
The venerable Apache web server has just been updated to fix a dangerous remote code execution (RCE) bug.
This bug is already both widely-known and trivial to exploit, with examples now circulating freely on Twitter, and a single, innocent-looking web request aimed at your server could be enough for an attacker to take it over completely.
Estimates of Apache’s prevalence vary, but a good guess is that somewhere between a quarter and a third of internet-facing web services will end up getting handled by an instance of Apache.
Remember that even if you don’t run your organisation’s public-facing web servers on Apache (perhaps you use the popular nginx product on Unix, or Microsoft IIS on Windows), you may nevertheless have Apache running somewhere on your network.
Indeed, any software product that has its own HTTP interface, such as a document management system or a support ticketing system, might, for all you know, be using Apache as its built-in web server.
You should therefore review your network not just for traditional web servers made for external visitors, but also for HTTP servers inside your network that cybercriminals such as ransomware gangs could use to extend or expand an attack that is already underway.
Intriguingly, given the nature of the bug, this flaw, dubbed CVE-2021-41773, was introduced less than a month ago, in Apache 2.4.49.
Ironically, this means that Apache users who were sloppy about updating last time, and are still back on 2.4.48 or earlier, will skip over this vulnerability altogether.
To patch against the bug, upgrade immediately to Apache 2.4.51. (If you already updated to 2.4.50, we’re sorry to have to tell you to update again to 2.4.51.)
Update. The 2.4.50 patch, which we perhaps uncharitably referred to as “clumsy” below, turns out to have been inadequate. As far as we can tell from reviewing the patch to the patch, the 2.4.50 code could still allowed deviously encoded URLs to slip through. Upgrade immediately to Apache 2.4.51. [2021-10-08T13:00Z]
Path traversal explained
When we first heard about CVE-2021-41773, documented as a “path traversal and file disclosure vulnerability”, we assumed that the flaw had been lying around unnoticed in the Apache code for years.
That’s because path traversal bugs are very last-century, and many path validation flaws in contemporary code turn out to be programming artefacts left over from a less careful age.
Simply put, a path traversal bug happens when a user tries to access a file on the server that ought to be blocked, but the security check on the filename fails.
This programming mistake is easy to make because there are many different ways of referring to the same file, and you have to take all of them into account.
For example, let’s assume that you are currently sitting in a directory called /home/duck (the equivalent of C:\Users\duck on Windows), where you have placed a file called findme.txt.
Canonically, which is the jargon term for “the one true way to do it”, you’d refer to this file as:
/home/duck/findme.txt
If you wanted to make certain that this file really was located in the /home/duck directory, the obvious programmatic way to do it would simply be to check that the full filename starts with /home/duck/, for example like this:

But this isn’t good enough, because all major filing systems on all major operating systems allow you to have filenames that “jump around” inside the directory tree, for example like this:
/home/duck/subdir1/subdir2/../../findme.txt /home/duck/../../etc/passwd
In directory names, dot-dot is shorthand for “go up a directory”, so that in the first filename above, subdir1/subdir2/ descends two levels deeper into the directory tree, while the ../../ that follows goes back up again by two levels.
In other words, every instance of ../ in a filename essentially cancels out the directory name that immediately precedes it in the path.
Our simplistic isfilewithinpath() function would conclude that the files findme.txt and passwd above were both safely contained underneath the “root path” of /home/duck/, because both paths start with exactly that text string.
But only the first file is actually under /home/duck/, because those names simplify to…
/home/duck/subdir1/../findme.txt /home/../etc/passwd
…which in turn simplify, or canonicalise, to:
/home/duck/findme.txt /etc/passwd
One of them is our very own findme.txt file, safely stashed in our own directory tree, while the other is the central Unix/Linux password file from the system directory /etc.
(On modern systems, the passwd file is a bit of a misnomer: it does contain usernames, but for security reasons it hasn’t contained passwords or even password hashes for many decades, just in case you were wondering.)
In fact, you can even use dot-dot as a sort of escape-completely-from-anywhere mechanism, because when you reach the root directory of the system itself, typically / on Unix or C:\ on Windows, every subsequent dot-dot gets ignored, like this:
/home/duck/findme.txt --> /home/duck/findme.txt /home/duck/../findme.txt --> /home/findme.txt /home/duck/../../findme.txt --> /findme.txt /home/duck/../../../../findme.txt --> /findme.txt <-- we've hit the ceiling and now we simply stay there (no errors) /home/duck/../../../../../findme.txt --> /findme.txt
In other words, you don’t have to know your exact place in the directory hierarchy to escape to any other specific subdirectory, as long as you put plenty of dot-dot-slash entries in the filename.
In particular, you won’t cause an error if you accidentally have more dot-dots than are strictly necessary.
Try the command below on a Windows computer from almost anywhere on the C: drive, and you will print out the hosts file (a list of IP number overrides for specific server names, often used by legitimate users to block annoying ad networks, and by malware to block useful cybersecurity websites).
Note that this filename is an innocent-looking relative filename (because it doesn’t explicitly denote a hard-wired path that it wants to use), but thanks to the dot-dot-slash trickery, it effectively acts as an absolute pathname.
The dot-dots launch you upwards until you reach C:\, where you just bounce repeatedly off the ceiling and stay in C:\ until the path starts descending again to to the desired finishing point:
-- I went three levels down in my own home directory: C:\Users\duck\test\subdir1\subdir2> type ..\..\..\..\..\..\..\..\..\..\Windows\System32\drivers\etc\hosts -- But even using a non-absolute path I traversed predictably to the Windows directory: # Copyright (c) 1993-2009 Microsoft Corp. # # This is a sample HOSTS file used by Microsoft TCP/IP for Windows. [. . .] # For example: # # 102.54.94.97 rhino.acme.com # source server # 38.25.63.10 x.acme.com # x client host # localhost name resolution is handled within DNS itself. # 127.0.0.1 localhost # ::1 localhost
All security conscious software, especially including web servers, needs to be on the lookout for this sort of dot-dot trickery.
Path traversal treachery can allow attackers to specify filenames that look as though they’re in a harmless location, and that the attackers are therefore able to read in, or perhaps even to write to or execute, when they aren’t supposed to see those files at all.
If we wanted to look out for dot-dot treachery in a URL, we would need to look out for double-dots and react accordingly, for example like this, where we loop through the path string to see if the untrustworthy substring ../ appears at any point:

But this is not a strict enough test for a web server, because URLs that include file and path names can be encoded using what are known as URL escape sequences.
URL escapes represent ASCII characters that would otherwise be illegal in URLs by converting them into a percent sign followed by two hexadecimal digits to represent the ASCII code.
You can’t have spaces in a URL, for example, so if you want to use a filename or directory name that includes a space as part of a URL, you have to transmit each space as %20, short for “replace this with ASCII hex code 0x20 (decimal 32)”, which denotes a space character.

%2E (dot) highlighted in red.
Even if a character in a URL doesn’t need escaping, you can generally escape it anyway in your web request, and the server at the other end will decode it and use it correctly, as you will find if you try either or both of these commands:
$ curl -D - https://nakedsecurity.sophos.com/podcast/ $ curl -D - https://nakedsecurity.sophos.com/%70%6F%64%63%61%73%74/
The URL path in the second command above is just the word podcast converted into URL escape codes using the table above.
So, to detect the appearance of the dot-dot sequence in a URL path, you really need to look for any or all of the following different ways of encoding it:
. . <-- both dots can be represented literally as themselves %2E . <-- or the first dot alone can be escaped %2e . <-- and note that URL escapes can use upper or lower case hex digits . %2E <-- or the second dot alone can be escaped . %2e %2E %2E <-- or they can both be escaped %2e %2E %2e %2E %2e %2e
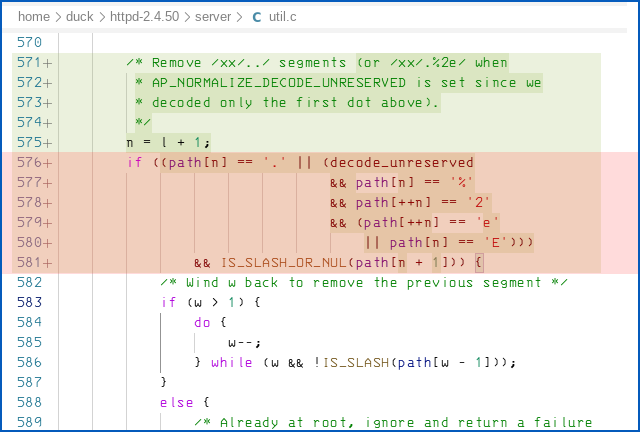
The CVE-2021-41733 bug introduced in Apache 2.4.49 was new code added to normalise, or canonicalise, URL paths to remove inconsistent, unnecessary or dangerous parts of the pathname…
..but (as far as we can see) the code only correctly detected the first three cases above, where either both dots were sent unescaped, or only the first dot was escaped.
By encoding the second dot as %2E, you could bypass the dot-dot check and thus exploit this aptly-named path traversal vulnerability.
Initial reports correctly implied that this bug was exploitable for reading files that were off-limits, including accessing files outside the web server’s own directory tree, as well as downloading script and other source code files inside the server tree that were not supposed to be directly accessible to website visitors.
That’s bad enough, but it turns out that by asking for a rogue file, for example by trying to access the system’s shell interpreter, and at the same time supplying a rogue HTTP header in your request, you may be able not only to execute arbitrary programs on the server, but also to pass arbitrary parameters (command line options) to those programs.
When you have remote, unauthenticated access to a command shell like bash, and you can send it any commands you like via a simple HTTP request, you pretty much have a generic server “backdoor”, and you have pwned the system completely.
What to do?
- If you have Apache 2.4.49 or 2.4.50, you need to update right away to Apache 2.4.51 if you haven’t already. This bug is widely-known and sample code to abuse it is widely available online. (Note that the first patch for this bug, 2.4.50, was itself buggy and did not properly patch the problem.)
- If you have older version of Apache, you aren’t affected by this bug. Ironically, perhaps, if you were slow to update last time (2.4.49 came out on 15 September 2021) then your sluggishness has protected you this time.
- Don’t just patch this hole on internet-facing web servers. Do the publicly exposed ones first, because that’s where your immediate danger lies. But expect cybercrooks to adopt this exploit as a “lateral movement” trick once they already have a beachhead inside a network, because it’s so easy to abuse.
- If in doubt whether any of the web-enabled software you use includes Apache, ask your vendor. If you have network scanning tools such as Nmap available, you can probe for HTTP or HTTPS servers on your own network and check their reply headers, which often reveal the server code in use, notably in the
Server:header.
EXAMPLE CURL COMMANDS TO LOOK FOR APACHE
If you know the server name (or IP number) and port number of HTTP or HTTPS services on your network, you can look at the headers that come back when you send a basic web request to it, as you see here:
$ curl --http-1.1 --head https://nakedsecurity.sophos.com/ HTTP/1.1 200 OK Server: nginx <-- We're using Nginx Date: Wed, 06 Oct 2021 17:19:46 GMT Content-Type: text/html; charset=UTF-8 [. . . ] $ curl --http1.1 --head https://www.apache.org HTTP/1.1 200 OK Connection: keep-alive Content-Length: 73991 Server: Apache <-- As you would expect! [. . .] $ curl --http1.1 --head https://127.0.0.1:8888 HTTP/1.1 501 Not implmemented Server: Lua-TLS-Generic <-- Local test server I use for articles Connection: close Content-Type: text/plain [. . .]
Some results may be inconclusive because they don’t return a Server: header, like the excellent, free Fossil source code management tool that we use for our sample code.
This product has a web server that doesn’t use Apache, but doesn’t have a server tag of its own:
$ fossil ui Listening for HTTP requests on TCP port 8080 [. . .] $ curl --http1.1 --head http://127.0.0.1:8080 HTTP/1.0 302 Moved Temporarily Date: Wed, 6 Oct 2021 17:23:52 +0000 Connection: close X-Frame-Options: SAMEORIGIN [. . .]
Likewise, some servers may deliberately choose to identify themselves as something other than they really are, either as a decoy to mislead naive network scanners that routinely hurl unwanted exploit “tests” at them, or for compatibility reasons with client apps that expect a specific vendor’s product at the other end.
Grammar Pedant
> Canonically, which is the jargon term for “the one true way to do it”
“Canonical” is not jargon, it’s a perfectly good english word dating back to the 15th century
https://www.merriam-webster.com/dictionary/canon
https://www.merriam-webster.com/dictionary/canonical
Paul Ducklin
I think it’s entirely apposite to refer to it as jargon when it’s applied to the conversion of input data or file structure when programming, in the same way that calling software a “program” and referring to its “execution” can be called jargon.
The fact that a word has been in our lexicon for centuries doesn’t mean, every time it gets appropriated, borrowed, redefined, metonymised (and if that is not a word it should be) or jammed without regard for shape or sensitivity into a new usage, that the new usage is exempt from being considered “jargon”.
“Canonical” in its traditional metaphorical, non-religious meaning (I defer to the Oxford lexicographers, never had much time for Noah Webster and his inconsistent, incomplete and apparently purposeless attempts at spelling reform) simply asserts that something is “accurate and authoritative”.
In computer science, “canonicalisation” (now often shortened, presumably in the manner that “certificated” became “certified” and “orientated” became “oriented”, simply to “canonisation”, something else entirely in Church terminology!) generally refers to the act of converting something that might already be described as accurate and authoritative into an alternative and supposedly standardised form.
In other words, canonisation in computer terms doesn’t mean agreeing that a dead person can now officially be called “Saint”, but instead typically refers to an algorithmic transformation that aims to remove redundancy and enforce standardisation, possibly even with some loss of information along the way. (Removing whitespace, converting tabs to spaces as they jolly well ought to be, rewriting source code to fit liturgical rules, like Go does – there’s a jargonistic use of “liturgical” that I couldn’t resist – and so on.)
So I’m happy to consider this a jargon term in this context.
Dave P
Is there a live discover script to locate servers, appliances, devices that could be running Apache?
Paul Ducklin
I don’t have one (but if I see one turn up on our Community forum, I’ll let you know).
A quick solution for Linux servers might be to use the presence of a directory called /etc/httpd/httpd.conf or /etc/httpd/conf/httpd.conf as a flag that Apache is probably installed, and the presence of a running process called httpd as a flag that it’s active. Or, depending on your distro, you could use your distro-specific package manager to look for whatever name your distro uses for its Apache package.
For example, I use Slackware, and the output of the command slackpkg info httpd (which is how Apache is usually known, short for “HTTP daemon”) will tell you if it’s there, and if so give info about it, including the current version. As you can see, mine is up-to-date:
# slackpkg info httpd
PACKAGE NAME: httpd-2.4.50-x86_64-1.txz
[. . .]
PACKAGE DESCRIPTION:
httpd: httpd (The Apache HTTP Server)
[. . .]
I do have a file called /etc/httpd/httpd.conf, which is an indicator that Apache could probably be started if it were asked, but I don’t have a process called httpd running because I don’t host a webserver on my regular computer.
A good place to look/learn/ask, if you haven’t tried it already, is:
https://community.sophos.com/intercept-x-endpoint/p/query-forum
Alan
Just to update this article for anyone reading it after the intial version was published, updating to 2.4.50 is no longer sufficient – you need to go to 2.4.51 to protect against this vulnerability.
See https://downloads.apache.org/httpd/CHANGES_2.4.51
Paul Ducklin
Thanks! I’m in the process of writing that up and will update this one accordingly in a moment. (Not sure whether to use a smiley emoji or a saddo symbol.)
PS. I am no longer wondering if I should feel uncharitable for the word “clumsy” above.
PPS. The update-your-update article is complete:
https://nakedsecurity.sophos.com/2021/10/08/apache-patch-proves-patchy-now-you-need-to-patch-the-patch/