
Written by Sophos data scientists Madeline Schiappa and Ethan Rudd.
The ability to learn is considered one hallmark of intelligent life. Machine learning now has the ability to learn and extrapolate from data sets to accomplish sophisticated tasks like classifying previously unknown phenomena.
There are both surprising similarities and important differences in how machines learn vs. humans. By comparing and contrasting biological learning to artificial intelligence, we can build a more secure infrastructure.
Fun with neurons
Using biological neural networks, learning emerges from the interconnections between myriad neurons in the brain. The interconnections of these neurons change configuration as the brain is exposed to new stimuli. These changes include new connections, strengthening of existing connections and removal of unused connections. For example, the more one repeats a given task, the stronger the neurological connection is made, until that task is considered learned.
Neurons can process new stimuli by using pre-established representations from memory and perceptions based on the activation of a small set of neurons. For each stimulus, a different subset from a large pool of available neurons is activated during cognition.
This amazing design from biology has inspired data scientists when designing artificial intelligence models.
Artificial neural networks (ANN) aims to mimic this behavior in an abstract sense, but on a much smaller and simpler scale.
What is an Artificial Neural Network?
An ANN consists of layers made up of interconnected neurons that receive a set of inputs and a set of weights. It then does some mathematical manipulation and outputs the results as a set of “activations” that are similar to synapses in biological neurons. While ANNs typically consist of hundreds to maybe thousands of neurons, the biological neural network of the human brain consists of billions.
At the high level, a neural network consists of four components:
- neurons, of course
- topology – the connectivity path between neurons
- weights, and
- a learning algorithm.
Each of these components differ substantially between the biological neural networks of the human brain and the artificial neural networks expressed in software.
In the image below, we see a visualization of a biological neuron. The axon is responsible for output connections from the nucleus to other neurons. The dendritic tree receives input to the nucleus from other neurons. Electrochemical signals from neurons (synapses) are aggregated in the nucleus. If the aggregation surpasses a synaptic threshold, an electrochemical spike (synapse) propagates down the axon to dendrites of other neurons.
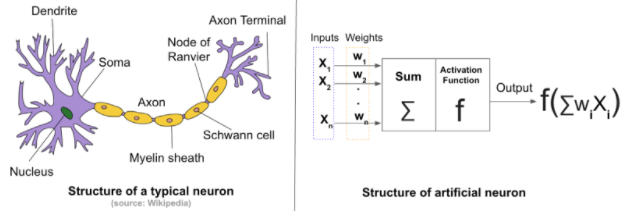 Image credit: Wikipedia
Image credit: Wikipedia
{kind=link}
Anatomy of a biological neural network
Biological neurons, depicted in schematic form in Figure 1, consist of a cell nucleus, which receives input from other neurons through a web of input terminals, or branches, called dendrites. The combination of dendrites is often referred to as a “dendritic tree”, which receives excitatory or inhibitory signals from other neurons via an electrochemical exchange of neurotransmitters.
The magnitude of the input signals, that reach the cell nucleus depends both on the amplitude of the action potentials propagating from the previous neuron and on the conductivity of the ion channels feeding into the dendrites. The ion channels are responsible for the flow of electrical signals passing through the neuron’s membrane.
More frequent or larger magnitude input signals generally result in better conductivity ion channels, or easier signal propagation. Depending on this signal aggregated from all synapses from the dendritic tree, the neuron is either “activated” or “inhibited”, or in other words, switched “on” or switched “off”, after a process called neural summation. The neuron has an electrochemical threshold, analogous to an activation function in artificial neural networks, which governs whether the accumulated information is enough to “activate” the neuron.
The final result is then fed into other neurons and the process begins again.
Below we see a simplified schematic illustration of plausible neuronal topologies in the human brain. Note the enormous potential for loops and neurons feeding back into one another.
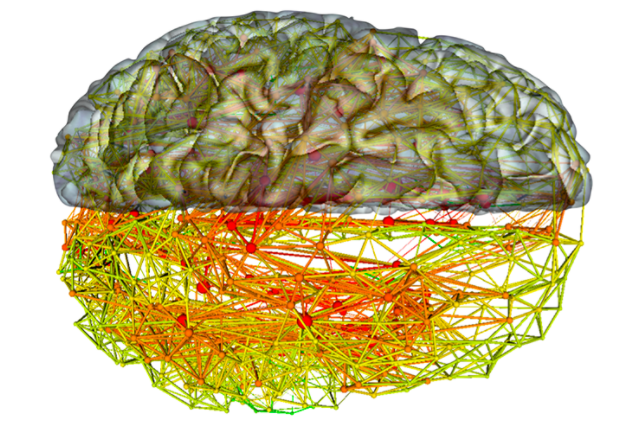 Image credit: Quanta Magazine
Image credit: Quanta Magazine
Learning in Biological Networks
In biological neural networks like the human brain, learning is achieved by making small tweaks to an existing representation – its configuration contains significant information before any learning is conducted. The strengths of connections between neurons, or weights, do not start as random, nor does the structure of the connections, i.e., the network topology. This initial state is, in part, genetically derived, and is the byproduct of evolution.
Over time, the network learns how to perform new functions by adjusting both topology and weights. The fact that there is an initial representation that works well for many tasks is supported by research, which suggests that as young as one month old newborns are able to recognize faces demonstrated by their learning to differentiate between strangers and their parents.n other words, the concept of a human face has largely been passed down genetically from parent to child.
As babies develop and progress through childhood, adolescence, adulthood, and even retirement years, they will see and meet new people every day and must learn what they look like. This is achieved by making minor alterations to the neural networks residing in their brains.
The same phenomenon applies to other tasks as well – both passive sensory tasks, from recognizing generic objects to processing sound as speech patterns, to active tasks like movement and speech. These skills are learned gradually, and progressively smaller tweaks are used to refine them. The precise topologies are a function of the types of stimuli upon which these biological neural networks are trained. A prominent example is the monocular deprivation studies led by David Hubel and Torsten Wiesel. The study involved forcing an animal’s eye shut for two months during development and observing the changes to their primary visual cortex.
The results showed that cells that are normally responsive to input from both eyes, were no longer receptive at all. Both the cells in their brain and in their eye had changed as a result. This phenomenon extends to humans. For example, psychometric tests on visual perception indicates that people who have spent much of their lifetimes in cities tend to be more sensitive to parallel lines and sharp gradients than people from rural environments, who are more sensitive to smooth texture gradients, likely the result of an over-abundance of parallel structures of roads, skyscrapers, and windows.
Learning in Artificial Neural Networks
Unlike Biological Neural Networks, Artificial Neural Networks (ANNs), are commonly trained from scratch, using a fixed topology chosen for the problem at hand. At present, their topologies do not change over time and weights are randomly initialized and adjusted via an optimization algorithm to map aggregations of input stimuli to a desired output function. However, ANNs can also learn based on a pre-existing representation. This process is called fine-tuning and consists of adjusting the weights from a pre-trained network topology at a relatively slow learning rate to perform well on newly supplied input training data.
We can also effortlessly replicate ANNs, but we have a while to go before we can do that for a human brain.
Whether training from scratch or fine-tuning, the weight update process begins by passing data through the neural network, measuring the outcome, and modifying the weights accordingly. This overall process is how an artificial neural network “learns”. Weights are gradually pushed in the directions that most increase performance of the desired task, e.g., maximizing recognition accuracy, on the input samples. This notion of learning can be likened to a child trying to learn how to recognize everyday objects. After failed attempts and feedback on the accuracy of the answer, the child tries again in a different direction to achieve the correct response. An ANN performs the same task when learning. It is fed stimuli that have known responses and a learning regime adjusts weights so as to maximize the number of accurate responses that result from feeding the ANN new stimuli.
Once this learning process is complete, both the child and the ANN can use their previous representations of the problems to craft responses to new stimuli that they have not previously been exposed to in the learning process. The child learns best via exposure to as many similar problems as possible. The more problems the child practices, the quicker he or she becomes at tackling new problems, because relevant neuronal connections in the child’s brain become more defined. An ANN is similar in that with more exposure to the wide distribution of possible stimuli for the task in question, the better the ANN can learn to respond to new stimuli from the same distribution that it was not previously exposed to.
Broad Exposure is Good
We have long known in humans that the more children are exposed to the world the better they learn, even if this learning is sometimes painful. In fact,when learning is painful the pain serves as a sharp feedback mechanism. Similarly, exposing ANNs to a wide variety of stimuli in a particular domain is extremely important to train or fine-tune a neural network, of any kind, and can ensure you are not over-fitting a model to one kind of stimulus.
With additional representations of a particular class of stimuli, the better a network can classify new stimuli, or generalize a concept. This holds for both biological neural networks and artificial neural networks, although biological neural networks do a much better job of generalizing. This is true in part because they are exposed to vastly more types and modalities of data in part because of more advanced biological topologies and learning algorithms, and in great part because of Darwinism.
An example of this is rooted in the Black Swan Theory developed by Nassim Taleb. The terminology comes from a common expression in 16th century London stating that all swans are white because there has been no documented occurrence of any other colored swan. Therefore, to them a swan must be white to be classified as a swan. Later on however, a Dutch explorer by the name of Willem de Vlamingh later witnessed black swans in Western Australia changing that strict classification.
The idea here is that if one has grown up seeing only white swans, i.e., one’s neural network was trained only on a distribution where all swans were white, and is then presented with a “black swan”, one may not classify it as a swan because one has never seen otherwise. If one had grown up seeing swans of both colors, then one would be more apt at classifying all swan types, due to a biological neural network “trained” on a larger distribution of swan types with more knowledge about the many possible attributes a swan can and cannot have.
Generalization, or the ability to abstract knowledge from what one has previously learned, is an extremely useful capability that allows problem solving across different domains quickly via minor weight adjustment – a process called fine tuning – which is a neural network’s solution to transfer learning and domain adaptation problems. The fact that not so many neuronal connections require re-wiring is one reason why, on average, avid skiers are far-quicker to pick up snowboarding than first-time snowboarders, or why an artificial neural network that is trained for object detection then fine-tuned for face recognition will often arrive at a better solution than one trained strictly, from scratch, on the same face recognition dataset.
Man vs Machine
It should be clear that today’s artificial neural networks are still in their infancy. While analogous in structure, with respect to notions of weights, neurons (functional units), topology, and learning algorithms, they are not yet capable of mimicking the human brain for many classes of complex tasks. Their topologies are far simpler, they are orders of magnitude smaller, and learning algorithms are comparatively naive. Moreover, they cannot yet be trained to work well for many heterogeneous tasks simultaneously.
As we continue to build ANNs to solve hard problems,such as detecting previously unknown types of malware, we continue to also learn more about how the human brain accomplishes tasks.or certain classes of tasks, ANNs can actually outperform human analysts, both in terms of accuracy and in terms of speed. Action potentials in the brain propagate in thousandths of seconds; while ANNs can classify data orders of magnitudes faster.
For other tasks, the strengths of ANNs supplement and augment the capabilities of even the best human minds automating large workflows.
In the near future, ANNs will begin to perform additional classes of tasks at near-human and even superhuman levels, perhaps becoming mathematically and structurally more similar to biological neural networks.
Stuart L Kupferman
Thank you for your article. I am just starting to learn about neural networks was a very helpful overview,
Stu Kupferman
Chad
Two words should be added to the end of your excellent article : “…or not.”