
Los Grandes Modelos de Lenguaje (LLM) tienen el potencial de automatizar y reducir las cargas de trabajo de muchos colectivos, incluidos los analistas de ciberseguridad y los respondedores a incidentes. Pero los LLM genéricos carecen del conocimiento específico para manejar bien estas tareas. Aunque pueden haber sido construidos con datos de entrenamiento que incluían algunos recursos relacionados con la ciberseguridad, eso es a menudo insuficiente para asumir tareas más especializadas que requieren conocimientos más actualizados y, en algunos casos, propios para realizarlas bien.
Existen varias soluciones para ajustar los LLM «de reserva» (no modificados) a determinados tipos de tareas. Pero, por desgracia, estas soluciones eran insuficientes para los tipos de aplicaciones de los LLM que Sophos X-Ops intenta implementar. Por eso, SophosAI ha montado un marco que utiliza DeepSpeed, una biblioteca desarrollada por Microsoft que puede utilizarse para entrenar y afinar la inferencia de un modelo con (en teoría) billones de parámetros aumentando la potencia de cálculo y el número de unidades de procesamiento gráfico (GPU) utilizadas durante el entrenamiento. El marco tiene licencia de código abierto y se puede encontrar en nuestro repositorio de GitHub.
Aunque muchas de las partes del marco no son novedosas y aprovechan librerías de código abierto ya existentes, SophosAI ha sintetizado varios de los componentes clave para facilitar su uso. Y seguimos trabajando para mejorar el rendimiento del marco.
Las alternativas (inadecuadas)
Existen varios enfoques para adaptar los LLM de stock al conocimiento específico del dominio. Cada uno de ellos tiene sus propias ventajas y limitaciones.
| Enfoque | Técnicas aplicadas | Limitaciones |
| Generación de recuperación aumentada |
|
|
| Entrenamiento continuado |
|
|
| Ajuste fino eficiente de parámetros |
|
|
Para ser plenamente eficaz, un LLM experto en un dominio requiere el preentrenamiento de todos sus parámetros para aprender los conocimientos propios de una empresa. Esta tarea puede consumir muchos recursos y tiempo, por lo que recurrimos a DeepSpeed para nuestro marco de entrenamiento, que implementamos en Python. La versión del marco que publicamos como código abierto puede ejecutarse en el servicio de aprendizaje automático SageMaker de Amazon Web Services, pero podría adaptarse a otros entornos.
Los marcos de entrenamiento (incluido DeepSpeed) te permiten escalar grandes tareas de entrenamiento de modelos mediante el paralelismo. Hay tres tipos principales de paralelismo: de datos, de tensor y de canalización.
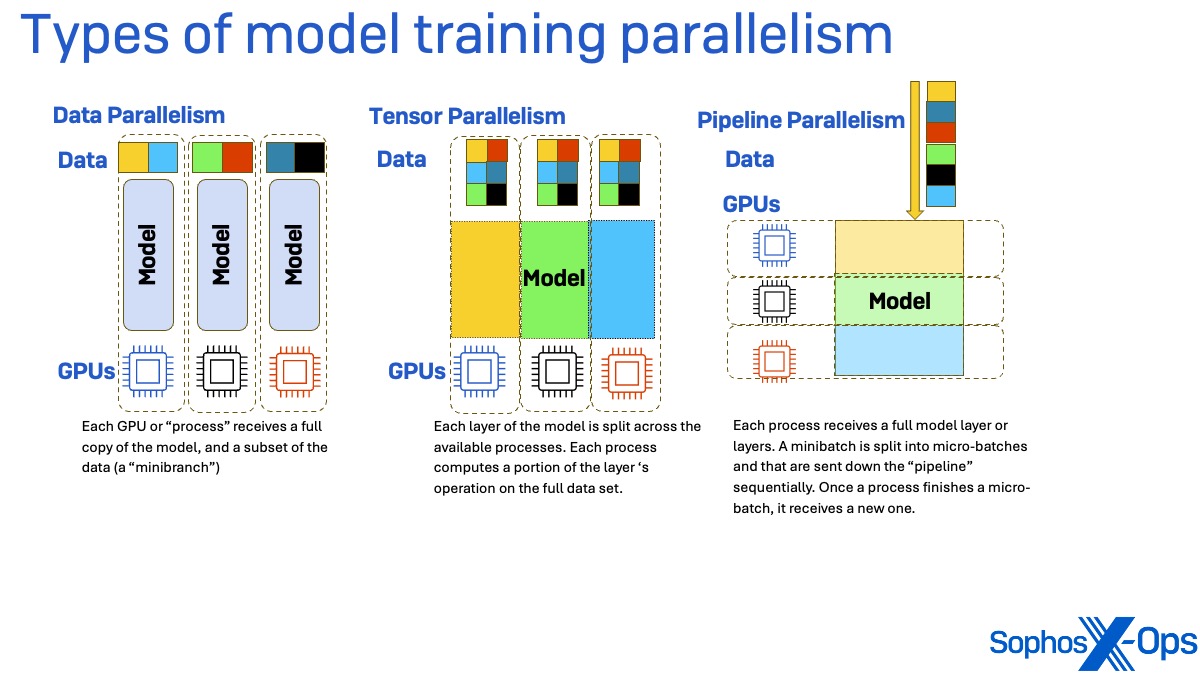
En el paralelismo de datos, cada proceso que trabaja en la tarea de entrenamiento (esencialmente cada unidad de procesamiento gráfico, o GPU) recibe una copia de los pesos del modelo completo, pero solo un subconjunto de los datos, denominado minilote. Una vez completadas la pasada hacia delante por los datos (para calcular la pérdida, o la cantidad de inexactitud en los parámetros del modelo que se utiliza para el entrenamiento) y la pasada hacia atrás (para calcular el gradiente de la pérdida), se sincronizan los gradientes resultantes.
En el paralelismo tensorial, cada capa del modelo utilizado para el entrenamiento se divide entre los procesos disponibles. Cada proceso calcula una parte del funcionamiento de la capa utilizando el conjunto completo de datos de entrenamiento. Las salidas parciales de cada una de estas capas se sincronizan entre los procesos para crear una única matriz de salida.
El paralelismo de canalización divide el modelo de forma diferente. En lugar de paralelizar dividiendo las capas del modelo, cada capa del modelo recibe su propio proceso. Los minilotes de datos se dividen en microlotes que se envían por la «tubería» secuencialmente. Cuando un proceso termina un microlote, recibe uno nuevo. Este método puede experimentar «burbujas» en las que un proceso está inactivo, esperando la salida de los procesos que alojan capas anteriores del modelo.
Estas tres técnicas de paralelismo también pueden combinarse de varias formas, y lo hacen, en la biblioteca de entrenamiento DeepSpeed.
Hacerlo con DeepSpeed
DeepSpeed realiza un paralelismo de datos fragmentado. Cada capa del modelo se divide de tal manera que cada proceso obtiene una porción, y cada proceso recibe un mini lote separado como entrada. Durante el paso hacia delante, cada proceso comparte su porción de la capa con los demás procesos. Al final de esta comunicación, cada proceso tiene ahora una copia de la capa completa del modelo.
Cada proceso calcula la salida de la capa para su mini lote. Después de que el proceso termine el cálculo para la capa dada y su mini lote, el proceso descarta las partes de la capa que no tenía originalmente.
El paso hacia atrás a través de los datos de entrenamiento se realiza de forma similar. Al igual que con el paralelismo de datos, los gradientes se acumulan al final de la pasada hacia atrás y se sincronizan entre procesos.
Los procesos de entrenamiento están más limitados en su rendimiento por la memoria que por la potencia de procesamiento, e incorporar más GPU con memoria adicional para manejar un lote que es demasiado grande para la memoria propia de la GPU puede causar un coste de rendimiento significativo debido a la velocidad de comunicación entre GPU, así como al coste de utilizar más procesadores de los que serían necesarios para ejecutar el proceso. Uno de los elementos clave de la biblioteca DeepSpeed es su Optimizador de Redundancia Cero (ZeRO), un conjunto de técnicas de utilización de la memoria que pueden paralelizar eficazmente el entrenamiento de modelos lingüísticos muy grandes. ZeRO puede reducir el consumo de memoria de cada GPU particionando los estados del modelo (optimizadores, gradientes y parámetros) entre los procesos de datos paralelizados, en lugar de duplicarlos en cada proceso.
El truco está en encontrar la combinación adecuada de enfoques de entrenamiento y optimizaciones para tu presupuesto computacional. Hay tres niveles seleccionables de partición en ZeRO:
- La etapa 1 de ZeRO divide el estado del optimizador.
- La fase 2 divide el optimizador + los gradientes.
- La etapa 3 divide el optimizador + los gradientes + los pesos del modelo.
Cada etapa tiene sus propias ventajas relativas. ZeRO Etapa 1 será más rápida, por ejemplo, pero requerirá más memoria que las Etapas 2 ó 3. Hay dos enfoques de inferencia distintos dentro del conjunto de herramientas DeepSpeed:
- DeepSpeed Inference: motor de inferencia con optimizaciones como la inyección en el núcleo; tiene menor latencia pero requiere más memoria.
- ZeRO Inference: permite descargar parámetros en la CPU o en la memoria NVMe durante la inferencia; esto tiene mayor latencia pero consume menos memoria de la GPU.
Nuestras contribuciones
El equipo de IA de Sophos ha creado un kit de herramientas basado en DeepSpeed que ayuda a simplificar su utilización. Aunque las partes del kit de herramientas en sí no son novedosas, lo que sí es nuevo es la comodidad de tener varios componentes clave sintetizados para facilitar su uso.
En el momento de su creación, este repositorio de herramientas fue el primero en combinar el entrenamiento y los dos tipos de inferencia de DeepSpeed (DeepSpeed Inference y ZeRO Inference) en un único script configurable. También fue el primer repositorio en crear un contenedor personalizado para ejecutar la última versión de DeepSpeed en SageMaker de Amazon Web Service. Y fue el primer repositorio en realizar inferencia DeepSpeed basada en scripts distribuidos que no se ejecutaban como endpoints en SageMaker. Los métodos de entrenamiento admitidos actualmente incluyen el preentrenamiento continuado, el ajuste fino supervisado y, por último, la optimización de preferencias.
El repositorio y su documentación se pueden encontrar aquí, en GitHub de Sophos.