
Computing capacity and deep learning methodology have advanced rapidly in the past decade.
We’ve started to see computers using these techniques to perform ever more historically human-centric tasks, faster and often better than humans.
At Sophos we believe this extends to cybersecurity. Specifically, our data science team specializes in developing deep learning models that can detect malware with extremely high detection rates and very low false positives.
But, instead of preaching about the benefits of deep learning, let’s talk about a big challenge we face when applying machine learning to cybersecurity: uncertain labels.
The problem with labels
Supervised machine learning works like this: you give a model (a function) some data (like some HTML files) and a bunch of associated desired output labels (like 0 and 1 to denote benign and malicious). The model looks at the HTML files, looks at the available labels 0 and 1 and then tries to adjust itself to fit the data so that it can correctly guess output labels (0,1) by only looking at input data (HTML files).
Long story short: we define the ground truth for the model by telling it that “this is the perfectly accurate state of the world, now learn from it so you can accurately guess labels from new data”.
The problem is, sometimes the labels we’re giving our models aren’t correct. Perhaps it’s a new type of malware that our systems have never seen before and hasn’t been flagged properly in our training data. Perhaps it’s a file that the entire security community has cumulatively mislabeled through a snowball effect of copying each other’s classifications.
The concern is that our model will fit to this slightly mislabeled data and we’ll end up with a model that predicts incorrect labels.
To top it off, we won’t be able to estimate our errors properly because we’ll be evaluating our model with incorrect labels. The validity of this concern is dependent on a couple of factors:
- The amount of incorrect labels you have in your dataset
- The complexity of your model
- If incorrect labels are randomly distributed across the data or highly clustered
To understand each of these better, let’s first create an example, where the universe is simple and the maliciousness of an HTML file is entirely dependent on the relationship between two toy features: HTML file length and the number of links in an HTML file (if only it were this easy!). In our plots below, “x”s represent malicious HTML files, and “o”s represent benign files:
To understand each of these better, we’ve simplified the maliciousness of an HTML down to just two example factors, HTML file length and the number of links in an HTML file (if only it were this easy!). In our plots below, “x”s represent malicious HTML files and “o”s represent benign files:

Let’s say we train a very simple, low complexity, linear model on our data to create a decision boundary between our training points (image 1). What happens when we add a single misclassified point to our training data (image 2)?
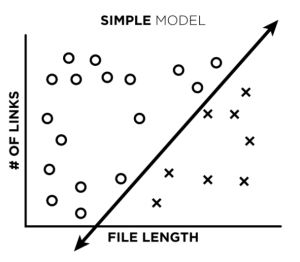 Image 1
Image 1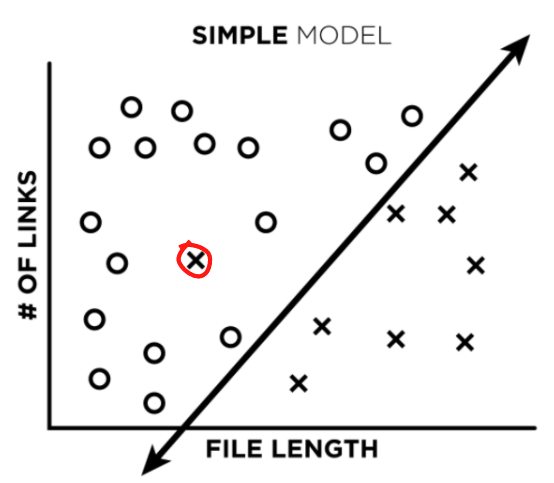 Image 2
Image 2
Not much, really. The line might shift a little, but not a lot. After training, if we ask our model to classify that same misclassified point, it will actually predict the correct label instead of the incorrect one. Great!
What happens, though, if our model is allowed to fit to complex patterns? It can fit beautifully to actual complex patterns (image 3), but it can also end up fitting to mislabeled data (image 4):
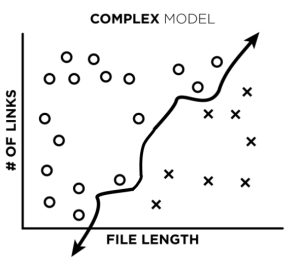 Image 3
Image 3 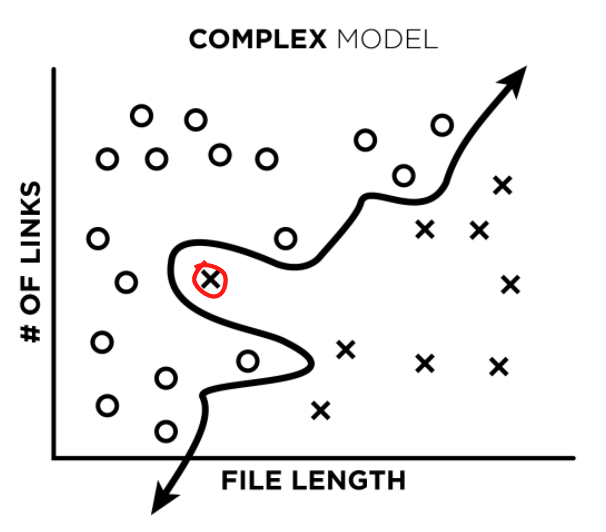 Image 4
Image 4
Now, if we ask our trained complex model to classify the mislabeled data point, our model would give us the incorrect label (the label we taught it).
But, for cybersecurity machine learning, we need complex models, at least to a certain extent.
In real life, classifying HTML files is done on hundreds or thousands of interacting, learned features. This makes us more vulnerable to misclassified training labels.
Now let’s up the ante. What happens when we have more data, but also a lot more mislabeled observations?
Well, if our mislabeled observations are relatively randomly distributed and our model isn’t extremely complex (and trained so as not to overfit to single data points), we’ll still probably do quite well. If an incorrectly labeled data point is surrounded by correctly labeled ones, then the good signal will outweigh the bad.

If we turn around and ask the model to predict the labels of these or very similar misclassified points it saw during training, it will actually guess the correct label. Fantastic!
The real danger, though, is when there are clusters of mislabeled observations. When bad labels are clustered, there are enough incorrect labels to outweigh the good and our model will learn the wrong (green) decision boundary: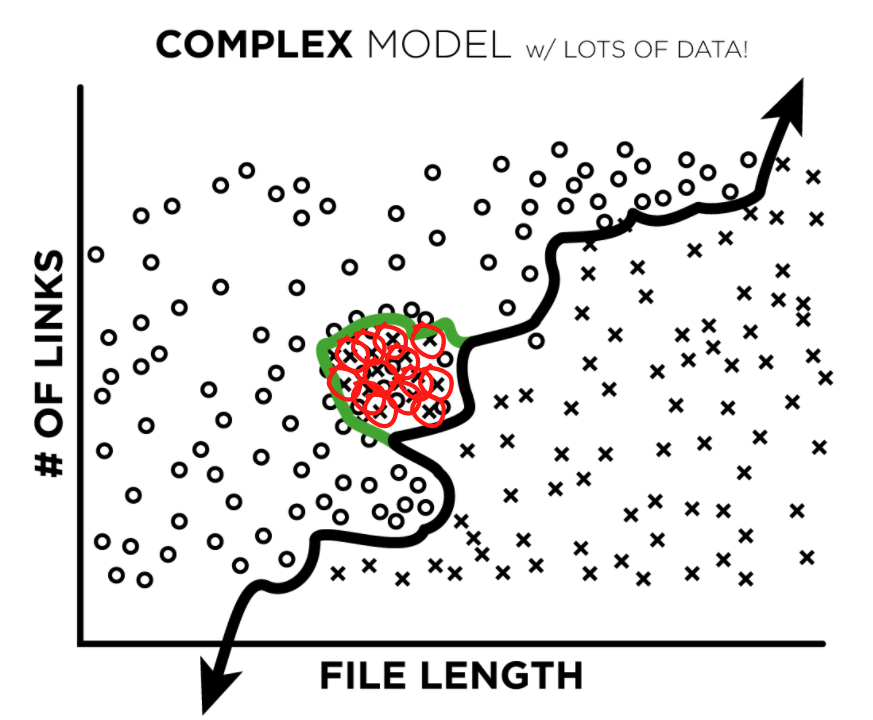
In cybersecurity machine learning, it is both important and difficult to make sure this doesn’t happen! If, for example, an entire class of malware is mislabeled in our training and testing data, it’s very difficult to ever realize that our model is misclassifying points without an independent analysis of the data.
What to do?
At the Sophos data science team, we primarily focus on detecting malware via deep neural networks. We do a few things to try to minimize the amount and effects of bad labels in our data.
First, we simply try to use good data. We only use malware samples that have been verified as inherently malicious by our systems (sandboxes, etc.) or those that have been flagged as malicious by multiple vendors. However, bad labels still slip through the cracks.
We also make sure not to overtrain, and thus overfit, our models. The goal is to be able to detect never-before-seen malware samples, by looking at similarities between new files and old files, rather than just mimic existing lists of known malware.
Memorizing what a single file looks like isn’t as useful as learning flexible features across many files that are associated with malware. This approach helps us create models that generalize better and are also less likely to overfit to bad labels.
Next, we attempt to improve our labels by analyzing false positives and false negatives found during model testing. In other words, we take a look at the files that we think our model misclassified (like the red circled file in the plot below), and make sure it actually misclassified them. What’s really cool, is that very often – our labels were wrong, and the model was right. So our models can actually act as a data-cleaning tool.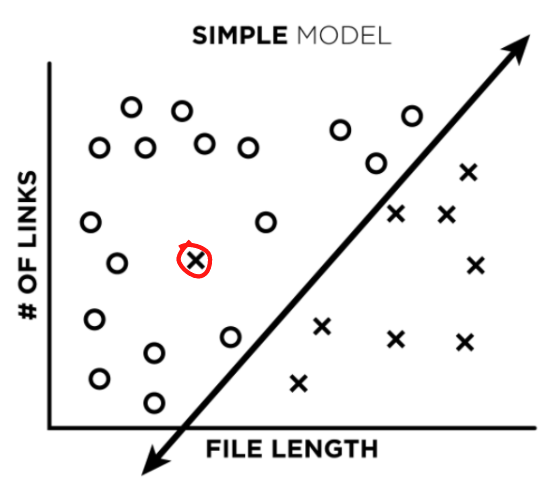
‘Dirty labels’ are just one of many tricky challenges we face when building machine learning models. Deep learning is extremely powerful, but it’s not an instant magic bullet. Implementing deep learning systems is a delicate process that can yield amazing results when done properly.
This is why our team of data scientists working hand in hand with threat researchers in Sophos Labs to ensure we are constantly improving the data we use and the machine learning models we create.
Leave a Reply