At the time that the brutalized bodies of a Canadian couple were discovered near Washington’s Mount Rainier nearly 32 years ago, police believed that the killer left his plastic gloves in plain view near their van so as to taunt investigators.
Detective Robert Gebo of the Seattle Police Department:
He leaves those behind as a sign to the police that you needn’t look for fingerprints because I wore these gloves. And he has confidence that there’s nothing that’s going to connect him with these crimes.
That killer’s self-confidence was misplaced. Decades later, he was tracked down through links to the DNA of two cousins. On Friday morning, a Snohomish County jury found William Earl Talbott II guilty on two counts of aggravated murder in the first degree for the deaths of 21-year-old Jay Cook and his 17-year-old girlfriend, Tanya Van Cuylenborg.
First DNA database conviction
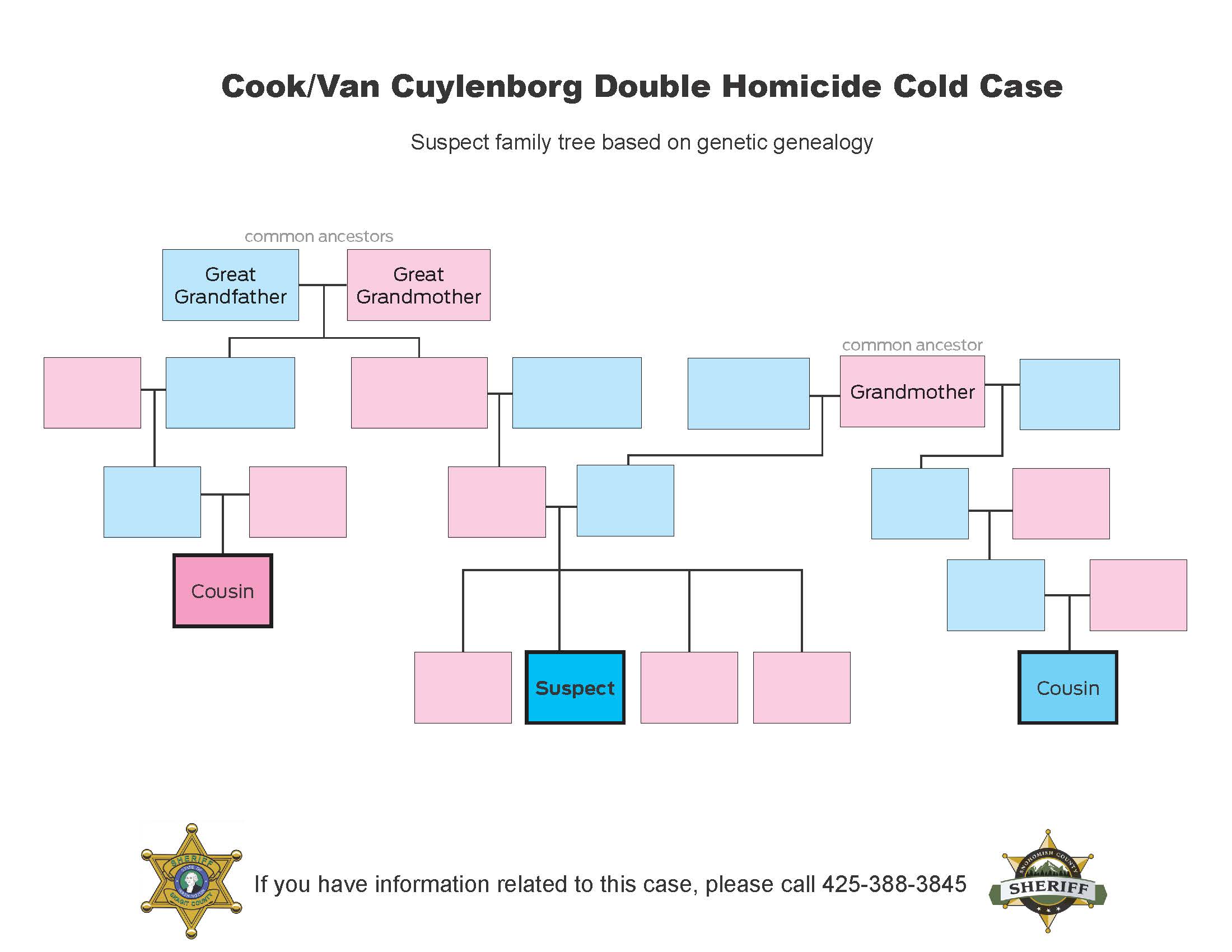
This is believed to be the first murder conviction of a suspect who was identified through genealogy databases. CeCe Moore, a genetic genealogist who works for forensic company Parabon NanoLab, had used a public DNA site, GEDmatch, to help build this family tree for what would turn out to be the now-convicted murderer, based on DNA evidence from the crime scene. That tree shows the links between Talbott and two of his cousins who had uploaded their genetic profiles to GEDmatch.
{kind=link}
This isn’t the first time DNA databases have led to the identification of a suspect – or of victims. GEDmatch is the same database that was used to identify Joseph James DeAngelo, the alleged Golden State Killer, in 2018.
In fact, there have been dozens of arrests made in cold-case crimes nationwide through the forensic technique known as genetic genealogy.
According to the Snowhomish County news outlet Herald Net, there was little to tie Talbott – a 56-year-old short-haul truck driver who lived in the area but who had no previous felony arrests – to the killings, outside of semen and a partial palm print found at the two places where the bodies of the young couple had been dumped.
Moore had used GEDmatch and the semen sample to trace the family lines to Talbott’s mother and father. Talbott had sisters, but he was the only son. Within days of Moore’s lab receiving the data report on a Friday in April 2018, she identified who the sample belonged to.
Talbott was put under surveillance by plainclothes officers who followed him on his driving routes for days. When a paper cup fell out of his truck on 8 May 2018, they grabbed it. A state crime lab determined that his DNA matched that of the semen, and he was arrested and charged with two counts of aggravated first-degree murder.
Contesting the semen, not the DNA
While defense attorney Rachel Forde questioned the presumption that the presence of semen meant there’d been a rape, she didn’t question the use of DNA genetic genealogy during the trial. Nor did the defense bring any privacy challenges against the evidence. From the Herald Net:
At least in this trial, the genealogy work was treated like any tip that police might follow.
Forde did, however, tell CNET that the jury made a mistake by focusing on the DNA evidence, and that Talbott plans to appeal the conviction. From her emailed statement:
Every American should now be concerned that the mere presence of their DNA at a crime scene could now lead to a conviction for a crime they didn’t commit.
She has a point. We should indeed be aware that if our DNA shows up at a crime scene, it could be one piece of evidence that leads to a conviction. However, as pointed out by Snohomish County Prosecutor Adam Cornell, genealogy research alone didn’t crack the case – rather, it was one piece of a thorough investigation in which the sheriff’s office followed up on all leads.
Should innocent people worry?
The use of genealogy databases in police investigations has led to privacy questions. Namely, we don’t have to spit into a tube and submit it to a genealogy database to have it made public. Because we share much of our DNA with relatives, all it takes is one of them to submit their DNA, thus making much of our own genetic information available to the police without our knowledge or consent.
The more people who submit DNA samples to these databases, the more likely it is that any of us can be identified. According to Columbia University research published in October 2018, the US is on track to have so much DNA data on these databases that 60% of searches for individuals of European descent will result in a third cousin or closer match, which can allow their identification using demographic identifiers.
The researchers suggested that we need to re-evaluate how we use this powerful data. Law enforcement, policy makers and even the general public may well be in favor of using these “enhanced forensic capabilities” for solving crimes, but we need to keep in mind that these databases and services are open to everyone, and not everyone will use them with good intentions.
For example, research subjects can be re-identified from their genetic data. Yet rules that, starting this year, will regulate federally funded human subject research fail to define genome-wide genetic datasets as “identifiable” information – despite researchers saying at the time that their work shows that such datasets are indeed capable of identifying individuals.