La inversión de Sophos en la investigación del aprendizaje profundo (deep learning) es un compromiso para proteger a nuestros clientes utilizando los últimos avances científicos, reconociendo que el aprendizaje automático es el futuro de la industria.
Cuando nuestra experiencia en aprendizaje profundo se combina con nuestro historial protección de endpoints, esto nos posiciona como líderes en el mercado de herramientas de detección de próxima generación.
Con el objetivo final de: mantener a nuestros clientes protegidos de las amenazas en evolución.
Entendiendo diferencias entre Machine Learning y Deep Learning
En Sophos nos enfocamos en Deep Learning, la cual es una forma avanzada de Machine Learning.
Como no todos los modelos de aprendizaje son iguales, explicare cual es el nuestro y sus diferenciales.
El proceso para desarrollar un modelo de aprendizaje profundo (deep learning), incluye la recopilación de grandes cantidades de datos, la ingeniería de características del dominio, la construcción de la arquitectura, el entrenamiento del modelo, la prueba del modelo y la evaluación del modelo.
El modelo de deep learning es mas similar al cerebro humano porque involucra muchas capas neuronales.
De hecho el termino “red neural artificial” viene de este concepto ya que “artificial” es porque es una imitación de la red neuronal del cerebro.
Tanto una red neuronal en el cerebro como una red artificial lo que hacen es tomar una entrada, manipularla de alguna manera y envíar información a otras neuronas.
Como cada nuevo concepto nos profundiza en el aprendizaje de nuevos términos. Red neuronal artificial (artificial neural Network) es uno de ellos, por lo que si estamos hablando de aprendizaje profundo, bucemos en estos nuevos conceptos. :)
¿Que es una Red Neuronal Artificial?
Una Red Nueronal Artificial (o como lo encontraremos en ingles ANN) consiste de capas formadas por neuronas interconectadas que reciben un conjunto de entradas y un conjunto de pesos. Luego se realizan ciertas manipulaciones matemáticas y saca los resultados como un conjunto de “activaciones” que son similares a las sinapsis en las neuronas biológicas.
A nivel macro, una red neuronal consta de cuatro componentes:
- neuronas, por supuesto
- topología: la ruta de conectividad entre las neuronas
- pesos, y
- un algoritmo de aprendizaje.
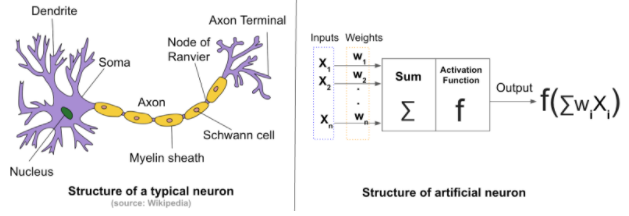
Tanto una red neuronal en el cerebro como una red artificial lo que hacen es tomar una entrada, manipulan la entrada de alguna manera y envían información a otras neuronas.
Una Red Neuronal Artificial (ANN) también pueden aprender basándose en una representación preexistente. Este proceso se llama ajuste fino y consiste en ajustar los pesos de una topología de red entrenada previamente a una velocidad de aprendizaje relativamente lenta para obtener un buen rendimiento en los datos de entrenamiento de entrada recién suministrados.
Ya sea que esté entrenando desde cero o afinando, el proceso de actualización de peso comienza pasando los datos a través de la red neuronal, midiendo el resultado y modificando los pesos en consecuencia. Este proceso general es cómo una red neuronal artificial “aprende”. Los pesos se empujan gradualmente en las direcciones que más aumentan el rendimiento de la tarea deseada, por ejemplo, maximizar la precisión de reconocimiento, en las muestras de entrada. Esta noción de aprendizaje se puede comparar con un niño que intenta aprender a reconocer los objetos cotidianos. Después de intentos fallidos y comentarios sobre la precisión de la respuesta, el niño intenta nuevamente en una dirección diferente para lograr la respuesta correcta. Una ANN realiza la misma tarea al aprender. Se alimenta de estímulos que tienen respuestas conocidas y un régimen de aprendizaje ajusta los pesos para maximizar el número de respuestas precisas que resultan de alimentar los nuevos estímulos de ANN.
Una vez que se completa este proceso de aprendizaje, tanto el niño como la ANN pueden usar sus representaciones previas de los problemas para elaborar respuestas a nuevos estímulos a los que no han estado expuestos previamente en el proceso de aprendizaje.
Capacitamos a esta ANN a través de un régimen supervisado, proporcionándole muchos archivos PE con etiquetas conocidas (maliciosas / benignas) y utilizamos un proceso de optimización matemática para ajustar los pesos y diferenciar entre archivos maliciosos y benignos.
En resumen
El aprendizaje profundo (deep learning) generalmente se refiere a tres componentes principales que, cuando se combinan entre sí, permiten la creación de modelos predictivos muy potentes:
- Un gráfico conectado de capas en el que cada capa toma datos de una capa principal, mezcla los datos de una forma predefinida y los envía a la siguiente capa en el gráfico
- Una función de pérdida que mide qué tan preciso es el modelo cuando hace sus predicciones
- Un algoritmo que optimiza la función de pérdida y el conjunto de datos entrenado
Hemos discutido aquí los desafíos de detectar contenido malicioso y cómo machine learning es una herramienta complementaria que puede ayudar a abordar estos desafíos. A diferencia de otros métodos tradicionales de listas negras y firmas escritas a mano para detectar malware, el aprendizaje automático resuelve estos desafíos al ofrecer un sistema automatizado de bajo mantenimiento y al capturar una mayor distribución de malware.
Otro punto interesante de nuestra tecnología de Deep Learning, es que las máquinas de los clientes no necesitan estar conectadas a Internet para recibir actualizaciones todos los días para estar protegidos. Con el aprendizaje profundo, las actualizaciones son solo modelos recién entrenados basados en las mismas técnicas de ingeniería de características; por lo tanto, podemos mejorar continuamente la arquitectura de nuestro modelo sin rediseñar sus características. Las características se extraen de forma continua y fácil sin requerir cambios en nuestro método de recopilación, y los cambios en el modelo en sí son en gran medida innecesarios. Simplemente reciclamos el modelo para que pueda predecir cuál será el próximo en el paisaje actual.
Anexo
Apartado sobre preguntas sobre Machine Learning para entender que tan eficiente es la tecnología de proveedor.
¿Cual es la tasa de falsos positivos?
Solo con citar las tasas de detección de los algoritmos de aprendizaje de la máquina no es suficiente.
Después de todo, puede trivialmente lograr una tasa de detección del 100% simplemente declarando como malicioso cada archivo que escanee. Pero su tasa de falsos positivos -es decir, cuando impida erróneamente que se utilicen archivos legítimos- estará cerca del 100% también
En otras palabras, la tasa de falsos positivos para el algoritmo de detección es al menos tan importante como su tasa de detección verdadera. Ignorar la tasa de falsos positivos significa perseguir constantemente a los fantasmas en la red o interrumpir el trabajo de sus usuarios.
Si el proveedor no puede o no quiere mostrar una curva ROC, ni siquiera puede empezar a adivinar la baja tasa de detección que necesitará tolerar, es decir, cuánto malware el producto dejará pasar, Antes de que sea tolerable de usar.
Qué preguntar: ¿Puedo ver sus curvas ROC, ahora y desde el pasado?
El verdadero poder de machine learning es que, si está debidamente capacitado, puede detectar de forma fiable las amenazas que no ha visto antes. Esto lo hace especialmente efectivo para bloquear nuevas amenazas proactivamente.
Qué preguntar: ¿Su algoritmo de machine learning toma decisiones en tiempo real?
El conjunto de datos debe ser lo suficientemente compacto para que pueda mantenerse en la memoria, evitando así la necesidad de mantener la lectura de datos de detección fuera del disco a medida que se escanea cada archivo.
Qué preguntar: ¿Es en tiempo real? Si es así, ¿cuánto tiempo toma una decisión? ¿Qué pasa con el rendimiento y la precisión si el equipo está fuera de línea?
Q3. ¿Cuál es su conjunto de entrenamiento?
Qué preguntar: ¿De dónde provienen los datos de entrenamiento? ¿Qué lo hace realista? ¿Cuántos datos hay? ¿Cómo mantiene actualizados los conjuntos de entrenamiento?
Leave a Reply