Dépassement de la mémoire tampon : la KeyStore story !
Avec l’aimable autorisation d’IBM, voici un récit visant à vous mettre en garde concernant un bug.
Pour clarifier, IBM a eu ce bug : Google également, et les experts d’IBM ont fini par le détecter.
De la même façon que le serial SNAFUs de Google, concernant le contrôleur de cryptage d’Android l’an dernier, ce bug présente un certain intérêt car, ironiquement, il a été détecté dans une zone sécurisée d’Android, appelé KeyStore.

Pourquoi KeyStore ?
Si vous vous êtes déjà demandé comment les applications Android gardaient les clés cryptographiques en sécurité, alors vous vous êtes posé une très bonne question !
Il est vrai que toutes les applications pour mobiles forment une sorte d’écosystème, qui a engendré des comportements dangereux et choquants. Ces comportements ne viennent pas de vous, les utilisateurs, mais plutôt des fournisseurs de logiciels eux-mêmes.
Par exemple, SnapChat, déclarait que vos photos osées, disparaîtraient après le premier visionnement. Cependant ils n’ont même pas pris la peine d’effacer les images du téléphone du destinataire, et ce bien avant que vous ne découvriez que cette promesse était en fait bidon.
WhatsApp a, courageusement, essayé d’ajouter une couche de cryptage à vos messages, mais a plutôt inventé un magnifique crypto-système défectueux, qui a abouti à une protection unique, à utiliser 2 fois (ce n’est pas pour rien qu’elle s’appelle « one-time pad » !).
De plus un sondage de janvier 2014 a montré que 40% des applications bancaires en ligne (logiciels officiellement recommandés par des institutions financières, pour la réalisation de vos transactions bancaires sécurisées), ne prennent pas la peine de vérifier les certificats HTTPS, et peuvent ainsi être dupées par n’importe quel hacker utilisant une attaque du type de MDM (attaque de l’homme du milieu), depuis une connexion internet dans un simple café.
Ainsi, concernant au moins le stockage sécurisé des clés cryptographiques, Google a décidé d’introduire une manière standardisée pour stocker les données confidentielles, dans l’espoir de mettre un peu d’ordre dans le chaos actuel du cryptage mobile.
Encore mieux, l’implantation de KeyStore, considérablement améliorée dans Android 4.3, assure automatiquement que toutes les données KeyStore des applications, sont puissamment cryptées avec sa propre et unique clé, ainsi qu’avec une clé dérivée du mot de passe de l’écran de verrouillage. KeyStore utilise également du matériel dédié spécifiquement au stockage des clés, si disponible bien sûr (et c’est le cas sur Nexus 7, par exemple).
Pour l’instant, tout va bien !
L’implantation de KeyStore
Quand vous regardez le code source principal de KeyStore, keystore.cpp, vous allez rapidement découvrir ce commentaire :

Pour faire simple : “les mémoires tampons ont des tailles toujours supérieures à l’espace maximum requis, ainsi toute vérification du dépassement de la mémoire tampon est omise”.
Vos yeux ont certainement fait 2 tours sur eux-mêmes : si les vérifications du dépassement de la mémoire tampon ont délibérément été omises, et qu’un programmeur a commis une erreur, juste une fois, rendant possible le dépassement de ces mémoires, vous pouvez être certains qu’un éventuel dépassement ne sera pas détecté, encore moins évité.
Le code est écrit en C++, mais il y a beaucoup de séquences de type C dedans, incluant des séquences affectées à la pile, ce qui en langage C se traduit ainsi :

Ne vous inquiétez pas si vous ne connaissez pas bien le langage C, le plus important ici est de comprendre que ce morceau de code prend le keyName (ainsi que l’uid, ou user ID, qui est unique pour l’application demandant la clé), et le convertit en un filename qui le représentera au sein du système KeyStore.
Cette opération est réalisée par quelques manipulations, définies par la fonction encode_key_for_uid(), qui lit des octets depuis la mémoire tampon appelés keyName, et effectue une sauvegarde de ces derniers dans une nouvelle variable, filename, définie par la ligne ci-dessous :

En langage C, cela revient à dire “réservez moi un espace mémoire (octets) dans la pile, qui a une taille de NAME_MAX octets”.
NAME_MAX, est fixé ailleurs dans le code Android à 255 octets, le plus long nom de fichier qui soit autorisé. En effet, il n’y a pas d’intérêt à créer un fichier avec un nom plus long.
La sonnette d’alarme retentit
Vous devez entendre une sonnette d’alarme retentir dans votre tête déjà !
Le commentaire apaisant et rassurant ci-dessus, à propos de la mémoire tampon qui est toujours de taille supérieure à l’espace maximum requis, rend ainsi inutile la vérification de potentiels dépassements.
Ainsi, voici déjà une promesse non tenue par les programmeurs, bien que cela puisse paraître pointilleux, filename est exactement de la taille de la longueur maximale du nom de fichier, et pas supérieure à celle-ci.
Vous aurez aussi remarqué que le programmeur ne mentionne pas la taille de la mémoire tampon de filename concernant la fonction encode_key_for_uid().
En langage C, les séquences telles que filename sont une simple série basique d’octets. Elles n’incluent pas de mention sur la quantité maximale d’octets qu’elles peuvent contenir.
C’est pourquoi les dépassements de mémoires tampons en langage C sont des erreurs assez courantes : en effet, quand vous copiez num octets depuis une séquence src vers une autre séquence dest, votre séquence src ne sait pas si elle contient num octets à lire, et la séquence dest ne sait pas si elle contient num octets de disponibles pour les écrire.
Vous devez donc, de votre côté, garder une trace de la quantité de mémoire qui est allouée à chacune de vos séquences.
Est ce que la taille de filename est suffisante ?
La question inquiétante qui suit est la suivante : « Est ce que filename a une taille suffisante pour recevoir les données provenant de keyName,et qui vont être copiées ? »
Notre première étape est donc de plonger dans la fonction encode_key_for_uid(),et voir ce qu’elle effectue :

Une fois encore, ne vous inquiétez pas si vous ne comprenez pas le langage C : ces lignes de code écrivent les données numériques correspondantes à user ID de l’application appelante (uid), comme une séquence texte de chiffres, suivie par un tiret bas, le tout dans le paramètre out, qui n’est autre que notre filename, avec une taille de mémoire tampon de 255 octets.
Du fait du codage sous Android de l’user ID sur 32 bits, cela ne peut jamais être supérieur à 232-1, ce qui correspond à 4 × 109, ou encore à 10 chiffres.
Ainsi, au maximum 12 octets (10 chiffres, un tiret bas, et l’octet « 0 » ou « NUL », utilisé pour terminer la séquence texte en langage C), seront inscrits dans la mémoire tampon de notre filename, qui fait 255 octets de long.
Notez que le programmeur a essayé de faire les choses correctement ici, en utilisant la fonction snprintf(), qui est une manière rapide de crypter en disant : « merci de réaliser une écrire formatée d’au moins N octets, dans une séquence de mémoire tampon ».
Le programmeur a délibérément fixé la limite à 255 octets maximum pour la séquence à inscrire, même s’il savait qu’il serait largement dans cette limite, et malgré l’avertissement fait au début concernant la vérification de dépassement inutile, et donc omise dans le processus.
[vc_row][vc_column width=”1/1″][vc_message color=”alert-info”]
Ce code est pauvre, malgré l’utilisation de snprintf(). Le programmeur a déclaré la longueur de filename explicitement au niveau de la fonction appelante, où il l’a définie (lui permettant l’allocation des 255 octets de mémoire tampon), et au niveau de la fonction appelée. Ainsi, si vous voulez ultérieurement changer la taille de la mémoire tampon où elle a été définie, vous devrez retrouver tous les endroits où cette mémoire tampon est utilisée, et changer la taille également. Si vous l’oubliez, vous allez créer un bug. Le programmeur aurait plutôt dû déclarer la valeur sizeof filename dans la fonction appelée.
[/vc_message][/vc_column][/vc_row]
Ensuite, nous avons approfondi l’analyse, en entrant dans la fonction encode_key(), qui écrit davantage d’octets dans filename.
Cette fois, la fonction ne prend même pas la peine de vérifier s’il y a assez de place en mémoire :

Cette fonction empile des octets depuis la séquence in, qui est notre keyName, dans la séquence out, notre filename, jusqu’à épuisement des octets à copier.
[vc_row][vc_column width=”1/1″][vc_message color=”alert-info”]
Les caractères standards interprétables sont copiés inchangés (1), mais si les caractères entrés ne sont pas interprétables en tant que nom de fichier, l’algorithme (3) procède à un codage sur 2 caractères, qui sont plus sûrs pour une utilisation dans un nom de fichier. Ce détail est déjà inquiétant, compte tenu que le code considère la mémoire tampon comme suffisante en terme de taille. Notre filename de 255 octets de mémoire tampon, peut, en théorie, être dépassée par un keyName judicieusement choisi. En effet, avec seulement 128 octets de long, il suffit que chaque octet, au départ, soit choisi délibérément pour déclencher un codage sur 2 octets en sortie. Pour finir, un caractère « NUL » (4) est rajouté pour terminer la séquence, un octet additionnel pour lequel le programmeur n’a pas réservé de place aux différents endroits du code où cela aurait été nécessaire (voir ci-dessous).
[/vc_message][/vc_column][/vc_row]
Et si keyName est trop long ?
Comme vous pouvez l’imaginer, à ce stade les experts d’IBM se sont demandés : “que se passe t-il si keyName est trop long et ne rentre plus ?”
Le programmeur nous a promis que toutes les mémoires tampons seraient suffisantes en taille, cependant une recherche approfondie au niveau du code nous montre que cela n’est pas vrai.
Le tampon pour filename est figé à 255 caractères, alors que les paramètres pour keyName passent par une application, et peut au final avoir n’importe quelle taille (et contenir n’importe quelle séquence d’octets), en fonction de ce que l’application appelante désire.
Ainsi nous avons un dépassement de mémoire tampon au niveau de la pile qui peut, précisément, être contrôlé par une application malveillante.
Nous n’avons aucune garantie que cette vulnérabilité puisse être exploitée davantage qu’au travers d’une attaque par déni de service (qui aurait comme conséquences le crash du système KeyStore). Cependant, cela reste une vulnérabilité à part entière !
Google a résolu ce problème dans Android 4.4, mais pas vraiment en profondeur : en effet, le code fait toujours l’hypothèse que « les mémoires tampons sont toujours de tailles supérieures au maximum requis, ainsi les vérifications de dépassements sont omises ».
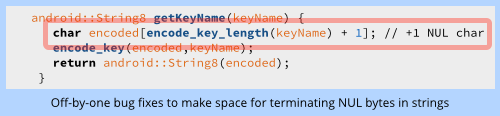
Curieusement, Google a aussi détecté de nombreux endroits où le programmeur avait oublié ce fameux octet « NUL » qui termine les séquences en langage C, et alloue de manière incorrecte les mémoires tampons qui sont, du coup, un octet trop petit au niveau de leur sortie, mais sans causer apparemment d’erreurs visibles lors des tests.
Ces problèmes ont été réglés par une utilisation assez libre du “+1”, comme suit :
Conseils pour les programmeurs en langage C
Essayez les astuces suivantes :
Pour résumer, écrivez votre code en partant de l’hypothèse qu’il sera vérifié par un autre programmeur, qui est méticuleux, sévère et rigoureux, et qu’il sera testé par un hacker, malveillant, très motivé et tenace !
D’une manière générale, préparez vous au meilleur, mais n’oubliez jamais de prévoir le pire !
Billet inspiré de : “Anatomy of a buffer overflow – Google’s “KeyStore” security module for Android” par Paul Ducklin de Naked Security.
Partagez “Dépassement de la mémoire tampon : l’histoire de KeyStore” avec http://bit.ly/1jfMUeR