Emotet ha sido uno de los servicios de ciberdelincuencia más profesionales y duraderos del panorama de las amenazas. Famoso desde poco después de su debut en 2014, el botnet fue interrumpido en enero de 2021 gracias a un esfuerzo multinacional de las fuerzas del orden que dejó de lado su actividad durante casi un año. Por desgracia, en noviembre de 2021 la red de bots resurgió y volvió a aparecer en el radar de Sophos.
Para proteger a nuestros clientes, SophosLabs siempre busca las técnicas, tácticas y procedimientos más significativos utilizados para distribuir y entregar Emotet. En este artículo, analizaremos el Control Flow Flattening (CFF), una de las diversas tácticas de ofuscación que utilizan los desarrolladores de Emotet para dificultar la detección y la ingeniería inversa de la carga útil del malware. Daremos un breve ejemplo de CFF aplicado a un simple programa de hola-mundo, y luego discutiremos cómo los investigadores de Sophos abordan el CFF en el código de Emotet. Terminaremos resumiendo los retos y problemas que hemos encontrado durante la investigación.
Los aspectos internos de Emotet han sido tratados por muchos investigadores, pero hasta ahora no hemos visto discusiones sobre su uso del Control Flow Flattening.
Emotet: Resurgimiento y tenacidad
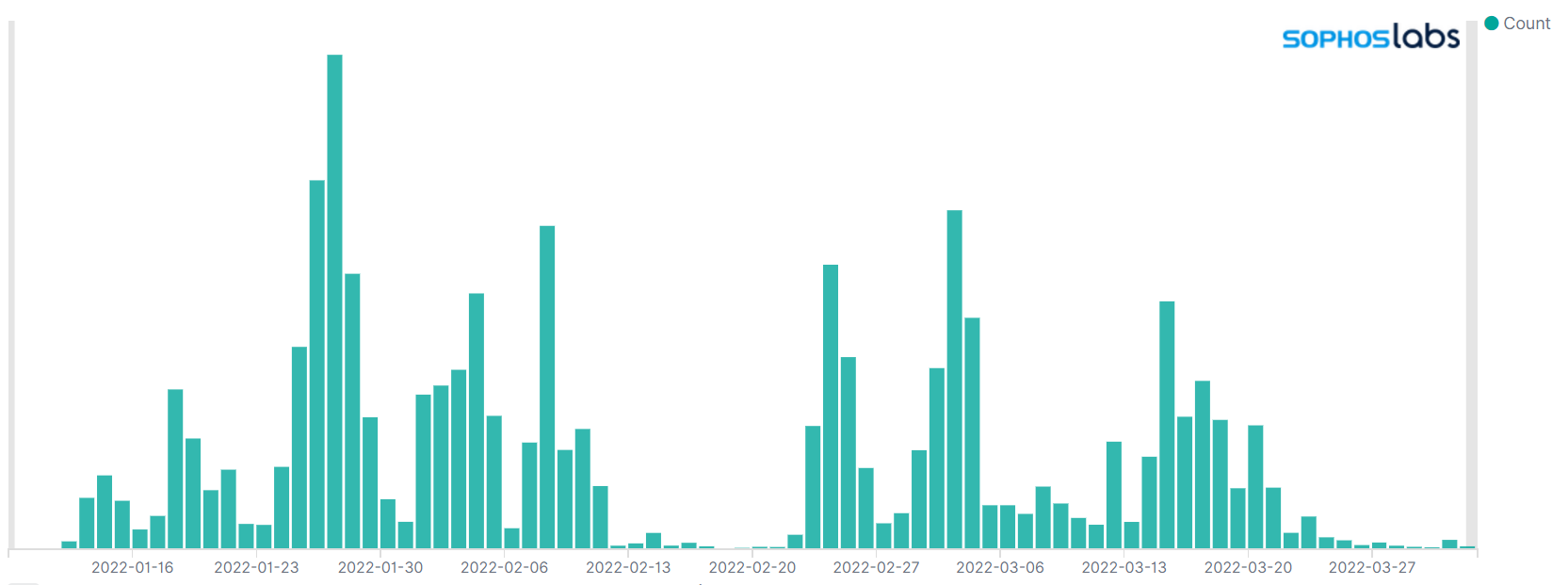
La figura 1 muestra el volumen de cargas útiles de Emotet detectadas en nuestros sistemas de sandbox en el primer trimestre de 2022. Como muestra el gráfico, recibimos múltiples envíos de Emotet a diario; creemos que los picos recurrentes más grandes son el resultado de campañas a gran escala puestas en marcha por los distribuidores del malware. Esta es una suposición sensata; Emotet se distribuye principalmente a través de spam de correo electrónico, y más correos electrónicos maliciosos naturalmente conducen a más envíos al sandbox.
Además del mecanismo de entrega de Emotet y su prevalencia, también analizamos en profundidad la carga útil final. Así, observamos el Control Flow Flattening en una muestra de Emotet sin empaquetar. El CFF oculta el flujo del programa poniendo todos los bloques de función uno al lado del otro. Es una conocida técnica de ofuscación utilizada para ocultar el propósito del software. Aunque extraer el código original de un binario aplanado es intrínsecamente difícil, hemos adaptado con éxito algunos conjuntos de herramientas existentes para desofuscar la mayor parte de la funcionalidad de la carga útil de Emotet.
¿Qué es el Control Flow Flattening?
El Control Flow Flattening es una técnica que pretende ofuscar el flujo del programa eliminando las estructuras ordenadas del programa a favor de colocar los bloques del programa dentro de un bucle con una única sentencia switch que controla el flujo del programa.
En primer lugar, el cuerpo de la función se divide en bloques básicos y, a continuación, los bloques se colocan uno al lado del otro en el mismo nivel. En la Figura 2 se puede ver una visualización de esta transformación. El Control Flow Flattening puede combinarse con otras técnicas de ofuscación, como el hashing de la API o el cifrado de cadenas. Algunos de los ofuscadores más destacados para aplanar funciones son OLLVM y Tigress.
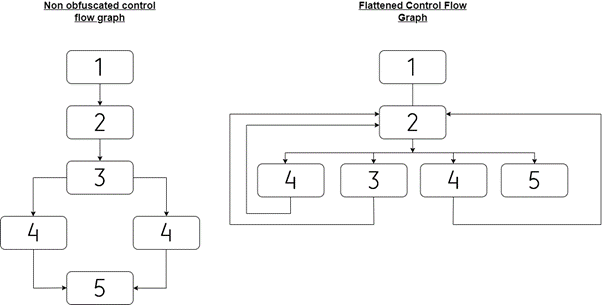
Echemos un vistazo a un ejemplo simplificado de CFF en acción.
Aplanando Hola Mundo
Para la demostración, hemos compilado un programa sencillo escrito en C. En la parte izquierda de la Figura 3, se muestra un gráfico de flujo de control (CFG) anotado del binario. En el lado derecho se puede ver la salida descompilada generada por el Descompilador Hex-Rays.
En esta figura no se han aplicado técnicas de ofuscación. El Descompilador Hex-Rays no tiene ningún problema en generar una representación de lenguaje de alto nivel fácil de leer del desensamblado. Incluso sin un descompilador, un ingeniero inverso experimentado puede simplemente seguir el gráfico de flujo de control para entender su propósito.

Ahora vamos a aplanar la función y comparar los resultados. La Figura 4 muestra el CFG y la salida descompilada después de aplicar el Control Flow Flattening. En el lado izquierdo, vemos que el número de bloques básicos se ha duplicado con creces, y la lectura de la salida descompilada ya no es posible sin dedicar una cantidad significativa de tiempo a su análisis.
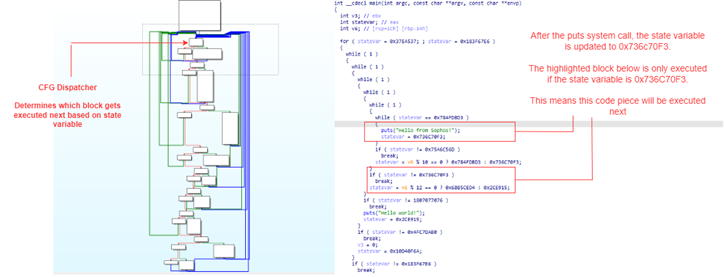
En general, el CFF introduce los siguientes problemas que dificultan nuestro análisis:
- El flujo de control está oculto. En lugar de poder seguir los bloques, se implementa un bloque despachador de flujo de control. Este bloque determina qué bloques se ejecutan a continuación.
- Una variable de estado anotada como stateVar en la salida descompilada se actualiza con variables de alta entropía a lo largo de la función. La variable de estado es utilizada por el despachador de flujo de control para decidir qué bloque se ejecuta a continuación.
- Los dos problemas anteriores conducen a una salida descompilada muy compleja. Aunque todavía es posible seguir el flujo de ejecución, el tiempo y el esfuerzo necesarios para entender la función es significativamente mayor que si se compara con la salida descompilada de la Figura 3.
Desaplanando Emotet
Para desofuscar el uso de Emotet del Control Flow Flattenin, comenzamos con una revisión de las herramientas existentes y la investigación sobre la desofuscación de CFG. Algunas de ellas son
- Hex-Rays Microcode API vs. Compilador de ofuscación por Rolf Rolles
- Defeating Compiler-Level Obfuscations used in APT10 Malware por VMWare’s Threat Analysis Unit
- Deobfuscation: recuperación de un programa protegido por OLLVM por Francis Gabriel de Quarkslab
- D810: A journey into control flow unflattening por Boris Batteaux de eShard
Para profundizar en el algoritmo que hay detrás del CFG Unflattening, los artículos citados anteriormente proporcionan una gran cantidad de información.
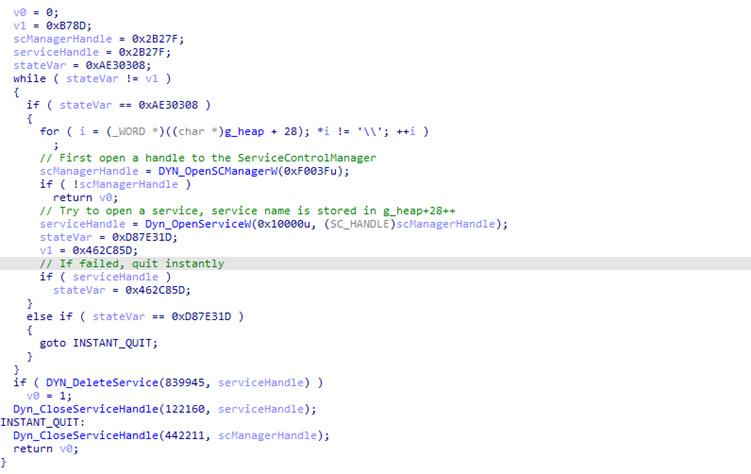
En la Figura 5 se puede ver la salida descompilada y la CFG de una función en una muestra de Emotet desempaquetada. Excluyendo el Aplanamiento del Flujo de Control aplicado aquí, la salida puede parecer confusa, porque Emotet aplica más de una técnica de ofuscación. (Si no estás familiarizado con esas otras técnicas, un apéndice al final de este artículo explica brevemente las otras técnicas de ofuscación).
En primer lugar, la función llama a OpenSCManagerA para obtener un handle del Service Control Manager. A continuación, llama a OpenServiceW para abrir un servicio existente. Si la apertura del servicio tiene éxito, el servicio abierto se eliminará mediante DeleteService. Por último, se cerrarán los handles abiertos. Si el servicio se ha eliminado con éxito, la función devuelve 1, en caso contrario 0.
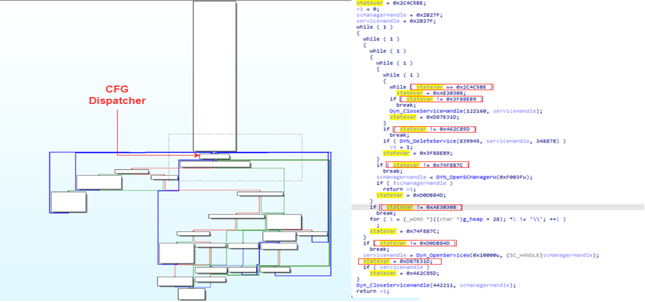
Si comparamos la salida descompilada de la Figura 3 y la Figura 4, podemos ver múltiples similitudes, y podemos identificar de nuevo el despachador CFG. En la salida descompilada, vemos una variable que anotamos como stateVar. Al igual que la salida de la Figura 3, esta es nuestra variable de estado que se actualiza constantemente y es utilizada por el despachador para determinar qué bloque se ejecuta a continuación.
En un nivel alto, si queremos restaurar el flujo de control, necesitamos:
- Identificar el bloque y los estados del despachador
- Para cada bloque, identificar la constante correspondiente y encontrar la dirección del siguiente bloque a ejecutar basado en el despachador y el valor de la variable de estado
- Parchear los bloques despachadores de salida para saltar a la dirección del siguiente bloque original
En lugar de parchear y operar en el desensamblado directamente, hacemos uso de la API de Microcode de Hex-Rays. Microcode es un lenguaje intermedio utilizado por el descompilador Hex-Rays. Durante la descompilación, el descompilador pasa por diferentes fases de maduración. Las diferentes fases se muestran en la figura 6. La API nos permite enganchar el progreso de la descompilación y operar en el microcódigo en lugar de parchear el desensamblado directamente.

Ajustando la herramienta
Utilizamos un fork de IDAPython de la herramienta HexRaysDeob de Rolf Rolles como base. Al igual que el fork, operamos únicamente con el nivel de madurez MMAT_LOCOPT, el tercer nivel de la figura anterior. Como se ve en la figura 6, ese nivel de madurez incluye información sobre los bloques de entrada y salida, que son necesarios para identificar correctamente los bloques de envío. Además, el código original se basaba en la capa MMAT_LOCOPT. Cambiar la capa habría requerido mucha más investigación, verificación y ajustes del código existente que mantener la capa. A continuación se resumen los cambios que aplicamos sobre el código base existente.
Manejo de despachadores múltiples/relacionados
En las funciones múltiples, la ejecución del algoritmo de desobstrucción en un solo despachador no generaba un resultado con el que estuviéramos satisfechos. El análisis demostró que las funciones más complejas podían contener múltiples despachadores anidados en lugar de uno. Hemos añadido una lógica adicional para identificar y ejecutar el algoritmo en múltiples emisores. Esta opción puede activarse o desactivarse ajustando el indicador RUN_MLTPL_DISPATCHERS a True o False. En la Figura 7, a continuación, se puede ver un ejemplo de una función con dos despachadores potenciales.
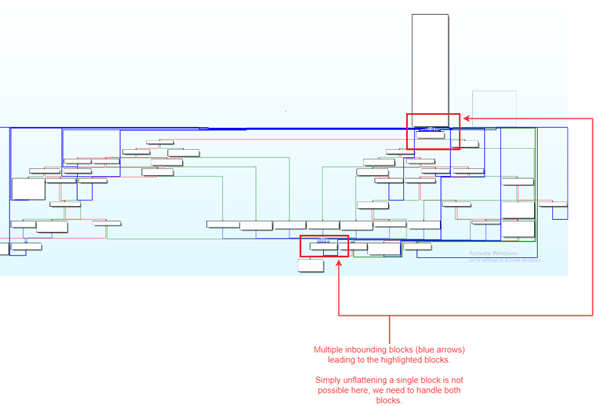
Búsqueda arriesgada del Cluster Head
Un bloque aplanado puede ser implementado por múltiples bloques de microcódigo. Para encontrar el final de la región, el algoritmo original de Rolf Rolles genera un árbol de dominadores y utiliza la información generada para determinar el final de una región, o el comienzo de un cluster. En algunos casos, el algoritmo no lograba encontrar la cabeza del clúster. Añadimos una función adicional para determinar el cluster head como recurso. Creemos que el algoritmo original de Rolf Rolles es más fiable; sin embargo, la evaluación demostró que el algoritmo de reserva seguía dando buenos resultados y mejoraba la salida descompilada.
Patrones adicionales y pequeñas actualizaciones de código
En algunos casos, la lógica existente fallaba a la hora de parchear todos los bloques aplanados. Tras analizar múltiples funciones, identificamos varios patrones que se repetían en todo el binario. Añadimos a la base de código existente una lógica adicional para identificar y desanclar los bloques que seguían estos patrones. Por último, ajustamos un poco el código general. Algunos de los cambios incluyen:
- El fork de IDAPython de la herramienta HexRaysDeob de Rolf Rolles estaba basado en Python2.7. Hemos actualizado varias partes del código para que se ajuste a los estándares de Python3.
- En la versión original de la herramienta, si la función “run” era invocada una vez, el plugin se activaba y si la herramienta determinaba la función como aplanada a través de un algoritmo, intentaba desanudarla. Durante la implementación y las pruebas, experimentamos caídas de IDA Pro al utilizar la API de microcódigo de IDAPython. Esto podría llevar a una base de datos IDB corrupta. Como un mecanismo de seguridad adicional, la dirección de la función objetivo debe ser añadida al array “white_list” para permitir el unflattening. En general, recomendamos guardar a menudo y mantener una copia separada de la BID cuando se utilice la herramienta.
De 254 funciones, clasificamos 68 funciones como aplanadas. De estas 68 funciones, pudimos desinstalar 38 con éxito. Diecinueve funciones fueron parcialmente aplanadas y 11 fallaron. Por “desinflado con éxito”, nos referimos a los casos en los que nuestro script no logró desinflamar un máximo de 3 estados. “Parcialmente desinflado” significa que la mayor parte de la función permanece aplanada, pero nuestra herramienta fue capaz de desinflamar algunos bloques. Por último, “fallido” significa que no hemos podido desofuscar ni un solo bloque de la función.
La Figura 8 muestra la función de la Figura 5 después de aplicar nuestro script.
IoCs
| Descripción | SHA256 |
| Emotet empaquetado | 9a0286ec0a3e7ea346759c9497c8b5c7c212fa2c780a1cabb094134bf492a51b |
| Emotet desempaquetado | 1bbce395c839c737fdc983534b963a1521ab9693a5b585f15b8a4950adea5973 |
Nuestra herramienta de desinstalación ya está disponible en el Github de SophosLabs. (Para quienes estén interesados en estas cosas, también recomendamos una herramienta de desempaquetado de CFF creada por ESET hace varios años para abordar el Control Flow Flattening en la red de bots Stantinko (otro ejemplo de por qué, ya que los atacantes comparten libremente tácticas, técnicas y procedimientos entre ellos, los defensores deben hacer lo mismo).
Conclusión y limitaciones
El Control Flow Flattening es un tema complejo, y el propósito de este artículo es compartir nuestra experiencia y resultados atacando el CFF de Emotet. Aunque hemos realizado múltiples ajustes y hemos tenido cierto éxito, nuestra solución no es capaz de desofuscar todas las funciones por completo. Entre las cuestiones pendientes:
- El algoritmo para detectar despachadores anidados es simple. Por ello, hemos añadido una opción para activarlo y desactivarlo. En algunos casos, se genera una salida defectuosa si el despachador anidado está activado.
- En muchas funciones, hemos tenido que tratar con estados condicionales. Dependiendo del resultado de, por ejemplo, una función WINAPI, la variable de estado cambia a un valor diferente en tiempo de ejecución. Se necesitaría un parcheado adicional y la inserción de instrucciones de microcódigo para desdoblar estos bloques condicionales.
- Nuestro enfoque principal era añadir lógica para los patrones recurrentes en el binario. A medida que nuestro trabajo avanzaba, nos dimos cuenta de que un emulador de microcódigo podría haber sido una mejor opción, o habría sido un ajuste que llevara a más bloques no aplanados.
- Durante el desarrollo y la evaluación, experimentamos múltiples caídas. Todos somos humanos y cometemos errores, por lo que algunas caídas serán consecuencia de fallos en nuestro código. Sin embargo, a juzgar por los mensajes de error, creemos que hay un problema más profundo en el puerto de Python de la API de Microcode. Por lo tanto, recomendamos guardar a menudo y conservar una copia del archivo IDB.
En general, recomendamos que los investigadores comprueben siempre sus resultados y no confíen ciegamente en la salida. El aplanamiento del flujo de control utilizado junto con otras técnicas de ofuscación ciertamente complica el proceso de ingeniería inversa de Emotet, pero la técnica que hemos descrito ayuda a igualar las probabilidades contra los investigadores que examinan este malware de alto perfil.
Apéndice: Emotet y la ofuscación de código
Al compartir la salida descompilada de las funciones en una muestra de Emotet, es imposible no encontrar otras técnicas de ofuscación de Emotet más allá de CFF. Este apéndice cubre las técnicas de ofuscación más prevalentes que hemos identificado en una muestra de Emotet descompilada. Ten en cuenta que Emotet suele entregarse empaquetado y necesita ser desempaquetado primero.
Cifrado de cadenas
Emotet contiene cadenas cifradas en su forma desempaquetada. Antes de su uso, las cadenas serán descifradas y liberadas de nuevo justo después de que cada una cumpla su propósito.
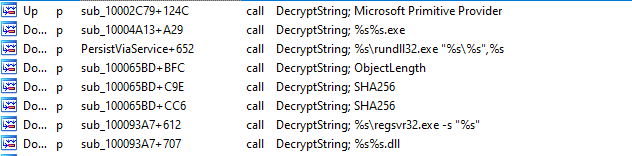
API Hashing
Emotet utiliza el hash de la API para ocultar el uso de las funciones de la API. El malware calcula el hash de los nombres de las funciones exportadas para una DLL determinada. Si el hash calculado coincide con la constante introducida en la pila al invocar el método, se recuperará el puntero a la función exportada.
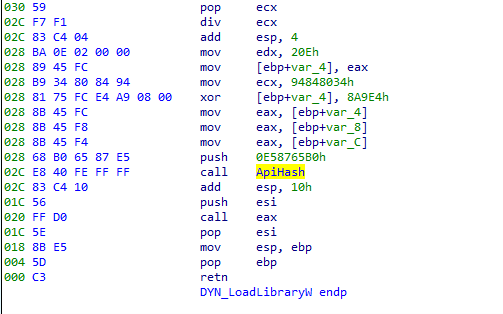
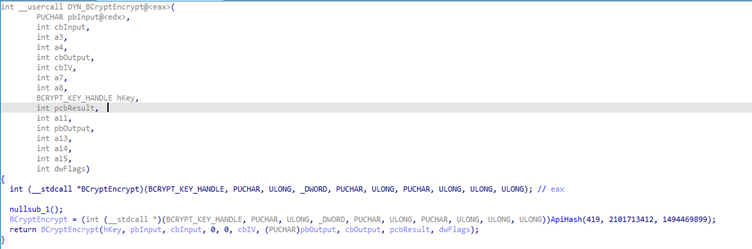
En la mayoría de los casos, las llamadas a la API Hashing y su correspondiente llamada dinámica están envueltas en funciones separadas. Hemos automatizado este análisis, y las funciones con el prefijo DYN_ son funciones determinadas en tiempo de ejecución mediante API Hashing.
Instrucciones basura
Emotet incorpora instrucciones basura para confundir a los ingenieros inversos. Las instrucciones basura son instrucciones que no sirven para nada, excepto para complicar y ralentizar el análisis. La Figura 11 muestra un ejemplo de un bloque de instrucciones basura.

Ofuscación de la pila
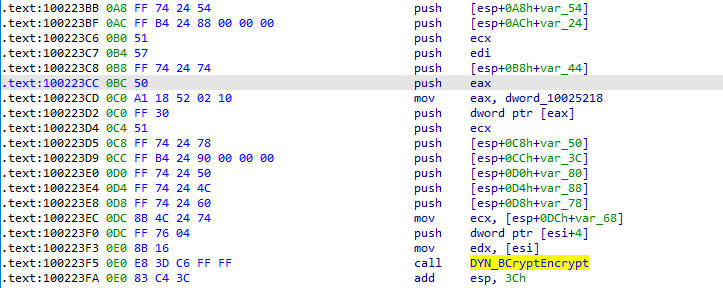
Otra técnica interesante que confunde al descompilador IDA es la forma en que Emotet pasa los parámetros a las funciones. En la Figura 12, mostramos cómo se invoca DYN_BCryptEncrypt.
DYN_BCryptEncrypt primero resuelve la función de la API BCryptEncrypt y almacena el puntero a esta función en el registro EAX. A continuación, se llama a la función mediante la llamada EAX. En lugar de limitarse a introducir los parámetros necesarios, este método introduce valores en la pila que no son utilizados por la llamada EAX real. Esto lleva a la generación de una firma de función que es mucho más difícil de leer de lo normal.