
** 本記事は、Prioritizing patching: A deep dive into frameworks and tools – Part 1: CVSS の翻訳です。最新の情報は英語記事をご覧ください。**
2022 年 8 月、Sophos X-Ops は複数の攻撃者に関するホワイトペーパーを発表しました。これらの攻撃者は、同じ組織を何度も標的にしていました。この調査における重要な推奨事項の 1 つは、「最悪のバグを優先的に修正する」、つまりユーザーの特定のソフトウェアスタックに影響を及ぼす可能性のある重大な、または注目度の高い脆弱性にパッチを適用することによって、繰り返し行われる攻撃を防ぐというものでした。このアドバイスは現在でも有用だと考えていますが、優先順位付けは複雑な問題です。何が「最悪のバグ」かを如何にして判別するのでしょうか。また、組織のリソースはおおよそ同じにもかかわらず、1 年間に公表される CVE の数が 2020 年の 18,325 件から 2022 年には 25,277 件、2023 年には 29,065 件と増え続けていることを考えると、実際どのように修復の優先順位を付ければよいのでしょうか。また、最近の調査によると、組織全体の修復能力の中央値は、各月に公開される脆弱性の 15% に過ぎません。
一般的なアプローチは、CVSS スコアを使用して、重要度別 (またはリスク別、後述します) にパッチ適用の優先順位付けを行うことです。FIRST の Common Vulnerabilities Scoring System は脆弱性の重要度を 0.0 から 10.0 の間で数値化したもので、以前から存在します。優先順位付けに広く利用されているだけでなく、PCI (Payment Card Industry) や米国連邦政府の一部など、一部の業界や政府では義務付けられています。
どのように機能するかは、見かけによらずシンプルです。脆弱性の詳細を入力すると、その脆弱性が「低」、「中」、「高」、「緊急」のどれに相当するかを示す数字が表示されます。この作業は非常に簡単です。続いて、自環境に該当しない脆弱性を除外し、残ったものから「緊急」と「高」の脆弱性にパッチを当てることに集中し、「中」と「低」には後でパッチを当てるか、リスクを受け入れるかのどちらかを選択します。すべてを 0~10 の値で評価できるため、理論上は簡単です。
しかし、話はそう単純ではありません。2 部構成のシリーズの第 1 部である本記事では、CVSS スコアがどのように算出されているかを確認し、なぜ CVSS がそれ自体では優先順位付けに必ずしもそれほど役に立つわけではないのかを説明します。第 2 部では、 優先順位付けに役立つ、より完全なリスク観を提供できる代替スキームについて説明します。
本題に入る前に、重要な注意点があります。本記事では CVSS のいくつかの問題について議論しますが、Sophos X-Ops は、この種のフレームワークを作成・維持することは苦労を伴い、あまり報われない仕事であることを強く認識しています。CVSS はそのコンセプトの本質的な問題に関連するものから、組織がフレームワークを使用する方法に関連するものまで、多くの批判にさらされています。しかし、CVSS は商業的な有料ツールではないことを指摘しておきます。CVSS は、脆弱性の重要度に関する有用かつ実用的なガイドを提供し、その結果、組織が公表された脆弱性への対応を改善するのに役立つことを意図したもので、組織が適切に利用できるように無料で公開されています。また、外部からのフィードバックを受けて、継続的に改良を加えています。本記事を公開する動機は、決して CVSS プログラムやその開発者、保守者を誹謗中傷することではなく、CVSS とその利用方法、特に修復の優先順位付けに関する追加的なコンテキストとガイダンスを提供し、脆弱性管理に関するより広い議論に貢献することにあります。
CVSS とは?
FIRST によれば、CVSS は「脆弱性の主要な特徴を捉え、その重要度を反映した数値スコアを作成する方法」です。この数値スコアは、前述したように 0.0 から 10.0 まで、101 段階の値を取り得ます。さらに、以下の尺度を用いて定性的な尺度に変換できます。
- なし: 0.0
- 低: 0.1 – 3.9
- 中: 4.0 – 6.9
- 高: 7.0 – 8.9
- 緊急: 9.0 – 10.0
CVSS は 2005 年 2 月に最初のバージョンが公開され、2007 年 6 月に v2 が、2015 年 6 月に v3 が公開されました。2019 年 6 月に公開された v3.1 は v3 から若干の修正が加えられており、2023 年 10 月 31 日には v4 が公開されました。CVSS v4 は本記事執筆時点ではまだ広く採用されていないため (たとえば、National Vulnerability Database (NVD) や Microsoft を含む多くのベンダーは依然として v3.1 を主に使用しています)、本記事では両方のバージョンについて検討します。
CVSS は、脆弱性の重要度を表す際の事実上の標準です。CVSS スコアは、NVD の CVE エントリの他、さまざまな脆弱性データベースやフィードに記載されています。CVSS の考え方は、単一の、標準化された、プラットフォームに依存しないスコアを作成することです。
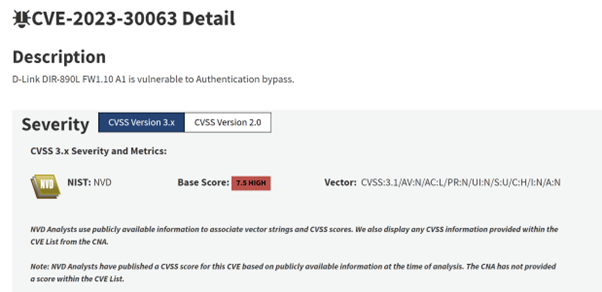
図 1: NVD への CVE-2023-30063 のエントリ。v3.1 でのベーススコア (7.5、高) とベクトル文字列に注目してください。また、2024 年 3 月段階では、NVD には依然として CVSS v4 のスコアが使用されていないことにも注意してください。
ほとんどのプロバイダーはベーススコアを利用しています。この値は脆弱性の本質的な特性と潜在的な影響を反映したものです。スコアの計算には、2 つのサブカテゴリにおける脆弱性評価が用いられます。それぞれが独自のベクトルを持ち、元の計算式に反映されます。
1 つ目のサブカテゴリは「悪用可能性」です。CVSS v4 では以下のベクトル (カッコ内は取り得る値) を含みます。
- 攻撃ベクトル (ネットワーク、近接、ローカル、物理)
- 攻撃の複雑さ (低、高)
- 攻撃の要件 (なし、あり)
- 必要な権限 (なし、低、高)
- ユーザーの関与 (なし、パッシブ、アクティブ)
2 つ目のカテゴリは「影響」です。以下の各ベクトルは、取り得る 3 つの値 (高、低、なし) が共通です。
- 脆弱なシステムの機密性
- 後続システムの機密性
- 脆弱なシステムの整合性
- 後続システムの整合性
- 脆弱なシステムの可用性
- 後続システムの可用性
では、これらの値を得た後、どのようにして実際の数値に変換するのでしょうか。FIRST の CVSS 仕様書に示されているように、v3.1 のメトリクス (上記の v4 のメトリクスとは少し異なります) にはそれぞれ対応する数値があります。
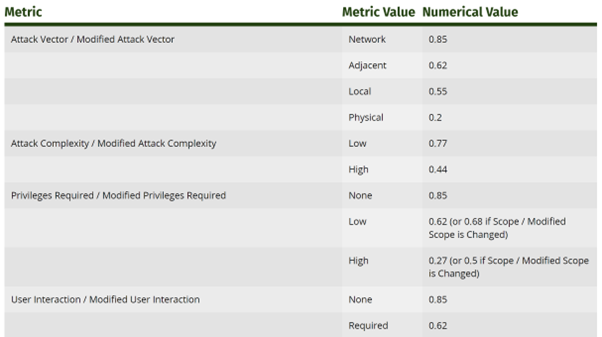
図 2: FIRST の CVSS v3.1 ドキュメントからの抜粋。各種メトリクスの数値を示しています。
v3.1 ベーススコアを計算するには、まず影響サブスコア (ISS)、影響スコア (ISS を使用)、悪用可能性スコアという 3 つのサブスコアを算出します。
影響サブスコア
1 – [(1 – 機密性) * (1 – 完全性) * (1 – 可用性)]
影響スコア
- スコープに変更がない場合は 42*ISS
- スコープに変更がある場合は 52 * (ISS – 0.029) – 3.25 * (ISS – 0.02)15
悪用可能性スコア
8.22 * 攻撃ベクトル * 攻撃の複雑さ * 必要な権限 * ユーザーの関与
ベーススコア
影響スコアが 0 よりも大きいものとして:
- スコープに変更がない場合: (Roundup (Minimum [(影響 + 悪用可能性), 10])
- スコープに変更がある場合: Roundup (Minimum [1.08*(影響 + 悪用可能性), 10])
上記の式には、Roundup と Minimum という 2 種類のカスタム関数が使用されています。Roundup は「小数点第 1 位までの範囲で入力と等しいかそれより大きい最小の数を返す」、Minimum は「2 つの引数のうち小さい方を返す」関数です。
CVSS の仕様はオープンソースであるため、上の図 1 に示されている CVE-2023-30063 の v3.1 ベクトル文字列を使用して、この例のベーススコアを手動で算出できます。
CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:N/A:N
ベクトル文字列と関連する数値を対照して確認することで、計算式に用いる値を特定できます。
- 攻撃ベクトル = ネットワーク = 0.85
- 攻撃の複雑さ = 低 = 0.77
- 必要な権限 = なし = 0.85
- ユーザーの関与 = なし = 0.85
- スコープ = 変更なし (スコープに対応する値自体は変化せず、他のベクトルの値を修正)
- 機密性 = 高 = 0.56
- 完全性 = なし = 0
- 可用性 = なし = 0
まず、ISS を計算します。
1 – [(1 – 0.56) * (1 – 0) * (1 – 0] = 0.56
スコープに変更はないため、影響スコアは ISS * 6.42 = 3.595 となります。
悪用可能性スコアは 8.22 * 0.85 * 0.77 * 0.85 * 0.85 = 3.887 となります。
最後に、これら 2 つの値をベーススコアの計算式に代入して足し合わせる、7.482 という値が得られます。この値を小数点第 2 位で四捨五入すると 7.5 であり、これが NVD が使用している CVSS v3.1 におけるベーススコアとなります。つまり、この脆弱性の重要度は「高」です。
v4 では、まったく異なるアプローチが採用されています。.さまざまな変更点に加え、「スコープ」メトリクスが廃止され、「ベース」メトリクス (攻撃の要件) が新たに追加されました。また、「ユーザーの関与」により詳細なオプションが追加されました。しかし、最も根本的な変更はスコアの算出方式です。算出方式はもはや「魔法の数字」や計算式には依存しません。その代わりに、異なる値の組み合わせの「等価セット」が専門家によってランク付けされ、圧縮され、スコアの算出に用いられます。CVSS v4 スコアは、ベクトルを計算し、関連するスコアをルックアップテーブルで確認することで算出されます。この計算方式では、202001 ベクトルのスコアは 6.4 (中) となります。
ベーススコアは脆弱性固有の特徴に依存するため、 計算方法に関係なく、時間の経過とともに変化することはないとされています。しかし、v4 の仕様では、新たに 3 つのメトリクスグループも採用されています。脅威 (時間とともに変化する脆弱性の特性)、環境 (ユーザーの環境に固有の特性)、補足 (付加的な外在的属性) です。
「脅威」メトリクスグループに含まれる指標は 1 つ (エクスプロイトの成熟度) のみです。この値は「エクスプロイトコードの成熟度」、「修復レベル」、「脆弱性情報の信頼度」の 3 つのメトリクスを含む v3.1 の「現状」メトリクスグループに代わるものです。「エクスプロイトの成熟度」メトリクスは、悪用の可能性を反映するように設計されており、4 つの値を取り得ます。
- 未定
- 攻撃に使用
- 概念実証 (PoC)
- 未報告
「脅威」メトリクスグループが脅威インテリジェンスに基づいてベーススコアに追加のコンテキストを追加するように設計されているのに対し、「環境」メトリクスグループはベーススコアのバリエーションであり、組織が「影響を受ける IT 資産のユーザ組織に対する重要性」をスコアに反映できるようになっています。このメトリクスには、3 つのサブカテゴリ (機密性要件、完全性要件、可用性要件) と、修正されたベースメトリクスが含まれます。値と定義はベースメトリクスと同じですが、修正されたメトリクスでは、重要度を増減させる可能性のある緩和策や構成の影響を反映させられます。たとえば、あるソフトウェアコンポーネントのデフォルトの構成に認証が実装されていない場合には、そのコンポーネントにおける脆弱性の「必要な権限」メトリクスの値は None になります。しかし、コンポーネントがパスワードで保護された別の組織の環境では、「必要な権限」の値は「低」または「高」に修正され、その組織の環境スコアはベーススコアよりも低くなります。
最後に、「補足」メトリクスグループには、スコアに影響しない以下のオプションのメトリクスが含まれます。
- 自動化可能性
- 修復
- 安全性
- 値の比重
- 脆弱性対応への取り組み
- プロバイダーの緊急性
「脅威」メトリクスグループと「補足」メトリクスグループが v4 でどの程度広く使われるようになるかは未知数です。v3.1 では、「現状」メトリクスが脆弱性データベースやフィードに表示されることはほとんどなく、「環境」メトリクスはインフラストラクチャごとに使用されることを想定しているため、上述の「脅威」および「補足」メトリクスグループがどのように採用されるかは不明です。
しかし、ベーススコアは広く用いられるものであり、その理由も明らかです。v4 で多くの変更が加えられたとはいえ、0.0 から 10.0 までの数値を取るという計算結果の基本的な性質は同じです。
しかし、この仕組みには批判もあります。
CVSS の欠点
CVSS スコアの意味
CVSS の仕様に固有の問題ではありませんが、CVSS スコアが実際に何を意味し、何のために使われるべきかについては、多少の誤解があるかもしれません。Howland 氏が指摘しているように、CVSS v2 の仕様書は、フレームワークの目的がリスク管理であることを明確にしています。
「現在、IT 管理者は、多くの異なるハードウェアおよびソフトウェアプラットフォームにわたる脆弱性を特定し、評価する必要があります。IT 管理者は、これらの脆弱性に優先順位をつけ、最大のリスクをもたらすものを修正する必要があります。しかし、修正すべき脆弱性の数が非常に多く、それぞれが異なる尺度を使用してスコア付けされている場合、IT 管理者はこの大量の脆弱性データをどのようにして実用的な情報に変換できるのでしょうか?Common Vulnerability Scoring System (CVSS) は、この問題に対処するオープンなフレームワークです。」
v2 の仕様書には「リスク」という単語が 21 回出現するのに対し、「重要度」という単語は 3 回しか出てきません。v4 の仕様書では、この数字は逆転します。「リスク」という単語は 3 回、「重要度」は 41 回出現します。v4 の仕様書の最初の一文では、このフレームワークの目的は「ソフトウェアの脆弱性の特徴と重要度を伝えること」であると述べられています。つまり、ある時点で、CVSS の公的な目的は、リスクの尺度から重要度の尺度へと変わったのです。
決して自慢げに指摘しているわけではありません。CVSS の制作者が誤解を防ぐため、あるいは誤解に対処するために、CVSS が何のためにあるのかを明示することに決めただけかもしれません。ここでの本当の問題は、フレームワークそのものにあるのではなく、スコアが時々利用される方法にあります。最近の仕様で明確化されているにもかかわらず、CVSS のスコアは、リスクの尺度 (すなわち、「ある事象の発生確率とその結果の組み合わせ」、あるいは、よく引用される計算式と同様、脅威*脆弱性*結果) として (誤って) 使われることがありますが、実際にはリスクを測定するものではありません。攻撃者が「すでに脆弱性を発見・特定している」と仮定し、その脆弱性を悪用する方法が開発されており、さらにその悪用方法が有効であった場合に発生し得る合理的な最悪のシナリオにおいて、その脆弱性の特性と潜在的な影響を評価することで、リスクの一面を測定しているに過ぎません。
CVSS スコアはジグソーパズルの 1 つのピースにはなりますが、決してその完成形ではありません。意思決定の基礎となる単一の数字があるのは良いことかもしれませんが、リスクというのは遥かに複雑な事象です。
そうは言っても、優先順位付けには使えるのでは?
その答えは「はい」でもあり「いいえ」でもあります。最近の調査によると、公開された CVE の数が増えているにもかかわらず (すべての脆弱性に CVE ID が付与されているわけではないため、ジグソーパズルは完成していません)、実際に悪用されたとして検出されるのはごく一部 (2% から 5%) に過ぎません。つまり、今月 2,000 件の CVE が公開され、脆弱性インテリジェンスフィードからそのうち 1,000 件が組織内の資産に影響を及ぼすことが判明したとしても、悪用される (悪用に気付ける) 可能性があるのは 20~50 件程度ということになります。
これは良いニュースです。しかし、CVE が公表される前に発生した悪用はさておき、攻撃者が将来どの CVE をいつ悪用するかはわかりません。では、どの脆弱性に最初にパッチを当てるべきかは如何にして知ることができるのでしょうか。攻撃者がエクスプロイトを開発、販売、使用する際に、形式化されていないとはいえ、CVSS と同様の思考プロセスを使用しているのではないかと思われるかもしれません。つまり、より単純で影響の大きい脆弱性に重点を置いているのではないかということです。その場合、CVSS スコアの高い脆弱性を優先的に修正することは非常に理に適っています。
しかし研究者たちは、CVSS (少なくとも v3 まで) が悪用可能性の予測因子にはならないことを示してきました。2014 年に、トレント大学の研究者たちは脆弱性とエクスプロイトに関する公開データの分析に基づき、 「高い CVSS スコアが割り当てられたという理由で脆弱性を修正することは、修正すべき脆弱性を無作為に選ぶことに等しい」と主張しています。さらに最近 (2023 年 3 月)、Howland 氏の CVSS に関する研究によると、28,000 件以上の脆弱性のサンプルの中で CVSS v3 のスコアが 7 の脆弱性が最も攻撃に利用される傾向が強いことが示されています。スコア 5 の脆弱性は、スコア 6 の脆弱性よりも攻撃に利用される可能性が高く、スコアが 9 または 8 の脆弱性は、スコア 10 の脆弱性 (緊急な脆弱性) よりも頻繁にエクスプロイトが開発されていました。
言い換えると、CVSS スコアと悪用可能性との間には相関関係はないようです。Howland 氏によれば、関連するベクトル (攻撃の複雑さや攻撃ベクトルなど) を重視しても、この傾向は変わらないということです (ただし、この法則が CVSS v4 でも当てはまるかどうかは未知数です)。
この指摘は直感に反します。Exploit Prediction Scoring System (EPSS) の制作者が指摘しているように (EPSS についてはパート 2 で説明します)、CVSS スコアと EPSS スコアをプロットした結果、予想されるよりも相関が低いことが判明しました。
「この結果は (中略) 攻撃者が、最大の影響をもたらす脆弱性、あるいは必ずしも悪用しやすい脆弱性 (認証されていないリモートコード実行など) だけを標的にしているわけではないことを示唆する証拠となります。」
攻撃者が最も興味を持っているのは重要かつ手間のかからない脆弱性を悪用することである、という仮説が成り立たないのには、さまざまな理由があります。リスクと同様に、犯罪のエコシステムを単一の側面に落とし込むことはできません。悪用可能性に影響を与え得る他の要因としては、影響を受ける製品のインストールベース、他の製品よりも特定の影響や製品ファミリを優先すること、攻撃のタイプや動機による違い、地理的なものなどがあります。これらは複雑かつまったく異なる議論であり、本記事の範囲外です。しかし、Jacques Chester 氏が CVSS に関する徹底的かつ示唆に富むブログ投稿で論じているように、主な要点は以下の通りです。「攻撃者は攻撃を試みる際、CVSS v3.1 を使って優先順位を付けているわけではないようです。なぜ防御側だけそうする必要があるでしょうか。」しかし、Chester 氏は CVSS はまったくもって使うべきではないと主張しているわけではありません。優先順位付けの唯一の要因にすべきではない、ということです。
再現性
スコアリングフレームワークの基本的な条件の 1 つは、同じ情報が与えられた場合、別の人物がプロセスを通じて作業することで、ほぼ同一のスコアを算出できることです。脆弱性管理のような複雑な分野では、主観、解釈、技術的な理解がしばしば入り交じるため、ある程度の乖離が生じることは合理的に予想されるかもしれません。しかし、2018 年の調査では、CVSS メトリクスを使用した脆弱性の重大性評価において、セキュリティ専門家の間でも大きな乖離があることが示されました。つまり、あるアナリストが最終的に「高」に分類した脆弱性が、別のアナリストでは「緊急」または「中」に分類される可能性があるということです。
しかし、FIRST がその仕様書で指摘しているように、CVSS ベーススコアは本来ベンダーや脆弱性アナリストによって計算されるべきものです。実環境では、ベーススコアは通常、公開フィードやデータベースに表示され、組織はそのスコアを利用します。多数のアナリストによって何度も算出されることを意図したものではありません。経験豊富なセキュリティの専門家が、少なくとも場合によってはまったく異なる評価を下し得るという事実は懸念の原因にはなりますが、それでも CVSS の仕様は心強いものです。CVSS の定義があいまいであったためなのか、調査参加者の CVSS スコア算出経験が不足していたためなのか、セキュリティの概念に対する理解の相違に関連したより広範な問題なのか、あるいは上記の一部または全部が関係しているのかは不明です。この点について、また、この問題が 2024 年および CVSS v4 においても当てはまるのかどうかについて、さらなる調査が必要でしょう。
実害
CVSS v3.1 の影響メトリクスは、従来の環境における従来型の脆弱性に関連するものに限定されています。つまり、CIA (機密性、完全性、可用性) の三要素です。v3.1 が考慮に入れていないのは、システム、デバイス、インフラストラクチャに対する攻撃が人や財産に重大な物理的被害をもたらす可能性があるというセキュリティにおける最近の動向です。
しかし、v4 はこの問題に対処しています。v4 には、専用の「安全」メトリクスが含まれており、以下のような値を取ります。
- 未定
- あり
- ごくわずか
後者の 2 つの値では、フレームワークは IEC 61508 標準の定義である「無視できる」 (最悪でも軽傷)、「中程度」 (1 人または複数人への重傷)、「致命的」(1 人の人命の損失)、または「壊滅的」(複数の人命の損失) を使用します。「安全」メトリクスは、後続システムへの影響セットの算出のため、「環境」メトリクスグループ内の修正された「ベース」メトリクスにも適用できます。
すべてはコンテキスト次第
CVSS は可能な限りすべて簡素化するよう最善を尽くしていますが、シンプルに保つことが時には詳細を省くことを意味することもあります。たとえば、v4 では「攻撃の複雑さ」が取り得る値は「低」と「高」の 2 つだけです。
低: 「攻撃者は、脆弱性を悪用するために特定の行動を取る必要はありません。この攻撃は、脆弱性の悪用のため、標的ごとにセキュリティ技術を回避する必要がありません。攻撃者は、脆弱性のあるシステムに対して再現可能な成功を期待できます。」
高: 「攻撃が成功するかどうかは、攻撃を妨げるようなセキュリティ強化技術の回避や迂回に依存します (略)。」
攻撃者、脆弱性アナリスト、ベンダーの中には、脆弱性の複雑さが「低」か「高」かのどちらかに分類されるという見解に反対する方もおられるでしょう。しかし、FIRST Special Interest Group (SIG) のメンバーは、v4 では新しい「攻撃の要件」メトリクスによってこの問題に対処していると主張しています。このメトリクスは、脆弱性の悪用に特定の条件が必要かどうかを把握することで、脆弱性をより詳細に評価するものです。
「ユーザーの関与」メトリクスも一役買っています。v4 では、v3.1 (値は「なし」または「必須」のみ) に比べてこのメトリクスの取り得る値がより細かくなってはいます。しかし、「受動的」 (限定的かつ不随意的な関与) と「能動的」 (具体的かつ意識的な関与) の区別は、セキュリティコントロールによって追加される複雑さは言わずもがな、実世界で発生する幅広いソーシャルエンジニアリングを反映していないことは間違いありません。たとえば、ユーザーを説得して文書を開かせること (あるいはプレビュー表示させること) はほとんどの場合、ユーザーを説得して文書を開かせ、保護ビューを無効にし、セキュリティ警告を無視させることよりも簡単です。
公平のため指摘しておくと、CVSS は過度に詳細であること (すなわち、スコアを計算するのに膨大な時間がかかるほど多くの可能な値や変数を含むこと) と過度に単純であることの間に位置する必要があります。CVSS モデルをより詳細にすることは、迅速かつ実用的で、重要度に関する万能のガイドとなることを意図したものを複雑化してしまうでしょう。とはいえ、重要なニュアンスが欠落する場合もしばしばあります。そして、脆弱性の状況とは本質的に微妙なものです。
また、v3.1 仕様と v4 仕様の両方における定義の一部は、一部のユーザーを混乱させる可能性があります。たとえば、攻撃ベクトル (ローカル) の定義下でのシナリオとして以下の場合を考えてみましょう。
「攻撃者は、ローカル (キーボード、コンソールなど) や、ターミナルエミュレーション (SSH など) を通じて標的システムにアクセスすることで、脆弱性を悪用しました。 [太字は筆者による: v3.1 の仕様書ではこの部分は またはリモートから (SSH など)」となっています。]
ここでの SSH の使用は、「近接」の定義と同様、SSH 経由でローカルネットワーク上のホストにアクセスすることとは異なる点に注意してください。
「つまり、攻撃が同じ近接共有 (例:Bluetooth、NFC、IEEE 802.11) または論理 (例:ローカル IP サブネット) ネットワークから、あるいはセキュアまたはその他の限定された管理ドメイン内から開始されなければならないことを意味します」[太字は筆者]
仕様書では、脆弱なコンポーネントが「ネットワークスタックにバインドされている (ネットワーク)」か「バインドされていない (ローカル)」かを区別していますが、この区別は、CVSS スコアを計算するときやベクトル文字列を解釈しようとする際に、一部のユーザーにとっては直感に反したり、混乱を招いたりする可能性があります。これらの定義が正しくないということではなく、一部のユーザーにとっては不透明で直感的でないということです。
最後に、Howland 氏は、CVSS スコアがコンテキストを考慮していないとする実際のケーススタディを提供しています。CVE-2014-3566 (POODLE 脆弱性) の CVSS v3 スコアは 3.4 (低) です。しかし、この脆弱性は公開時に 100 万件近い Web サイトに影響を与え、大量のアラームを発生させ、組織にさまざまな影響を及ぼしました。Howland 氏は、この側面が CVSS では考慮に入っていないとしています。また、本シリーズの範囲外ではありますが、脆弱性に関するメディアの報道や宣伝が優先順位付けに不釣り合いな影響を与えるかどうかという、コンテキストに関連した別の問題もあります。逆に、脆弱性のランキングは常にコンテキストを考慮していないため、現実世界のリスクが実際には比較的低いにもかかわらず過度に高くなる可能性があると主張する研究者もいます。
「私たちはただの人….」
v3.1 では、CVSS は計算式の入力に順序データを用いることがあります。順序データは、項目間の距離が不明な、ランク付けされたデータです (「なし」、「低」、「高」など)。カーネギーメロン大学の研究者が指摘するように、順序データの項目を足したり掛けたりすることは無意味です。たとえば、回答に Likert 尺度が用いられているアンケートの回答結果を足したり掛けたりすることは無意味です。CVSS 以外の例を挙げると、給与に関する質問で「満足している [4.0]」と答え、ワークライフバランスに関する質問で「やや満足している [2.5]」と答えた場合、これらを掛け合わせて、調査結果全体のスコアは 10.0 (「仕事にとても満足している」) だと結論付けることはできません。
また、順序データを使用するということは、CVSS スコアを平均化すべきではないことを意味します。たとえば、ある選手がある種目で金メダルを獲得し、別の種目で銅メダルを獲得した場合に、平均して「銀メダルを獲得した」と言うことはできません。
v3.1 では、メトリクスのハードコード化された数値がどのように選択されたのかも不明でした。FIRST が v4 で計算式を使用しないことを選択した理由の一つかもしれません。その代わりに、v4 のスコアシステムは、可能性のある値の組み合わせをグループ化してランク付けし、ベクトルを計算し、ルックアップ関数を使用してスコアを割り当てる仕組みになっています。つまり、計算式の代わりに、FIRST によって選ばれた専門家が、協議を通じてさまざまなベクトルの組み合わせの重要度を決定しています。一見したところ、計算式の問題点を完全に否定するものであり、合理的なアプローチに思えます。
ブラックボックス?
v3.1 と v4 の仕様、計算式、定義は公開されていますが、研究者の中には、CVSS には透明性の欠如という問題があると主張する者もいます。たとえば v4 では、数式に数値を代入するのではなく、アナリストがあらかじめ設定されたリストを使ってベクトルを調べる方式になりました。しかし、これらの専門家がどのように選ばれたのか、「それぞれの等価セットを代表するベクトル」をどのように比較したのか、「専門家による比較データ」が「最も重要度の低いものから最も重要度の高いものへのベクトルの順序を計算するために」どのように使用されたのかは明らかではありません。私たちの知る限り、この情報は公開されていません。本シリーズのパート 2 でも確認するように、この問題は CVSS に限ったことではありません。
セキュリティの分野では何でもそうですが、基礎となる仕組みが十分に知られていない、あるいは理解されていないシステムによって生み出される結果は、その使用目的の重要性と性質を考慮し、ある程度懐疑的に扱われるべきです。その結果が間違っている、あるいは誤解を招くものであると証明された場合の関連するリスク水準にも注意しましょう。
結論の前に
最後に、CVSS のスコアがなぜ 0 から 10 の値を取るのかを考えてみましょう。理解しやすい単純な尺度であることは明らかですが、特に計算式への入力が定性的であり、CVSS が確率の尺度でない以上、恣意的でもあります。v3.1 では、スコアの上限が 10 であることを Minimum 関数が保証しています (Minimum 関数を用いない場合、少なくとも私たちの計算では、ベーススコアが 10.73 に達する可能性があります)。v4 では、ベクトル化メカニズムは設計上の最大のスコア範囲である 10 点を上限としています。
しかし、脆弱性の重要度に「最大」というものはあるのでしょうか。スコア 10.0 の脆弱性はすべて同じように危険なのでしょうか。おそらくこの選択は、解釈を容易にするためのものでしょう。しかし、この方法で重要度を正確かつ現実的に表現することができるのでしょうか。
結論
不完全ではありますが、簡単な思考実験をしてみましょう。生物学的ウイルスの重要度を測定する評価システムを想像してみてください。その点数によって、ウイルスが人々に与える可能性のある影響や、ウイルスの特徴に基づく潜在的な脅威を知ることができます (たとえば、空気感染するウイルスは、経口摂取や物理的接触によってのみ感染するウイルスよりも、より広範な脅威となる可能性が高くなります。ただし、すべての例で同様だとは限りません)。
ウイルスに関する情報を計算式に入力すると、システムは 0 から 10 の間の非常にわかりやすい数値スコアを生成します。医療業界の一部は、ウイルスへの対応の優先順位を決めるためにこのスコアを使用しており、一般の人々の中には、システムの開発者が推奨しているわけではないものの、リスクの指標としてこのスコアを信頼する人もいます。
しかし、年齢、健康状態、免疫システムの効率、併存疾患、過去の感染による免疫力などに基づいて、ウイルスがあなた個人にどのような影響を与えるかを知ることはできません。あなたが感染する可能性や、回復するのに要する時間はわかりません。評価システムはウイルスの特性 (たとえば複製速度や変異能力、感染源や感染の地理的分布など) をすべて考慮するわけでも、ワクチンや予防手段があるかどうかなど、より広いコンテキストを考慮するわけでもありません。その結果、理に適っていると思われるもの (たとえば HIV は一般的なライノウイルスよりも上位に位置しています) もあれば、そうでないもの (ポリオウイルスは世界の大部分で事実上根絶されているにもかかわらず、その影響の可能性から高得点となります) もあります。また、独自の実証的研究により、このシステムのスコアは罹患率の予測には役立たないことが示されています。
では、個人的なリスク評価、たとえばパーティに参加するかどうか、休暇に出かけるかどうか、入院している人を見舞うかどうかを決めるときに、このシステムだけに頼るべきでしょうか。医学界は、臨床研究や疫学的取り組みの優先順位を決めるのに、このシステムに頼るべきでしょうか。
直感的には、ほとんどの人が疑問を抱くでしょう。このシステムに欠陥があるのは明らかです。しかし、このシステムはまったく無意味ではありません。スコアは感染の潜在的な結果について示唆してくれるため、ウイルスを分類したり、ウイルスの本質的な特性に基づいて可能性のある脅威を強調したりするのには役立ちます。たとえば、狂犬病は水疱瘡よりも本質的に重大であることを知ることは、実際に狂犬病に感染する可能性が低くても役に立ちます。リスクアセスメントを実施する際に、他の情報と合わせてこのシステムのスコアを考慮に入れることは確かに可能です。しかし、それ以上の情報も必要です。
公正を期すために触れておくと、FIRST は v4 の FAQ 文書でこの点を指摘しています。代替のスコアシステムについては、「脆弱性対応の優先順位をより適切に評価・予測し、情報に基づいた決定を下すために、これらのシステムを併用できる」と記しています。次回の記事では、いくつかの同種のシステムについて説明します。