
Here at Naked Security, we’re fond of randomness.
By that, we mean the sort of real randomness that you get from radioactive decay, or background cosmic microwave radiation.
This fondness might seem surprising: randomness and digital computers are strange bedfellows, because computers, and the programs that run on them, are inherently deterministic.
This means that they’ll produce predictable, repeatable results if you feed them the same input over and over.
Most of the time, that’s highly desirable: if your computer adds up a giant list of numbers in a spreadsheet, for example, it will get the same answer every time.
Of course, that doesn’t guarantee the answer is correct – if it was wrong today, it will be wrong tomorrow – but it is at least consistent, and can therefore repeatably and reliably be measured and tested.
Repeatability can be harmful
Sometimes, however, repeatability is bad for security, especially when encryption is involved.
A strong encryption algorithm should disguise any patterns in its input, meaning that its output should be indistinguishable from a random sequence.
But that’s not enough: each random output sequence from each run of the encryptor needs to be unique, and unpredictably so, even if you encrypt the same file twice with the same password.
In other words, you need some good-quality randomness to feed into the encryption algorithm at the start.
An excellent example of why this matters comes from Adobe’s infamous password breach in 2013.
The company encrypted every user’s password with the same key, with no added randomness mixed in.
That meant the encrypted passwords could be sorted into bunches, even though they were supposed to be secret.
From the password hints in the database, which Adobe didn’t encrypt at all, you could therefore use the sloppiest user’s hint to figure the password for a whole bunch of users at a time. (Many users had repeated their passwords in the hint field, directly or thinly disguised.)
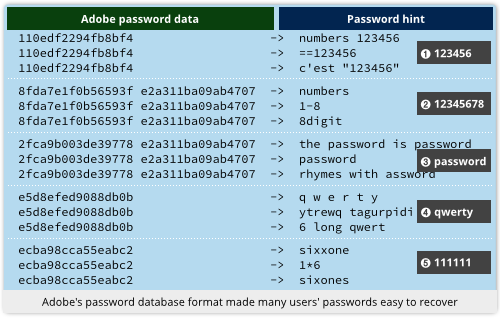
Adobe ought to have chosen a different random modifier, known as a salt, to mix in with each user’s password so that every encryption would produce unique output, even for repeated passwords.
In other words, strong encryption needs a good source of randomness as input if it is to produce usefully-random output.
Tor and randomness
Tor, of course, relies on strong encryption for the anonymity and privacy it provides.
Tor picks a random path for your network traffic so that it passes through an unpredictable selection of nodes in its “onion network”.
When your computer pushes your traffic into Tor, it wraps the data in multiple layers of encryption, in such a way that the next node in the pre-selected path, and only that node, can strip off the next layer of encryption, and only that layer.
That way, each node knows only its immediate neighbours (where your packet came from, and where it’s going next), and thus no one can figure out exactly how it got through the network.
As you can imagine, that means Tor needs plenty of high-quality random input.
Even more importantly, it needs a way to generate randomness for the whole network that can’t be dominated or controlled by individual nodes in the network.
Otherwise, one malevolent or incompetent node could poison the system by introducing “bad randomness.”
Low quality random numbers might make it possible for outside observers to crack the encryption, stripping off some or all of Tor’s anonymity; even worse, carefully chosen “random-looking” but rigged numbers might allow a malicious node to snoop on Tor from the inside.
So, the Tor team came up with a distributed protocol for generating random numbers, so that multiple nodes chime in with what they claim are randomly generated values, and then combine them all into a Shared Random Value (SRV) that is agreed on for the next 24 hours.
COMMIT and REVEAL
Very greatly simplified, the system works like this.
The nodes involved in the randomness protocol spend the first 12 hours of each day inserting what Tor calls a COMMIT value into their messages.
The COMMIT values are cryptographic hashes of a random number each node generated earlier, known as its REVEAL value.
After everyone has nailed their COMMIT values to the virtual mast over a 12-hour period, the nodes start publishing their REVEAL values.
The COMMIT value can be calculated (and thus confirmed) from the REVEAL value, but not the other way around, so that no one can switch out their REVEAL values later on.
That means a malicious node can’t wait until other nodes have REVEALed and sneakily modify its value before REVEALing its own choice.
The REVEAL values are themselves a cryptographic hash of a randomly-generated string of bytes. The original random numbers are hashed as a precaution so that no node ever reveals the actual output of its random generator.
Once all the verifiable REVEAL numbers are nailed to the mast alongside the COMMIT values, the entire set of REVEALs are hashed together to form the SRV.
The theory here is that as long as one or more of the REVEALs really is decently random, then stirring in other non-random data won’t reduce the randomness of the combined SRV, unless some of the non-random data was maliciously chosen with foreknowledge of the other data in the mix.
But none of the REVEALs can be based on anyone else’s choice, because of the COMMIT values that everyone was required to publish first.
In short: even if some of the players have loaded dice, they can’t figure out how to load them to counteract the honesty of your dice.
That sounds like a lot of work for something that you could do for yourself at home by tossing a coin repeatedly…
…but as we have joked (quite seriously!) before, random numbers are far too important to be left to chance.
cakmn
Paul, your last sentence should say: ” random numbers are far TOO important to be left to chance” Otherwise, thanks for the random story.
Paul Ducklin
Aaargh! Fixed, thanks.
Anon
When NSA owns most of the nodes no privacy exists.
Guy
Great article.
I’d like to see an RFC on a distributed randomness protocol for the public internet as a whole. Publish RND records in DNS as a random number server, and allow applications to pool for random numbers in a similar way that they poll for the time when setting the system clock.
That way, a programmer can select one or more random number servers, take some blocks of random numbers from them and then dice and slice the bits, XOR, ROT13 the bytes, flip the endian or do whatever they want, but have their random seed generated by a public server with real non-deterministic input.
As it would be an open protocol, the paranoid among us could run the service locally, with a microphone plugged in, or temperature sensor, or lump of uranium, or whatever, on a private random number server, providing genuine non-deterministic values for a local network.
Apologies if this already exists. If it does, Paul, please post the link to the RFC.
Thanks.
Paul Ducklin
A lump of uranium is interesting, but then you’d need a geiger counter. You could look around to see what you can do with a smoke detector: it already has a source of alpha particles (that meets safety laws) and a way to measure the radiation levels; a bit of hacking and an Arduino… though you oughtn’t to take a smoke detector apart in case the radioactive pellet gets loose from its capsule.
You’ll also find examples on the internet that give various affordable hobby circuits for randomess, for example using a low-frequency, unstable oscillator to sample the state of a high-frequency stable oscillator.
David Pottage
In Linux you can install the randomsound daemon. Then connect a microphone to your server and use the white noise from all the fans in your server room as a source of entropy. I used that on a server of mine a while back because I found it was running low on entropy, and affecting SSL performance as a result. Once I connected a USB sound card, microphone and setup the daemon, the problem was fixed.
baford
Nice summary of commit-and-reveal contributory randomness, but you should really mention that this protocol is not fully secure, in that it is still vulnerable to bias attacks.
The attacker commits to something just like everyone else, then waits until everyone else has revealed, and finally computes the outcome before he reveals his own commit. If he doesn’t like the outcome, he just goes offline and withholds his reveal. The rest of the network either has to start over, or compute a *different* random value constructed without the attacker’s contribution. That different result is biased toward the attacker, giving the attacker a “second chance” at getting an outcome he likes (because he wouldn’t have done this if he liked the outcome in the first place).
It gets worse. If the attacker controls k colluding participants, and the protocol has any way to continue when nodes refuse to reveal their commits, then the attacker gets to pick the most favorable of 2^k outcomes. The k attack nodes just wait to the end to reveal, then decide which of the k nodes will reveal their commits and which won’t. There are 2^k such choices, and the attacker can compute the outcome for each such choice before deciding which one he likes best.
I’m pretty sure the Tor devs are aware of this bias weakness, but fixing it is hard. My DEDIS lab at EPFL is working on a protocol that does that, but it’s more complex. The real question is what the randomness is being used for: does it just need to be (mostly) unpredictable, or does it need to be unbiased?
Paul Ducklin
However, if your REVEAL is never folded into the final hash, you can’t mount any sort of “active choice” attack, right? Because unless you COMMIT in time and then REVEAL a valid value, you don’t get any of your data included in the mix. (There was a brouhaha over Linux’s random generator a while back, in which the code was modified so that it folded a value provided by the CPU into the random accumlator *right at the end*, after the CPU had just witnessed all the other machinations and could, in theory, have selected its “random” value to bias the outcome. Experts wondered why the coders had left this new step to the very last, when committing the CPU’s data earlier on would, at the very least, have prevented a long threat of conspiracy theory complaints.)
baford
If you get to be last to REVEAL then you can compute what the final outcome will be with or without including what you would REVEAL, decide to REVEAL or not based on that computation, and get your (biased) preference of those two possible outcomes. So leaving out your REVEAL does NOT eliminate bias attacks.
And worse, as I said, if you control several colluding participants the bias attack opportunity gets worse exponentially in the number of colluders. If I get to control 8 cronies, then I have them wait to REVEAL last, then I compute the 256 different possible outcomes depending on whether each one REVEALs or not, pick the best outcome, and direct my cronies to REVEAL or not in order to make that chosen outcome the reality.
Even if the game is producing many “bits” of randomness, the attacker gets to choose which bit(s) to bias. For example, suppose the random output is going to be run through another hash function or two, then the 115th output bit will determine whether you or I win some pot o’ gold. (Maybe many other bits will determine the outcomes of other bets.). If I, the attacker, only care about the outcome of that 115th output bit and don’t care about the other outcome bits, and I have 8 crony participants, then I can ensure that I win the pot o’ gold with nearly 100% certainty (specifically with 255/256 probability). Because I just wait for everyone else to REVEAL, compute the outputs for the 256 combinations of whether my cronies REVEAL or not, and pick any one in which the 115th output bit comes out as “I win”. And about half of them will.
baford
Stated another way, even if refusing to REVEAL means the attacker’s data doesn’t get into the mix, the *choice* of whether or not to REVEAL still gives the attacker the opportunity to “re-roll” the dice to get an outcome he likes better. And it should be obvious why letting the attacker choose between the best of two dice rolls is biased – and why letting the attacker choose the best of 2^k dice rolls (for k cronies) is biased a *lot*.
limbenjamin
“Adobe ought to have chosen a different random modifier, known as a salt, to mix in with each user’s password so that every encryption would produce unique output, even for repeated passwords.”
I think you meant hashed and not encrypted
Paul Ducklin
Actually, Adobe encrypted its passwords using a secret key (which was, in fact, never revealed).
The whole comedy of errors is explained here:
https://nakedsecurity.sophos.com/2013/11/20/serious-security-how-to-store-your-users-passwords-safely/
wee willy winkle (@mustafalotweets)
Understood. However, i feel all is lost as governments control the TOR network now so entry and exit points are constantly either monitored or under their command. The best way to stay anon online is this. Multiple sim cards purchased via cash or cash card loaded with cash. This way you can use each sim up in any location and simply throw away. You get much faster internet and much improved security.