativement (pour protéger les informations des clients, nous afficherons uniquement les deux premières sections de la synthèse de l’incident générée).
GPT-4 a fait un travail de synthèse respectable ; la synthèse était précise, bien qu’un peu trop détaillée. GPT-4 a également extrait correctement les techniques MITRE dans les données d’événement. Cependant, elle n’a pas mentionné l’indentation utilisée pour mettre en évidence la différence entre la technique MITRE et la tactique.

Figure 8 : Une synthèse générée automatiquement par une version ultérieure de GPT-4, avant examen manuel
Llama-70B a également extrait correctement tous les artefacts. Cependant, il est passé à côté d’un fait dans la synthèse (à savoir que le compte était verrouillé). Il n’est pas non plus parvenu à séparer la technique et la tactique MITRE dans la synthèse.

Figure 9 : Une synthèse générée par LlaMa-70b
J2-Ultra, en revanche, n’a pas si bien fonctionné. Il a répété la technique MITRE trois fois et est complètement passé à côté de la tactique. La synthèse semble cependant très concise et pertinente.
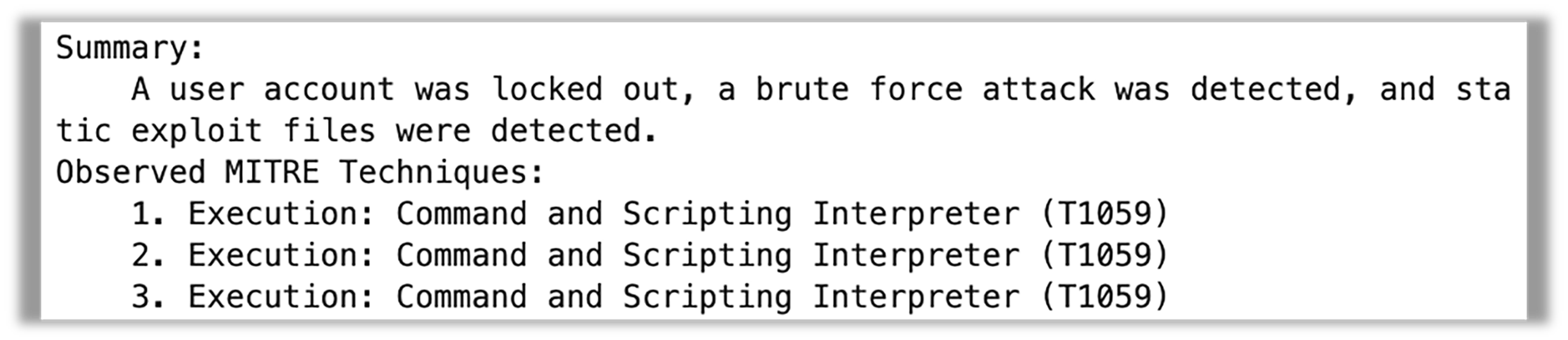
Figure 10 : Une synthèse générée par J2-Ultra
MPT-30B-Instruct ne parvient absolument pas à suivre le format et produit simplement un paragraphe résumant ce qu’il voit dans les données brutes.

Figure 11 : La synthèse (expurgée) des résultats générés par MPT-30B
Même si de nombreux faits extraits étaient exacts, le résultat s’est avéré bien moins utile que ne l’aurait été une synthèse organisée suivant le modèle attendu.
Le résultat de CodeLlaMa-34B était totalement inutilisable : il régurgitait les données d’événement au lieu de les synthétiser, et il “a halluciné” même partiellement certaines données.
Tâche 3 : Évaluation de la gravité des incidents (Incident Severity Evaluation)
La troisième tâche de référence/benchmark que nous avons évaluée était une version modifiée d’un problème ML-Sec traditionnel : à savoir, déterminer si un événement observé faisait partie d’une activité inoffensive ou d’une attaque. Chez SophosAI, nous utilisons des modèles ML spécialisés conçus pour évaluer des types spécifiques d’artefact d’événement tels que les fichiers PE (Portable Executable) et les lignes de commande.
Pour cette tâche, notre objectif était de déterminer si un LLM pouvait examiner une série d’événements de sécurité et évaluer leur niveau de gravité. Nous avons demandé aux modèles d’attribuer un score de gravité parmi cinq options possibles : Critique, Élevé, Moyen, Faible et Informationnel. Voici le format de prompt que nous avons fourni aux modèles pour cette tâche :

Figure 12 : La structure de prompt utilisée pour l’évaluation de la gravité de l’incident
Le prompt détaille la signification de chaque niveau de gravité et fournit les mêmes données de détection JSON que celles utilisées pour la tâche précédente. Étant donné que les données sur les événements étaient dérivées d’incidents réels, nous disposions à la fois de l’évaluation initiale de la gravité et du niveau de gravité final pour chaque cas. Nous avons évalué les performances de chaque modèle sur plus de 3 300 cas et mesuré les résultats.
Les performances de tous les LLM que nous avons testés ont été évaluées à l’aide de diverses configurations expérimentales, mais aucune d’entre elles n’a démontré des performances suffisantes, et meilleures que les hypothèses aléatoires. Nous avons mené des expériences avec un paramétrage zero-shot (indiqué en bleu) et un autre réglage à 3-shot (indiqué en jaune) en utilisant les voisins les plus proches, mais aucune des deux expériences n’a atteint un seuil de précision de 30 %.
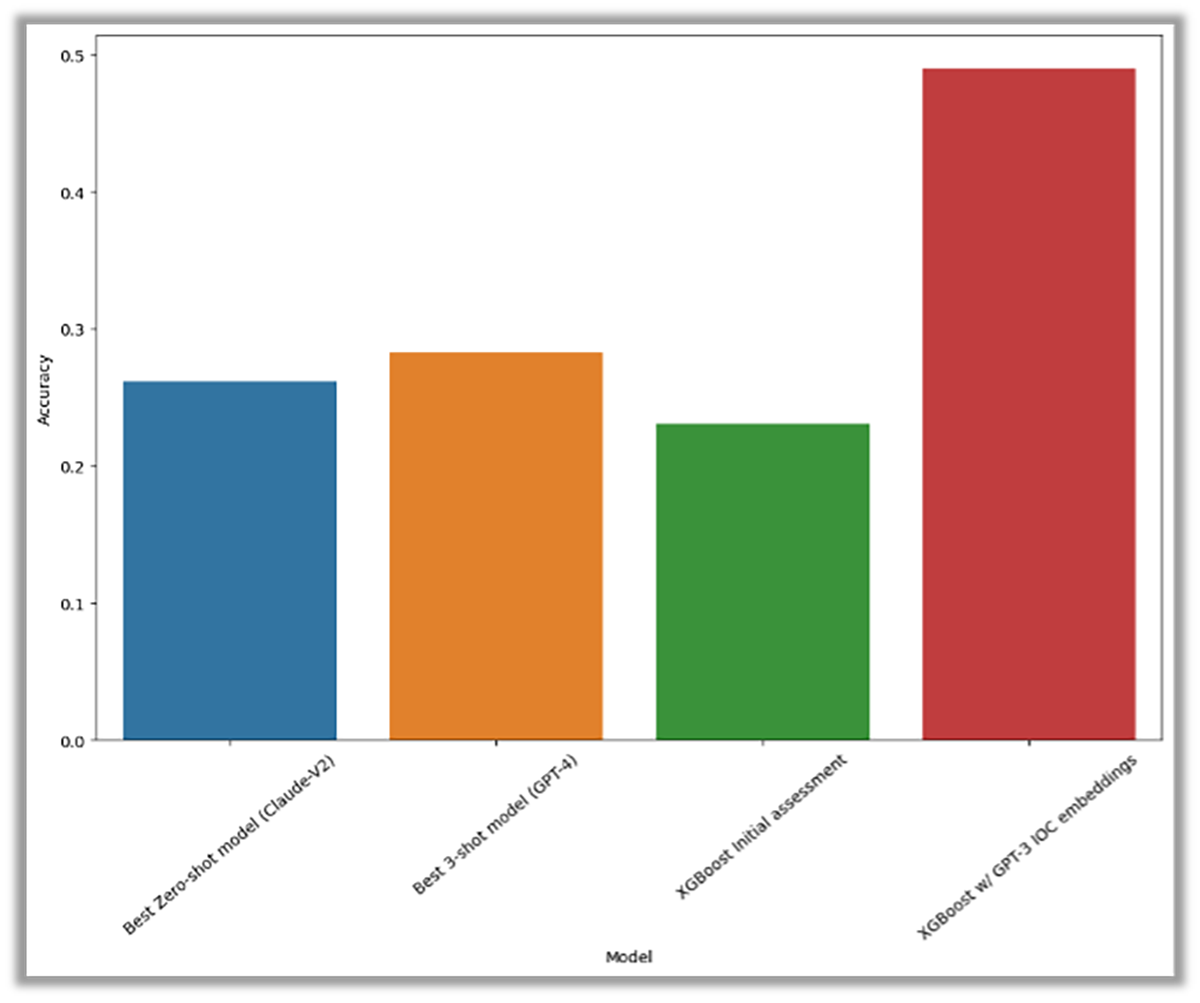
Figure 13 : Les meilleurs résultats du test de classification de la gravité
À titre de comparaison basique, nous avons utilisé un modèle XGBoost avec seulement deux fonctionnalités : la gravité initiale attribuée par les règles de détection de déclenchement et le type d’alerte. Cette performance est représentée par la barre verte.
De plus, nous avons expérimenté l’utilisation d’intégrations générées par GPT-3 aux données d’alerte (représentées par la barre rouge). Nous avons observé des améliorations significatives au niveau des performances, avec des taux de précision atteignant 50 %.
Nous avons constaté de manière générale que la plupart des modèles ne sont pas équipés pour effectuer ce genre de tâche, et ont souvent du mal à respecter le format. Nous avons constaté des comportements en termes d’échec plutôt amusants, notamment la génération d’instructions de prompt supplémentaires, la régurgitation des données de détection ou l’écriture de code qui produit un niveau de gravité en sortie au lieu de simplement produire un niveau à proprement parler.
Conclusion
Le fait de chercher à savoir quel modèle utiliser pour une application de sécurité débouche sur une problématique nuancée qui implique de nombreux facteurs différents. Ces benchmarks offrent des informations à prendre en compte pour amorcer la démarche, mais ne traitent pas nécessairement tous les problèmes potentiels.
Les grands modèles de langage sont efficaces pour faciliter la chasse aux menaces et l’investigation des incidents. Cependant, ils nécessiteront toujours des garde-fous et des conseils éclairés. Nous pensons que cette application potentielle peut être mise en œuvre à l’aide de LLM prêts à l’emploi, avec une ingénierie de prompt rigoureuse.
Lorsqu’il s’agit de synthétiser les informations sur les incidents à partir de données brutes, la plupart des LLM fonctionnent de manière adéquate, même s’il existe des possibilités d’amélioration grâce à des ajustements précis. Cependant, l’évaluation d’artefacts individuels ou de groupes d’artefacts reste une tâche difficile pour les LLM pré-entraînés et accessibles au public. Pour résoudre ce problème, un LLM spécialisé et entraîné spécifiquement avec des données de cybersécurité pourrait être nécessaire.
En termes de performances pures, nous avons constaté que GPT-4 et Claude v2 ont obtenu les meilleurs résultats dans tous les domaines au niveau de l’ensemble de nos benchmarks. Cependant, le modèle CodeLlama-34B obtient une mention spéciale pour ses bons résultats lors de la première tâche de référence/benchmark, et nous pensons qu’il s’agit d’un modèle compétitif pour un déploiement en tant qu’assistant SOC.
Billet inspiré de Benchmarking the Security Capabilities of Large Language Models, sur le Blog Sophos.