
La détection d’anomalies en cybersécurité promet depuis longtemps l’identification des menaces en mettant en évidence les écarts par rapport au comportement attendu. Cependant, lorsqu’il s’agit d’identifier des commandes malveillantes, son utilisation pratique entraîne souvent des taux élevés de faux positifs, la rendant ainsi coûteuse et inefficace. Mais avec les récentes innovations en matière d’IA, existe-t-il de nouveaux espaces que nous pouvons encore explorer ?
Lors de la conférence Black Hat USA 2025, nous avons présenté nos recherches sur le développement d’un pipeline qui ne dépend pas de la détection d’anomalies comme point de défaillance. En combinant la détection d’anomalies avec de grands modèles de langage (LLM : Large Language Models), nous pouvons identifier en toute confiance les données critiques qui peuvent être utilisées pour renforcer un classificateur de ligne de commande dédié.
L’utilisation de la détection d’anomalies, pour alimenter un autre processus, évite les taux de faux positifs potentiellement catastrophiques générés par une méthode non supervisée. À la place, nous apportons des améliorations au sein d’un modèle supervisé ciblant la classification.
De manière inattendue, le succès de cette méthode ne dépendait pas de la détection d’anomalies identifiant des lignes de commande malveillantes. Au lieu de cela, la détection d’anomalies, associée à l’étiquetage (labeling) basé sur les LLM, produit un ensemble remarquablement diversifié de lignes de commande bénignes. L’exploitation de ces données inoffensives lors de l’entraînement des classificateurs de ligne de commande réduit considérablement les taux de faux positifs. De plus, cela nous permet d’utiliser de nombreuses données existantes sans avoir à nous soucier de ces fameuses “aiguilles dans une botte de foin” que sont, en réalité, les lignes de commande malveillantes dans les données de production.
Dans cet article, nous explorerons la méthodologie utilisée lors de notre expérimentation, en soulignant comment diverses données bénignes identifiées grâce à la détection d’anomalies élargissent la compréhension du classificateur et contribuent à créer un système de détection plus résilient.
En passant de la seule recherche d’anomalies malveillantes à l’exploitation d’une diversité inoffensive au sens large, nous proposons un changement de paradigme potentiel dans les stratégies de classification de ligne de commande.
Une approche fondamentalement nouvelle
Les professionnels de la cybersécurité doivent généralement trouver un équilibre entre des ensembles de données étiquetés coûteux et des détections assez ‘bruyantes’ et non supervisées. L’étiquetage bénin traditionnel se concentre sur les comportements inoffensifs fréquemment observés et de faible complexité, car cela est facile à réaliser à grande échelle, excluant par inadvertance les commandes bénignes rares et compliquées. Cet écart incite les classificateurs à considérer à tort des commandes sophistiquées et inoffensives comme malveillantes, augmentant ainsi les taux de faux positifs.
Les progrès récents dans les LLM ont permis un étiquetage très précis basé sur l’IA à grande échelle. Nous avons testé cette hypothèse en étiquetant les anomalies détectées dans la télémétrie de production réelle (plus de 50 millions de commandes quotidiennes), obtenant ainsi une précision quasi parfaite au niveau des anomalies bénignes. En utilisant explicitement la détection d’anomalies pour améliorer la couverture des données inoffensives, notre objectif était de changer le rôle de la détection d’anomalies, en passant de l’identification erratique des comportements malveillants à la mise en évidence fiable d’une diversité inoffensive. Cette approche est fondamentalement nouvelle, car la détection d’anomalies privilégie traditionnellement les détections malveillantes plutôt que l’amélioration de la diversité des étiquettes bénignes.
En utilisant la détection d’anomalies associée à un étiquetage inoffensif automatisé et fiable à partir de LLM avancés, en particulier le modèle o3-mini d’OpenAI, nous avons augmenté les classificateurs supervisés et considérablement amélioré leurs performances.
Comment avons-nous procédé ?
Collecte de données et fonctionnalisation
Nous avons comparé deux implémentations distinctes de collecte et de caractérisation de données au cours du mois de janvier 2025, en utilisant chaque implémentation quotidiennement afin d’évaluer les performances sur une période de temps représentative.
Mise en œuvre à grande échelle/full-scale (toutes les télémétries disponibles)
La première méthode fonctionnait sur la télémétrie quotidienne complète de Sophos, qui comprenait environ 50 millions de lignes de commande uniques par jour. Cette méthode nécessitait un déploiement de l’infrastructure à l’aide de clusters Apache Spark et une mise en œuvre automatisée via AWS SageMaker.
Les caractéristiques de l’approche à grande échelle (full-scale) reposaient principalement sur une ingénierie manuelle spécifique au domaine. Nous avons calculé plusieurs fonctionnalités descriptives de la ligne de commande :
- Les fonctionnalités basées sur l’entropie mesurent la complexité et le caractère aléatoire des commandes.
- Les fonctionnalités au niveau des caractères encodaient la présence de caractères spécifiques et de jetons spéciaux.
- Les fonctionnalités au niveau des jetons/token ont capturé la fréquence et l’importance des jetons dans les distributions de ligne de commande.
- Les contrôles comportementaux ciblaient spécifiquement les modèles suspects généralement corrélés à une intention malveillante, tels que les techniques d’obfuscation, les commandes de transfert de données et les opérations de type credential-dumping ou memory-dumping.
Mise en œuvre des intégrations à échelle réduite (sous-ensemble échantillonné)
Notre deuxième stratégie a répondu aux problèmes d’évolutivité en utilisant des sous-ensembles échantillonnés quotidiennement avec 4 millions de lignes de commande uniques par jour. La réduction de la charge de calcul a permis d’évaluer les compromis en matière de performance et l’efficacité des ressources d’une approche moins coûteuse.
En particulier, les intégrations de fonctionnalités et le traitement des anomalies avec cette approche pourraient être exécutés sur des instances GPU Amazon SageMaker et CPU EC2 peu coûteuses, réduisant ainsi considérablement les coûts opérationnels.
Au lieu de l’ingénierie des fonctionnalités, la méthode échantillonnée a utilisé des intégrations sémantiques générées à partir d’un modèle d’intégration de transformateur pré-entraîné spécialement conçu pour les applications de programmation : Jina Embeddings V2. Ce modèle est explicitement pré-entraîné avec des lignes de commande, des langages de script et des référentiels de code. Les intégrations représentent des commandes dans un espace vectoriel sémantiquement significatif et de grande dimension, éliminant ainsi les surcharges en matière d’ingénierie manuelle au niveau des fonctionnalités et capturant de manière inhérente des relations complexes entre les commandes.
Bien que les intégrations à partir de modèles basés sur des transformateurs puissent nécessiter beaucoup de calculs, la taille plus petite des données de cette approche a rendu leur calcul bien plus gérable.
L’utilisation de deux méthodologies distinctes nous a permis d’évaluer si nous pouvions obtenir des réductions en termes de volume de calcul sans perte considérable en matière de performances de détection : à savoir, une information précieuse pour le déploiement en production.
Techniques de détection d’anomalies
Après la caractérisation, nous avons détecté des anomalies avec trois algorithmes de détection non supervisés, chacun choisi en raison de caractéristiques de modélisation distinctes. L’isolation forest identifie les partitions aléatoires dispersées; une méthode k-means modifiée utilise la distance centroïde pour trouver des points atypiques qui ne suivent pas les tendances courantes dans les données ; et l’analyse en composantes principales (ACP) localise les données avec de grandes erreurs en matière de reconstruction dans le sous-espace projeté.
Déduplication des anomalies et étiquetage LLM
Une fois la détection préliminaire des anomalies terminée, nous avons abordé un problème pratique : la duplication des anomalies. De nombreuses commandes anormales ne différaient que très peu les unes des autres, comme par exemple une petite modification de paramètre ou bien une substitution de nom de variable. Pour éviter les redondances et la surpondération involontaire de certains types de commande, nous avons établi une étape de déduplication.
Nous avons calculé les intégrations de ligne de commande à l’aide du modèle de transformateur (Jina Embeddings V2), puis mesuré la similarité des candidats vis à vis de l’anomalie avec des comparaisons de similarité cosinus. Cette dernière fournit une mesure vectorielle robuste et efficace de la similarité sémantique entre les représentations intégrées, garantissant que l’analyse d’étiquetage en aval se concentre bien sur des anomalies substantiellement nouvelles.
Par la suite, les anomalies ont été classées à l’aide d’un étiquetage automatisé basé sur les LLM. Notre méthode a utilisé le LLM de raisonnement o3-mini d’OpenAI, spécifiquement choisi pour sa compréhension contextuelle efficace des données textuelles liées à la cybersécurité, en raison de son paramétrage fin à usage général au niveau de diverses tâches de raisonnement.
Ce modèle attribue automatiquement à chaque anomalie une étiquette claire, bénigne ou malveillante, réduisant ainsi considérablement les interventions coûteuses des analystes humains.
La validation de l’étiquetage LLM a démontré une précision exceptionnellement élevée pour les étiquettes bénignes (près de 100%), confirmée via un score manuel ultérieur fourni par un analyste expert sur une semaine complète de données d’anomalies. Cette haute précision a permis l’intégration directe des anomalies inoffensives étiquetées dans les phases ultérieures pour l’entraînement du classificateur avec une confiance élevée et une validation humaine minimale.
Ce pipeline méthodologique soigneusement structuré, de la collecte complète de données à l’étiquetage précis, a produit divers ensembles de données de commande étiquetés de manière bénigne et a considérablement réduit les taux de faux positifs lorsqu’il a été mis en œuvre dans des modèles de classification supervisés.
Résultats et perspectives
Les implémentations à grande échelle et à échelle réduite ont donné lieu à deux distributions distinctes, comme le montrent respectivement les figures 1 et 2. Pour démontrer le potentiel de notre méthode en matière de généralisation, nous avons travaillé sur deux ensembles de données d’entraînement distincts de référence : une référence regex (RB) et une référence agrégée (AB). La référence regex a extrait des étiquettes à partir de règles statiques basées sur des regex et était censée représenter l’un des pipelines d’étiquetage les plus simples possibles. Les étiquettes de référence agrégées provenaient de règles basées sur des expressions régulières, de données sandbox, d’investigations de cas client et de télémétrie client. Il s’agit d’un pipeline d’étiquetage plus mature et plus sophistiqué.
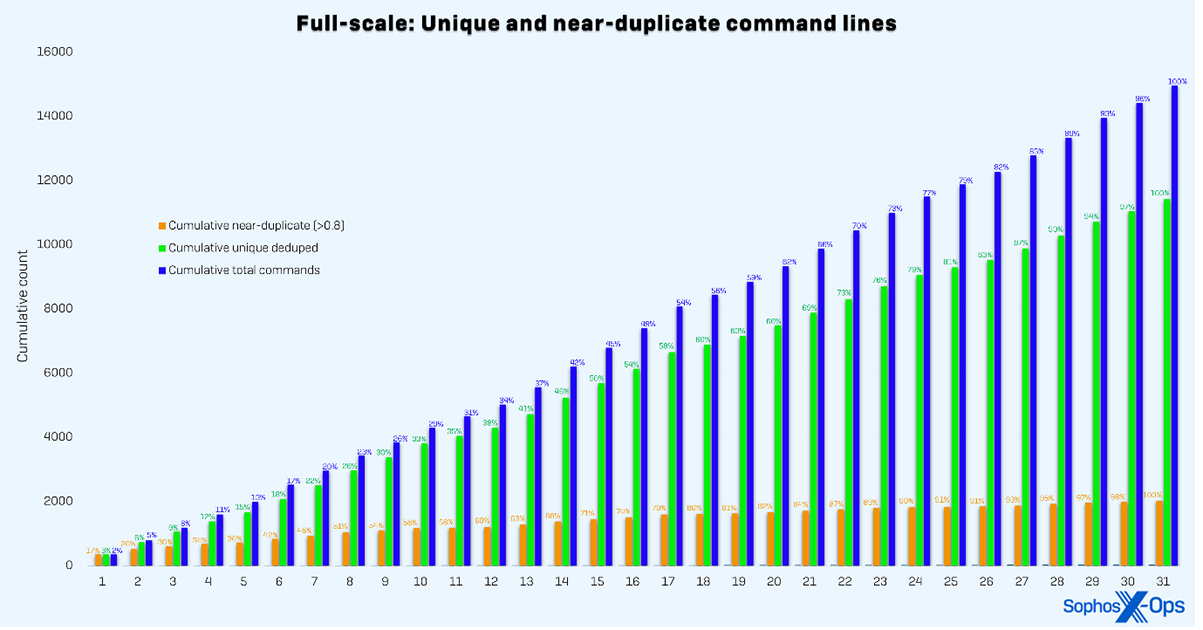
Figure 1 : Répartition cumulative des lignes de commande collectées par jour au cours du mois de test en utilisant la méthode à grande échelle. Le graphique montre toutes les lignes de commande, la déduplication par ligne de commande unique et la quasi-déduplication par similarité cosinus des intégrations de ligne de commande.
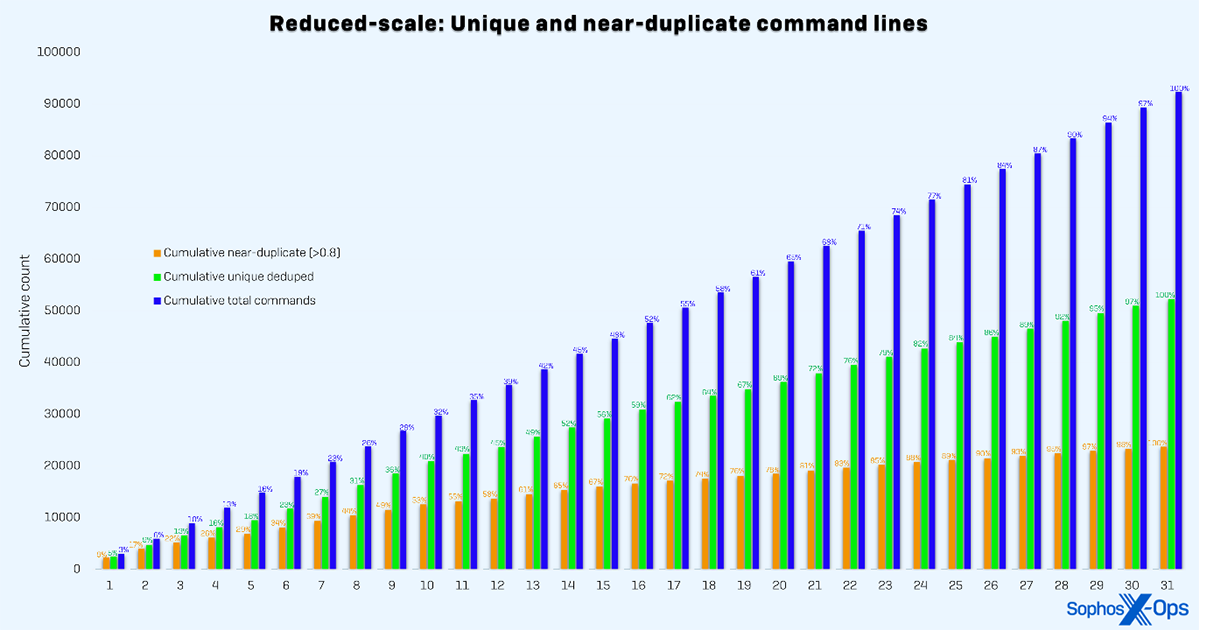
Figure 2 : Répartition cumulative des lignes de commande collectées par jour au cours du mois de test en utilisant la méthode à échelle réduite. L’échelle réduite atteint un plateau plus lentement car les données échantillonnées trouvent probablement davantage d’optimums locaux.
| Training set | Incident test AUC | Time split test AUC |
| Aggregated Baseline (AB) | 0,6138 | 0,9979 |
| AB + Full-scale | 0,8935 | 0,9990 |
| AB + Reduced-scale Combined | 0,8063 | 0,9988 |
| Regex Baseline (RB) | 0,7072 | 0,9988 |
| RB + Full-scale | 0,7689 | 0,9990 |
| RB + Reduced-scale Combined | 0,7077 | 0,9995 |
Tableau 1 : Aire sous la courbe pour les modèles de référence agrégés et regex entraînés avec des données inoffensives dérivées d’anomalies supplémentaires. L’ensemble d’entraînement de référence agrégé se compose de données client et de données sandbox. L’ensemble d’entraînement de référence des expressions régulières est constitué de données dérivées de ces dernières.
Comme le montre le tableau 1, nous avons évalué nos modèles entraînés à la fois sur un ensemble de tests fractionnés dans le temps et sur un référentiel étiqueté par des experts, dérivé d’investigations d’incident et d’un framework d’apprentissage actif. L’ensemble de tests fractionnés dans le temps s’étend sur trois semaines immédiatement après la période d’entraînement. Le benchmark étiqueté par les experts ressemble étroitement à la distribution de production des modèles précédemment déployés.
En intégrant des données inoffensives dérivées d’anomalies, nous avons amélioré l’aire sous la courbe (AUC) concernant la référence étiquetée par un expert au niveau des modèles de référence agrégés et regex de 27,97 points et 6,17 points respectivement.
Conclusion
Au lieu d’une classification malveillante directe et inefficace, nous démontrons l’utilité exceptionnelle de la détection d’anomalies pour enrichir la couverture des données inoffensives dans la longue traîne, un changement de paradigme qui améliore la précision du classificateur et minimise les taux de faux positifs.
Les LLM modernes ont permis d’obtenir des pipelines automatisés pour l’étiquetage de données bénignes, ce qui n’était pas possible jusqu’à présent. Notre pipeline a été parfaitement intégré dans un pipeline de production existant, soulignant ainsi sa nature générique et adaptable.
Billet inspiré de Sophos AI at Black Hat USA ’25: Anomaly detection betrayed us, so we gave it a new job, sur le Blog Sophos.