
Il s’agit plutôt d’une combinaison d’éléments “anciens, recyclés et nouveaux“. Prenons par exemple le malware de type document, il a passé des années en veille puis a refait surface en 2014 lorsque Dridex a utilisé des documents pour déployer sa charge virale, mais il reste toujours sur la liste des “plus recherchés” de l’équipe des SophosLabs, comme indiqué dans le rapport Sophos 2021 sur les menaces.
L’intelligence artificielle (IA) est capable d’apprendre, en quelques jours, des modèles à partir de millions d’échantillons de malwares, lui permettant ainsi de détecter à la fois les échantillons qu’elle a vus pendant l’entraînement et ceux qu’elle n’a pas vus. Néanmoins, au fil du temps, le paysage des menaces ne cessant d’évoluer, les échantillons rencontrés sur le terrain s’écarteront donc de ces modèles, ce qui nécessitera une mise à jour. L’entraînement des modèles à partir d’échantillons anciens et nouveaux fournit la meilleure détection, mais il est à la fois long et coûteux en calcul. Le raccourci tentant est d’entraîner le modèle uniquement à partir de nouveaux échantillons, mais malheureusement, comme c’est le cas dans la vraie vie, l’IA ne nous fera rarement de cadeaux. Le recyclage des anciens modèles à partir de nouveaux échantillons seuls les amènera à se mettre à jour de telle sorte qu’ils “oublieront” les échantillons plus anciens. Ce problème est un tel casse-tête qu’il existe même un nom pour le décrire : “l’oubli catastrophique (catastrophic forgetting)”.
Actuellement, la seule solution à l’oubli catastrophique est de recycler l’ensemble du réseau neuronal, ce qui prend environ une semaine et nécessite de disposer de tous les échantillons nouveaux et anciens. Dans le monde des cyberattaques en constante évolution, cela représente un “temps d’arrêt” trop important. Idéalement, les mises à jour pour découvrir de nouveaux malwares, sans perdre les anciens, devraient prendre environ une heure.
Vous trouverez ci-dessous un aperçu (basé sur les articles techniques détaillés d’Hillary Sanders, Catastrophic Forgetting, Part 1 et Catastrophic Forgetting, Part 2) résumant la manière avec laquelle SophosAI résout, pour les défenseurs, les problèmes de dégradation de la détection et des temps d’arrêt.
Analyse des différentes approches en matière d’Oubli Catastrophique (Catastrophic Forgetting)
L’IA offre aux éditeurs de sécurité l’opportunité de suivre les “éléments nouveaux”, mais doit être constamment mise à jour pour éviter une baisse significative des performances lorsque de nouveaux malwares modifient le paysage des menaces (comme le montre la figure 1).
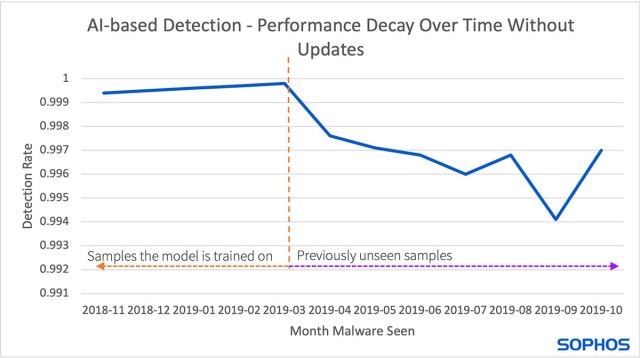
Figure 1 : Cette figure montre la dégradation des performances au fil du temps. Le modèle a été entraîné à partir d’échantillons à gauche de la ligne pointillée et fonctionne toujours correctement. À droite de la ligne pointillée se trouvent de nouveaux échantillons et les performances du modèle commencent à se dégrader.
La mise à jour des modèles nécessite la collecte de nouveaux échantillons, augmentant ainsi le coût du stockage des données et des heures de calcul pour l’entraînement des modèles (comme le montre la figure 2).
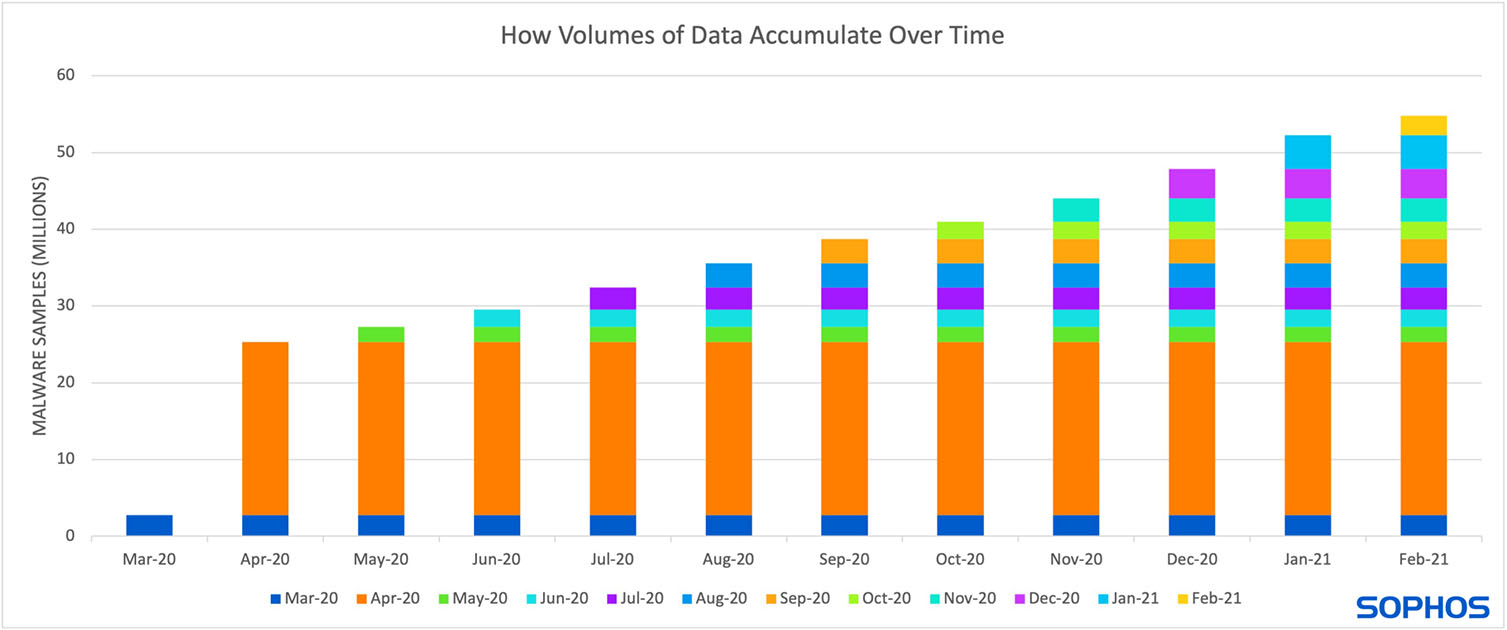
Figure 2 : Cette figure montre l’augmentation du stockage de données si les éditeurs collectent 25% des malwares publiés chaque mois, à partir de mars, afin d’entraîner un modèle à partir de zéro. Le nombre d’échantillons diffusés par mois est fourni par AVTest.
Pour réduire ces coûts et accélérer la rotation des modèles, il est courant d’affiner un modèle plutôt que d’en entraîner un nouveau à partir de zéro (comme le montre la figure 3). Cette approche signifie que le modèle existant est entraîné via des étapes supplémentaires uniquement concernant les nouveaux échantillons. À chaque étape, le modèle met à jour sa compréhension, permettant ainsi à celui-ci de se mettre à jour de manière à “oublier” les anciens modèles. C’est ce que les chercheurs appellent l’oubli catastrophique (catastrophic forgetting).
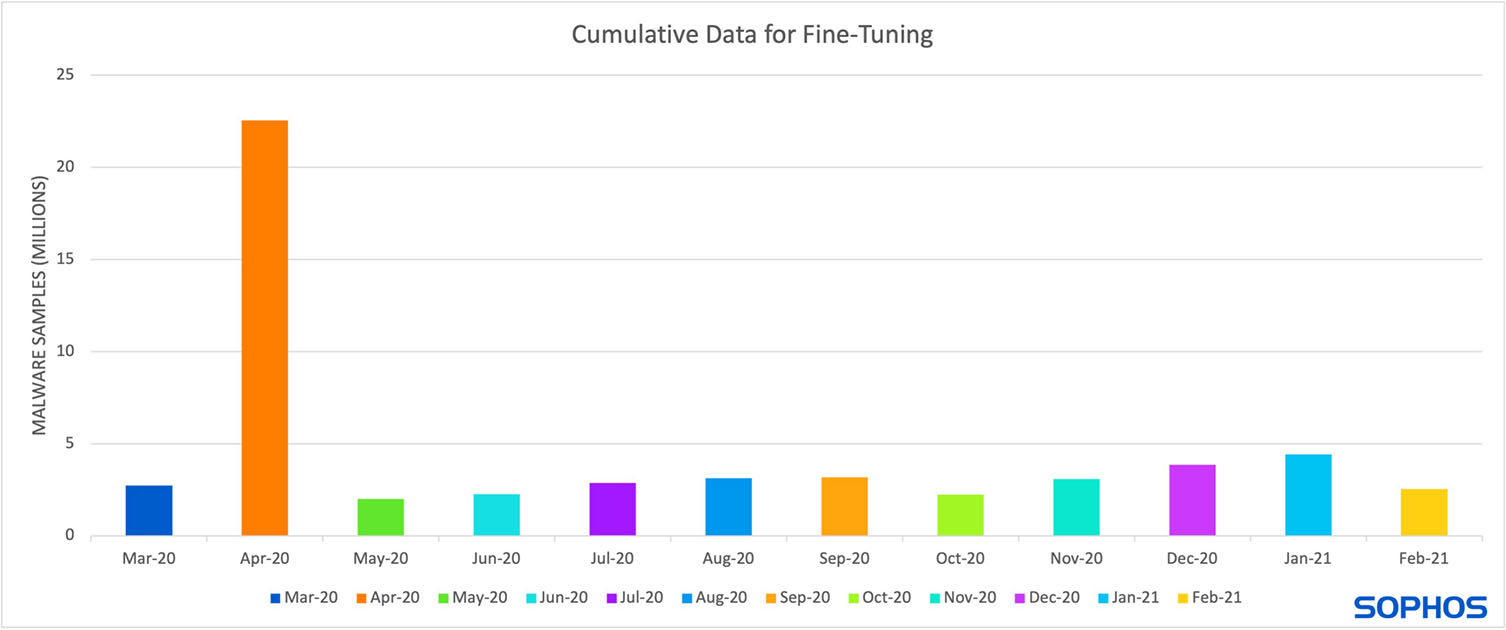
Figure 3 : Cette figure montre la capacité de stockage idéale en matière de données, si seuls de nouveaux échantillons étaient conservés. C’est la situation idéale, mais son déploiement n’est pas réaliste en raison de la dégradation des performances due à l’oubli catastrophique (catastrophic forgetting).
Comment SophosAI traite l’Oubli Catastrophique (Catastrophic Forgetting)
La chercheuse Hillary Sanders a évalué les performances du modèle par rapport à trois solutions potentielles pour traiter l’oubli catastrophique : (1) La répétition des données, ou modification des données exposées au modèle, (2) l’ajustement du taux d’apprentissage (3) et la modification des feedbacks envoyés au modèle après chaque phase d’entraînement.
La répétition des données
La répétition des données mélange une sélection d’anciens échantillons avec des nouveaux lors de l’ajustement du modèle. Cette approche “rappelle” au modèle les anciennes informations nécessaires pour détecter les échantillons plus anciens tout en lui apprenant à détecter les plus récents. L’inconvénient de cette approche est qu’elle nécessite une maintenance et un accès à certaines données plus anciennes, ce qui augmentera les coûts de stockage au fil du temps, bien qu’il s’agisse toujours d’une amélioration notable par rapport au stockage de l’intégralité des données passées.
Le pourcentage d’échantillons plus anciens conservés peut varier en fonction des performances souhaitées. Sanders a expérimenté différentes variations dans la proportion de nouveaux échantillons par rapport aux anciens lors de l’ajustement du modèle. Elle a trouvé un compromis entre (1) la performance sur des échantillons inconnus et (2) la performance sur d’anciens échantillons. Lorsque le pourcentage de nouveaux échantillons était supérieur à celui des anciens échantillons, le modèle fonctionnait mieux sur des échantillons inconnus mais moins bien sur des échantillons plus anciens, et vice versa.

Figure 4 : La figure ci-dessus montre les résultats de la répétition des données par rapport à l’ajustement (vert) et à l’entraînement à partir de zéro (bleu). La ligne grise utilise 50% d’échantillons plus récents et 50% plus anciens et fonctionne bien sur les mois antérieurs (à gauche de la ligne pointillée) et moins bien sur les mois postérieurs (à droite de la ligne pointillée). La ligne jaune utilise 75% d’échantillons plus récents et 25% plus anciens, tandis que la ligne orange utilise 90% d’échantillons plus récents et 10% plus anciens. Les deux fonctionnent mieux que l’approche 50/50 sur les échantillons plus récents.
Le taux d’apprentissage
La deuxième approche modifie la vitesse à laquelle le modèle apprend en ajustant le taux d’apprentissage : à savoir la quantité de données qu’un modèle peut modifier après avoir observé un échantillon donné. Un taux d’apprentissage trop élevé et le modèle ne “se souviendra” que des échantillons les plus récents qu’il a vus; un taux d’apprentissage trop faible et il faudra trop de temps pour un nouvel apprentissage. Cependant, en limitant le taux d’apprentissage, le modèle ne changera pas radicalement de sa forme d’origine, permettant ainsi une certaine mémorisation des modèles précédemment appris à partir de données plus anciennes. Néanmoins, cette approche limite également l’apprentissage de nouveaux modèles, ayant un impact négatif sur les taux de détection des nouveaux malwares.
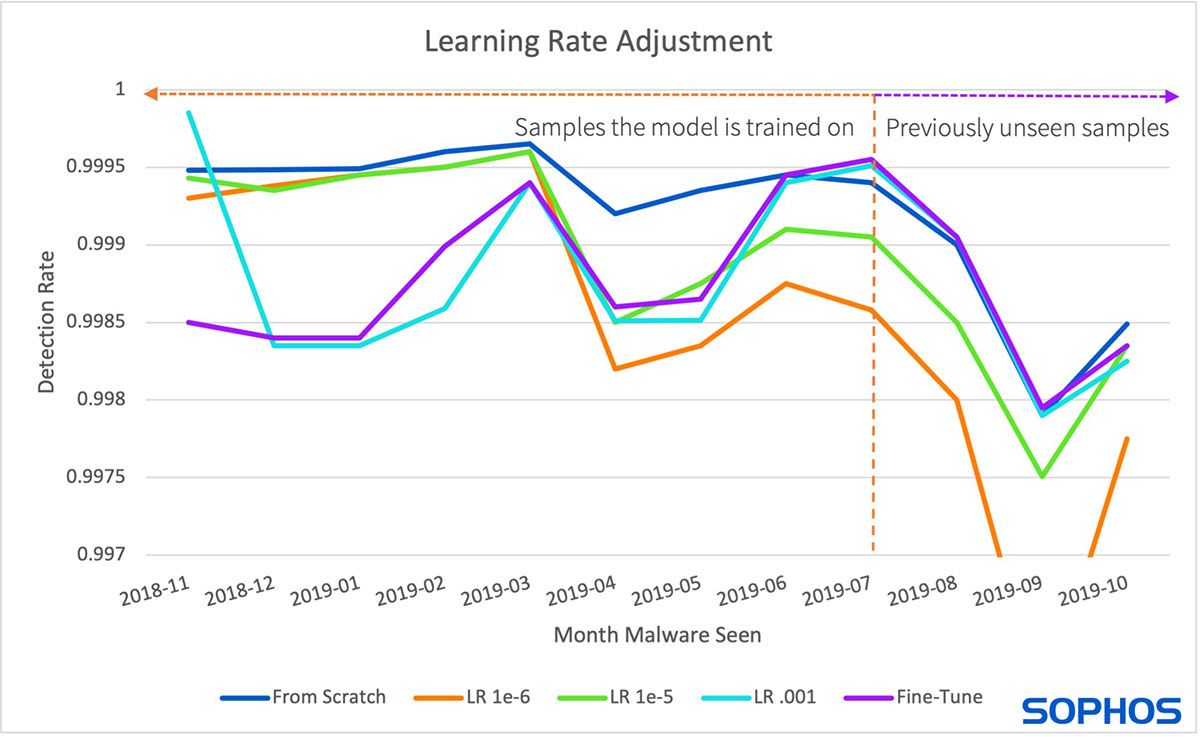
Figure 5 : La figure ci-dessus montre comment la modification du taux d’apprentissage influe sur les performances du modèle. Les deux taux d’apprentissage plus faibles fonctionnent bien sur les anciens malwares (à gauche de la ligne pointillée), mais sont relativement moins bons sur les nouveaux malwares (à droite de la ligne pointillée). Le taux d’apprentissage plus élevé fonctionne relativement moins bien sur les anciens malwares, mais mieux que les taux d’apprentissage plus faibles sur les nouveaux malwares.
La méthode EWC (Elastic Weight Consolidation)
Les travaux de Google DeepMind en 2017 abordent l’oubli catastrophique de manière académique et ont inspiré l’approche finale. À haut niveau, l’ancien modèle est utilisé pour maintenir le nouveau modèle connecté à la réalité. Si le nouveau modèle commence à “oublier”, l’ancien modèle agit comme un ressort et le ramène en arrière. Cette approche est appelée méthode EWC (Elastic-Weight Consolidation). Comme les modèles “du monde réel” ont tendance à être plus volumineux et entraînés sur un plus grand nombre de données, SophosAI a modifié la formulation originale pour mieux “ramener” le nouveau modèle en arrière lorsqu’il commence à oublier. Cette approche réduit les coûts de stockage des données car elle ne nécessite que des nouveaux échantillons.
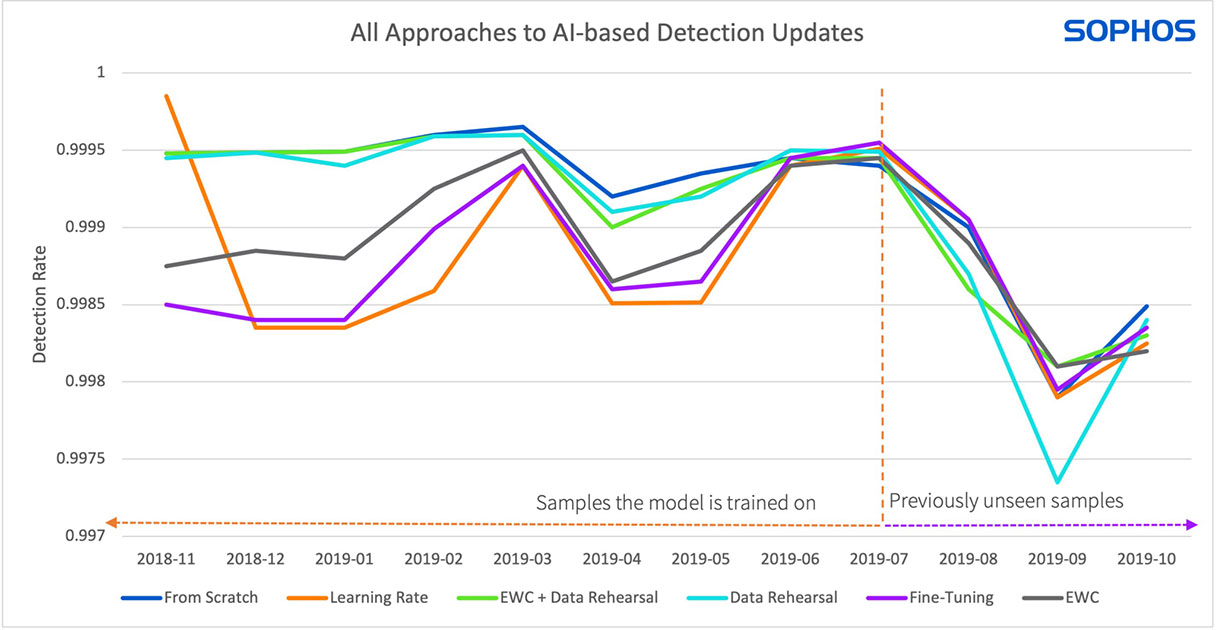
Figure 6 : La figure ci-dessus compare les trois approches. L’ajustement (vert), la méthode EWC (violet) et un taux d’apprentissage plus élevé (orange) ont donné les pires résultats sur les anciens échantillons de malwares (à gauche de la ligne pointillée), mais ont relativement bien fonctionné sur les échantillons les plus récents (à droite du pointillé doubler). La répétition des données seule (jaune) et combinée à l’EWC (gris) ont donné les meilleurs résultats sur les anciens échantillons par rapport aux autres approches.
Résultats
Lors de la comparaison de ces trois approches, il est important de considérer les compromis entre (1) les performances, (2) les coûts de calcul et (3) les coûts de maintenance des données. La méthode EWC et la modification du taux d’apprentissage ne nécessitent pas d’échantillons plus anciens, mais elles ne sont pas non plus les plus performantes. En parallèle, la répétition des données offre une meilleure performance par rapport à un modèle entraîné à partir de zéro sur des données anciennes et nouvelles. Cette approche réduit également le coût global en matière de calcul et de stockage des données. L’évaluation de Sanders a conclu que la répétition des données était la plus efficace pour Sophos en termes de taux de détection et de coût.

Figure 7 : Cette figure montre le nombre d’échantillons de malwares conservés à l’aide de la répétition des données avec 50% des échantillons de chaque mois précédent. Cette figure montre la diminution relative des besoins de stockage de données au fil du temps lorsque vous la comparez à la précédente Figure 2 de la collecte de données lors de l’entraînement d’un modèle à partir de zéro.
Pour découvrir de manière plus approfondie l’oubli catastrophique (catastrophic forgetting), parcourez les articles de blog d’Hillary Sanders : Catastrophic Forgetting, Part 1 et Catastrophic Forgetting, Part 2.
Pour en savoir plus sur SophosAI, suivez l’équipe SophosAI et son blog dédié.
Billet inspiré de Catastrophic Forgetting Explained, sur le Blog Sophos.