
** 本記事は、DeepSpeed: a tuning tool for large language models の翻訳です。最新の情報は英語記事をご覧ください。**
大規模言語モデル (LLM) は、サイバーセキュリティアナリストやインシデント対応者のワークロードを含む多様なワークロードを自動化し、軽減する可能性を秘めています。しかし、一般的な LLM には、これらのタスクを適切に処理するために必要なドメイン特化型の知識が欠けています。LLM は、サイバーセキュリティ関連のリソースを含む学習データを使用して構築されているかもしれませんが、場合によっては独自の知識を必要とする (LLM が学習した時点では得られなかった最新の)、より専門的なタスクを担当するには不十分なことも少なくありません。
「ストック」(特化されていない) LLM を特定のタスク向けにチューニングするための既存のソリューションはいくつかあります。しかし残念ながら、これらのソリューションは Sophos X-Ops への実装を試みる LLM としては不十分でした。そこで SophosAI は、Microsoft が開発したライブラリ DeepSpeed を利用するフレームワークを構築しました。DeepSpeed は、学習時に使用する計算能力とグラフィックプロセッシングユニット (GPU) の数をスケールアップすることで、(理論的には) 数兆個のパラメータを持つモデルの学習と推論のチューニングに使用できます。このフレームワークはオープンソースライセンスであり、ソフォスの GitHub リポジトリで公開されています。
フレームワークの多くの部分は既存のオープンソースライブラリを活用しており、目新しいものではありませんが、SophosAI はいくつかの主要なコンポーネントを扱いやすいよう統合しています。また、フレームワークのパフォーマンス向上にも継続的に取り組んでいます。
(不十分な) 代替案
ストック LLM をドメイン特化型の知識に適合させるためのアプローチはすでに複数あります。それぞれに利点と限界があります。
| アプローチ | 使用される手法 | 限界 |
| 検索拡張生成 (RAG) |
|
|
| 継続的な学習 |
|
|
| パラメータの効率的な微調整 |
|
|
ドメイン特化型 LLM の効果を最大限に発揮させるには、すべてのパラメータを事前に学習し、企業独自の知識を学習させる必要があります。この作業はリソースを大量に消費し、時間もかかるため、ソフォスは DeepSpeed という学習フレームワークを Python で実装し、使用することにしました。ソフォスがオープンソースとして公開しているフレームワークのバージョンは Amazon Web Services の SageMaker 機械学習サービスのみならず、他の環境にも適応できます。
学習フレームワーク (DeepSpeed を含む) では、並列処理によって大規模なモデル学習タスクをスケールアップできます。並列処理には大きく分けてデータ、テンソル、パイプラインの 3 種類があります。
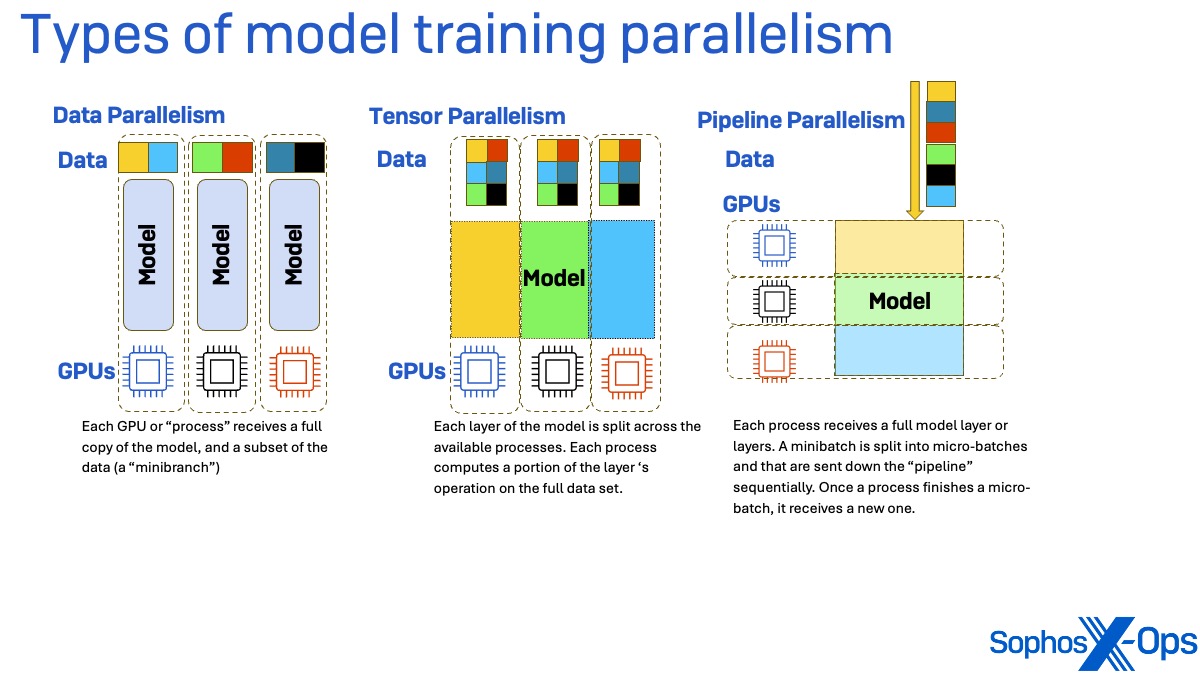
データ並列処理では、学習タスクに取り組む各プロセス (通常は各グラフィックスプロセッサユニット GPU)) は、モデル全体の重みを受け取る一方、ミニバッチと呼ばれるデータのサブセットのみを受け取ります。データのフォワードパス (損失、つまり学習に使用するモデルのパラメータの不正確さの度合いを計算) とバックワードパス (損失の勾配を計算) が完了すると、結果の勾配が同期されます。
テンソル並列処理では、学習に使用されるモデルの各レイヤーが利用可能なプロセスに分割されます。各プロセスは、完全な学習データセットを使用して、レイヤーの演算の一部を計算します。これらの各レイヤーからの部分出力はプロセス間で同期され、単一の出力行列が作成されます。
パイプライン並列では、モデルの分割方法が異なります。モデルのレイヤーを分割して並列化するのではなく、モデルの各レイヤーが独自のプロセスを受け取ります。データのミニバッチはマイクロバッチに変換され、「パイプライン」を順次下っていきます。あるプロセスがマイクロバッチの処理を完了すると、新しいマイクロバッチを受け取ります。この方法では、プロセスがアイドル状態になり、それ以前のレイヤーをホストするプロセスの出力を待つ「バブル」が発生する可能性があります。
これら 3 種類の並列化手法は、いくつかの方法で組み合わせることも可能であり、DeepSpeed 学習ライブラリでは実際に組み合わされています。
DeepSpeed での学習
DeepSpeed はシャード化データ並列処理を行います。各モデルレイヤーは、各プロセスがスライスを取得するように分割され、各プロセスには入力として個別のミニバッチが与えられます。フォワードパスの間、各プロセスはレイヤーのスライスを他のプロセスと共有します。このやり取りが終わると、各プロセスは完全なモデルレイヤーのコピーを所持することになります。
各プロセスは、そのミニバッチのレイヤー出力を計算します。与えられたレイヤーとミニバッチの計算を終えると、プロセスはもともと保持していなかったレイヤーの部分を破棄します。
学習データのバックワードパスも同様に行われます。データ並列処理と同様に、勾配はバックワードパスの最後に累積され、プロセス間で同期されます。
学習プロセスは、処理能力よりもメモリによる性能の制約を強く受けます。GPU 自身のメモリでは大きすぎるバッチを処理するために追加メモリを搭載した GPU を増設すると、GPU 間の通信速度や、プロセスの実行に必要なプロセッサ数よりも多くのプロセッサを使用するコストが発生するため、パフォーマンスコストが格段に大きくなる可能性があります。DeepSpeed ライブラリの重要な要素の 1 つは Zero Redundancy Optimizer (ZeRO) です。ZeRO は、非常に大規模な言語モデルの学習を効率的に並列化できる一連のメモリ利用技術です。ZeRO は、モデルの状態 (オプティマイザ、勾配、パラメータ) を各プロセス間で重複させるのではなく、並列化されたデータプロセス間で分割することにより、各 GPU のメモリ消費量を削減します。
その重要なポイントは、計算予算に合った学習アプローチと最適化の組み合わせを見つけることです。ZeRO は 3 つのパーティショニングステージから選択できます。
- ZeRO ステージ 1 は、オプティマイザの状態をシャードします。
- ZeRO ステージ 2 は、オプティマイザと勾配を分割します。
- ZeRO ステージ 3 は、オプティマイザと勾配とモデルの重みを分割します。
各ステージには、それぞれ相対的な利点があります。たとえば、ZeRO ステージ 1 はより高速ですが、ステージ 2 やステージ 3 より多くのメモリを必要とします。 さらに、DeepSpeed ツールキットには、2 つの異なる推論アプローチがあります。
- DeepSpeed 推論: カーネルインジェクションなどの最適化を施した推論エンジン。レイテンシが小さくなりますが、より多くのメモリを必要とします。
- ZeRO 推論: 推論中にパラメータを CPU または NVMe メモリにオフロードできます。レイテンシは高くなりますが、GPU メモリの消費は少なくなります。
ソフォスの貢献
Sophos AI チームは、Deep Speed をベースにしたツールキットを作成し、DeepSpeed を利用する際の手間を軽減しています。ツールキットのパーツ自体に目新しさはありませんが、新しいのは、いくつかの主要コンポーネントが扱いやすいように統合されているという利便性の高さです。
作成当時、このツールリポジトリは、学習と 2 つの DeepSpeed 推論タイプ (DeepSpeed 推論と ZeRO 推論) を初めて 1 つの設定可能なスクリプトにまとめたものでした。また、Amazon Web Service の SageMaker 上で最新の DeepSpeed バージョンを実行するためのカスタムコンテナを作成した最初のリポジトリでもあります。さらに、SageMaker 上でエンドポイントとして実行されない分散スクリプトベースの DeepSpeed 推論を実行した最初のリポジトリです。現在サポートされている学習方法には、継続的な事前学習、教師ありの微調整、そして最終的な好みの最適化があります。
リポジトリとドキュメントは、hereソフォスの GitHub で公開されています。