
** 本記事は、And I Shall Call It Mini-Me GPT: Using Large Language Models to Classify the Uncharted Web の翻訳です。最新の情報は英語記事をご覧ください。**
Web コンテンツフィルタリングは、マルウェア対策や侵害検知ほどセキュリティの中心的な役割を担っていないように思われるかもしれませんが、規制遵守や職場の安全確保にも重要な役割を果たしています。マルウェアやフィッシングのように悪意のあるコンテンツを選別する URL のセキュリティ分類とは異なり、Web フィルタリングは、その性質に基づいてコンテンツをラベリングする必要があるため、より一般的な問題です。
Web サイトのカテゴリーラベルは、一般にサイトの内容や目的を表しています。 「ビジネス」、「コンピューターとインターネット」、「食品と食事」、「エンターテインメント」といった大まかな分類がある一方、「銀行」、「ショッピング」、「検索エンジン」、「ソーシャルメディア」、「就職活動」、「教育」など、サイトの目的に焦点を当てたものもあります。さらに、「性描写」、「アルコール」、「マリファナ」、「武器」など、有害だと考えられる内容を表す分類もあります。組織は、社内ネットワークからアクセスする Web サイトの種類をフィルタリングまたは測定するためにさまざまなポリシーを設定したい場合があります。
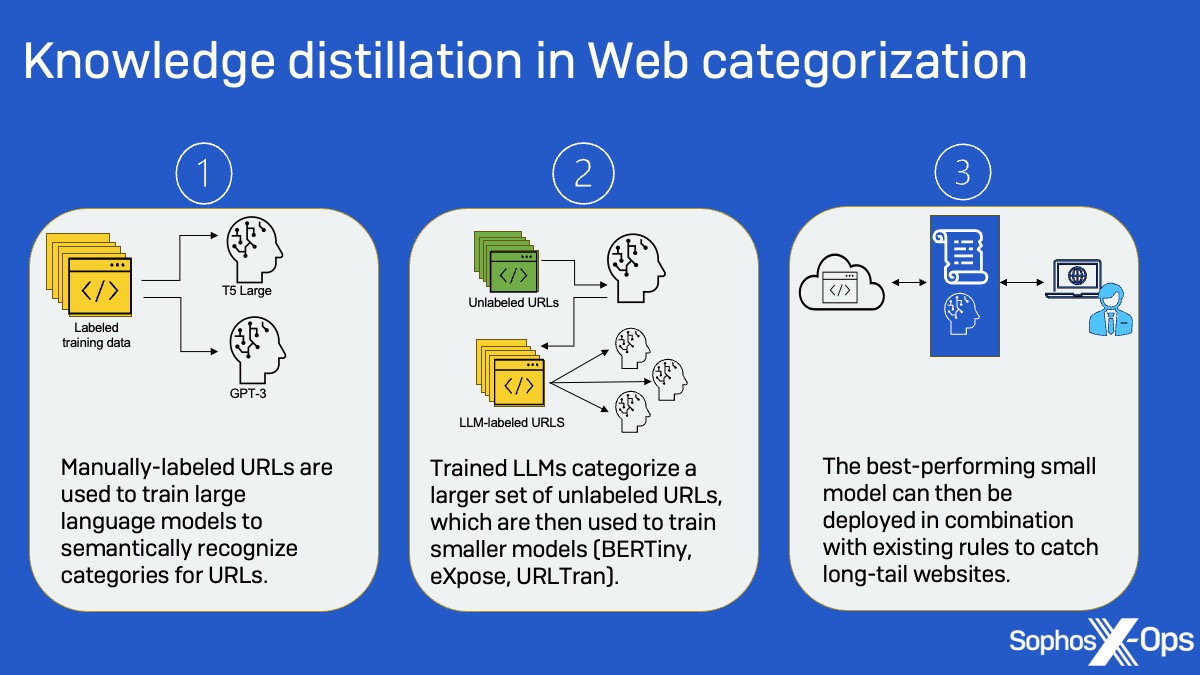
Sophos X-Ops は、大規模言語モデル (LLM) 機械学習を Web フィルタリングに適用し、「ロングテール」 Web サイトを特定する方法を研究してきました。「ロングテール」 Web サイトとは、何百万ものドメインのうち、訪問者が比較的少なく、生身の分析者がほとんど、あるいはまったく認知していないドメインのことです。 LLM そのものは、その規模と計算資源のコスト面から、この用途には実用的ではありません。しかし LLM は、より小さな分類モデルを訓練するための「教師」モデルとしても使用できます。この手法は、新たに遭遇したドメインに対してラベルを生成するために必要な計算資源を削減するのにも役立ちます。
Sophos AI チームは、OpenAI の GPT-3 や Google の T5 Large のような LLM を使い、より小さなモデルを学習させることで、スクリーニングされていない URL をその場で分類できるようにしました。
最も重要なのは、今回使用された方法は、他のセキュリティタスクのため取得した LLM の出力に基づいて、小型で経済的なモデルを作成するために使用できるということです。同チームの研究は、最近発表された論文「大規模言語モデルの知識抽出による Web コンテンツフィルタリング」で詳述されています。
「ロングテール」URL の問題
Web サイトの分類は、ある種の法則に基づいたドメインとカテゴリのマッピングに依存しており、アナリストが作成したシグネチャを使用して URL のテロップを探し、新しいドメインに迅速にラベルを割り当てています。この種のマッピングは、有名サイトの URL を迅速にラベリングし、重要なコンテンツをブロックする誤検出を防ぐために不可欠です。サイト分類のパターンを実際に人間が識別し、ドメインマッピングツールの機能セットに学習させます。
問題は「ロングテール」 Web サイト、つまり一般的に署名が割り当てられない、あまり訪問されないドメインにあります。既存の Web サイトは 10 億を超える上、毎日何千件もの新しい Web サイトが出現しているため、ロングテール Web サイトを対象に手動でシグネチャベースのアプローチを維持し、拡張するのはますます困難になっています。 トラフィックの多い有名 Web サイトは、ほぼ全てのラベリング手法で 100% カバーされているのに対し、以下の図の通り、アナリストがラベリングしたドメインの割合はアクセス数上位 100 位を超えると急速に減少し始めます。上位 5000 位以下のサイトのコンテンツにラベリングがされている割合は 50% 以下です。
図 1:テレメトリで観測された、ドメインの人気度とコンテンツへのラベリングの関係。この状況を改善する一つの方法は、以前はラベリングされていなかった範囲の URL の処理に機械学習を導入することです。しかし現在に至るまで、(Microsoft の URLTran のような) 機械学習を利用する試みのほとんどは、コンテンツに基づいて Web サイトを分類するのではなく、セキュリティ上の脅威を検出するというタスクを主目的としてディープラーニングモデルを使用していました。これらのモデルを、カテゴリ分けを行うように再学習させることも可能ではありますが、そのためには極めて大規模な学習データセットが必要です。たとえば URLTran は、悪意のある URL を検出する訓練のためだけに 100 万件以上のサンプルを使用していました。)
AI を利用した自動化
そこで、LLM の出番です。SophosAI チームは、LLM が大量の未ラベルテキストを事前に学習していることから、LLM を使用すれば、より少ない初期データで、より正確に URL ラベリングを実行できると考えました。SophosAI チームがドメイン伝播シグネチャでラベリングされたデータで LLM の微調整を行い、「ロングテール」 Web サイトの分類に取り組ませたところ、 LLM は Microsoft の最新モデルアーキテクチャよりも 9% 高い精度でラベリングを実行できることを発見しました。さらに、LLM を学習させるのに必要な URL のセットも数百万件ではなく、数千件で済みました。
この LLM は、より小さなデータセットの URL 内のサイトクラスとキーワードの間の意味的関係を使用して、「ロングテール」 Web サイトを用いて未ラベリングデータセットに対するラベルを作成するのに使用されました。LLM によって作成されたラベルは、より小さなモデル (BERTiny および BERT ベースの URLTran 変換モデル、および 1 次元畳み込みモデル eXpose) を訓練するために使用されました。この「知識の精製」とでも呼ぶべきアプローチにより、研究チームはモデルを従来の 175 分の 1 に縮小し、パラメータの数を 7 億 7000 万個からわずか 400 万個に減らした上で、LLM と同水準の性能を実現しました。
作成されたモデルの中で最も精度の高いセットは、「ディープラーニング」だけで学習させたモデルよりもはるかに優れたパフォーマンスを示しましたが、その精度は完璧からは程遠くなっています。最高のモデルでさえ、精度は 50% を下回りました。多くの URL は、その中に十分な「合図」が埋め込まれていなかったために、適切なラベリングができませんでした。そのため、URL 中のコンテンツをより深く調査しなければ解明できない不確実さが生み出されていました。
しかし、T5 Large モデルは、以下の混同行列からも分かる通り、フィルタリングされる可能性のあるカテゴリではそれなりに良好な結果を示し、賭博やピアツーピアの共有サイトについてはテストデータでほぼ完璧なラベリングを実行しました。アルコール、武器、ポルノに関連する Web サイトでも 60% 以上の検出率を示しました。
精度を向上させるため、SophosAI チームはいくつかの方法を提案しています。まず、1 件の Web サイトに複数のカテゴリを割り当てられるようにすれば、カテゴリの重複問題は解決します。URL サンプルから HTML や画像を取得して情報を補完することで、URL の分類精度をより向上させられる可能性があります。また、GPT-4 のように新しい LLM を教師として使用することもできるでしょう。
既存のプロセスと組み合わせることで、この種の AI ベースのカテゴリ分類はロングテール Web サイトの取り扱いを大幅に改善できます。さらに、今回試された「知識の精製」手法が適用できるセキュリティ関連のタスクは他にもあります。
詳細については、arxiv.org の Tamas Voros、Sean Bergeron、SophosAI 責任者の Konstantin Berlin が執筆した論文をご覧ください。
コメントを残す