


Personal data breaches have become a plague worldwide, but have been an especially massive problem in South Korea.
So massive, in fact, with so many ID numbers stolen over the years, that the country is even thinking about reissuing ID numbers to everyone.
Estimates for the cost of a new ID system, including reissuing ID cards and implementing new government systems, have run as high as ₩700 billion (more than $6 billion).
But even a brand new ID number – or Resident Registration Number (RRN), as it’s known in South Korea – won’t protect you from having your privacy ruined if a commercial organization, acting legally and in good faith, reveals your identity as part of a badly-implemented “anonymous” data dump.
AOL famously published several months of anonymized search data back in 2006, no doubt to the legitimate delight of researchers in the social sciences.
But a curious journalist quickly worked backwards from the search terms to the precise identity of one of the not-so-anonymous users.
AOL may have changed her name to 4417749 everywhere it appeared in the published data, but the combination of what she’d searched for soon unravelled her real name and even her address.
A similar sort of blunder was committed, albeit in a slightly different way, by the New York City Taxi and Limousine Commission in 2013/2014.
Anonymized taxicab trip data was published, with drivers’ medallion numbers converted by simply shoving them through one loop of the cryptographic hash function MD5.
That sounds as though it should be safe, because you can’t go directly backwards from a hash like 1effbd5e773e026650b9137434759c92 to the medallion number.
But medallion numbers have a special format, and there are only 18 million possible medallions in total (and far fewer than that actually issued), so it’s a matter of a few seconds to produce a definitive lookup table of all possible medallion numbers and their hashes.
→ Want to win a techie T-shirt? Be the first to publish a comment containing the medallion number that gives the hash above! (We’ll need an email address to contact you if you win. FYI: here are our official Ts-and-Cs.)
Of course, once you have constructed the lookup table, you can go instantly backwards from any valid hash to the associated medallion.
The Korean connection
A pair of researchers at Harvard University wondered if similar problems might exist for South Koreans, whose RRNs are used as database indexes in all walks of life, such as applying for a credit card, looking for a job, paying taxes, and using medical services.
In particular, anonymized medical prescription data on millions of living South Koreans is shared with IMS Health, a large multinational corporation headquartered in the United States.
Could these supposdely-anonymous records be wrangled backwards to reveal that abcdefghjiklm, say, who’s been taking protease inhibitors and reverse transcriptase inhibitors for the past decade, is, in fact, Mr Hong Gildong of Incheon?
As the researchers note, this is an issue of real concern in South Korea:
In February 2013, approximately 1,200 physicians and 900 private individuals filed a civil lawsuit against IMS Health, a large multinational corporation, for collecting the medical data and RRNs of millions of living South Koreans. IMS Health claims that it does not violate the privacy of South Koreans, in part because the RRNs are encrypted and cannot be decrypted by any reasonable means. Is this correct? Is it possible to decrypt these RRNs and associate actual RRNs with the medical information of patients to whom they belong?
So the researchers looked at available anonymized prescription data on deceased South Koreans, which they claim resembles the data supplied to IMS Health.


The results were shocking.
The data included 23,163 allegedly-anonymized RRNs, and with very little effort, the researchers de-anonymized the lot.
Actually, it’s much, much worse than that.
The researchers figured out that the anonymization was, in fact, a trivial subsitution cipher, where the digits of the RRN are converted into letters in the sort of “encryption” process that many Naked Security readers probably first played around with in elementary school:
As a cryptosystem, our experiments exposed a simple substitution cipher. Each digit is replaced with a lowercase letter using different substitutions for even and odd digit positions.
So, unlike the AOL de-anonymization, there was no need to look for patterns or hints in the data entries associated with each person; and unlike the NYC Taxi data, the researchers didn’t even need a lookup table.
In simple cryptographic terms, the RRNs were hashed reversibly.
We’ve warned many times on Naked Security that you should never knit your own cryptography, and this is just another sorry example of why.
What to do?
The researchers suggest that the predictability of South Korean RRNs is part of the problem, for example because they start with your date of birth in the form YYMMDD, and continue with yet more personal and demographic data.
They propose that a more random selection of RRN values in any new identity system might be a way to improve the anonymity of anonymized data:
Randomization would have made our effort much more difficult, if not impossible, even using the same encryption scheme.
Actually, the fact that South Korean IDs needlessly embed additional personal data, and are thus ideal for social engineering purposes, is an entirely separate issue.
Even if every South Korean had a 64-character random string for an ID, that string would still be a unique identifier, so any anonymizing process that was reversible would be unacceptable.
The researchers also naively suggested using a straight cryptographic hash:
If the recipient of the data should be unable to decrypt the encrypted RRNs, then a better approach is one that is easy to encrypt but hard to decrypt. This suggests the use of a strong hash function such as MD5 and not encryption.
Two problems here.
Firstly, MD5 is no longer considered a strong hash, and you shouldn’t use it at all these days.
Secondly, as the NYC Taxi and Limousine incdent showed, even using a strong hash means that anyone with their own list of RRNs can find out which of those identities appear in any “anonymous” list, which is also unacceptable.
One workable solution is to use a keyed cryptographic hash, such as HMAC or AES-GCM.
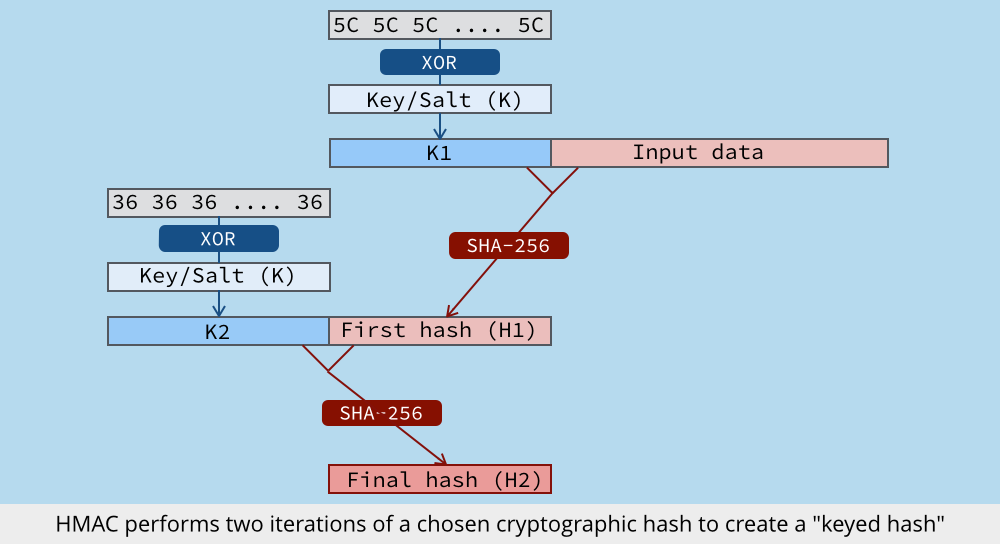

This not only scrambles the identifiers in an irreversible way, but mixes a cryptographic key into the scrambling process so that you can’t later re-compute the hash unless you have the key. (The key acts as a sort of global salt for the bulk hashing process.)
Two records with the same identifier will come out with the same keyed hash, so that the hash can still be used as an index for the data, as desired.
Then, before publishing the anonymized data, destroy the key.
That way, no-one can work backwards from the list of hashes to the original identifiers; and no-one can work forwards from a list of identifiers to the published hashes.
Image of slightly moody image of doctor-type choosing medication courtesy of Shutterstock.