
Regular readers of Naked Security will know that one of the truisms we like to trot out about cybersecurity is the wryly self-contradictory reminder that you should “Never say never.”
Indeed, when it comes to programming, the only time that you should ever say, “This will never happen” is if you can show formally, for example with an accepted mathematical axiom or a proof, that it will quite literally never happen because it can’t.
For example, when a C compiler looks at this code…
unsigned int i = 0;
while (i >= 0) {
i = the_next_value_of(i);
}
…and warns you that your while loop will never terminate, it really can and should use the word never.
A variable declared unsigned can, by definition, never be negative and therefore the “conditional” expression i >= 0 isn’t conditional at all: it can be replaced by the constant 1, or TRUE, and can literally never be FALSE.
But there are many other programming cliches where coders ignore errors that might happen in theory, often for one or more of these reasons:
- This bug is so incredibly unlikely, and catering for it would so complex, that the code is more likely to be bug-free if you simply assume that the error will never happen. (What could possibly go wrong?)
- This bug is sufficiently unlikely, and simulating it correctly in testing would be sufficiently hard, that ignoring the error is a justifiable “technical debt” that is worth borrowing against now to meet a delivery deadline. (Let’s come back and fix it later if anyone notices.)
- This bug is only ever likely to happen if something else even more catastrophic has already happened, so there is no point in worrying about it now. (No point in rearranging the deckchairs on the Titanic.)
Examples include: assuming that occasional and short-lived allocations of tiny amounts of some abundant system resource will always succeed; assuming that two processes will never accidentally choose the same random filename; and assuming that 640KBytes of memory should be enough for anyone.
Another example, perhaps the one that best supports the motto simply never to say never, is assuming that two digits is enough to store the year, so that you can just write 83 instead of 1983, or 21 instead of 2021, and nothing bad will ever happen.
How much do shares cost?
So, with memories of Y2K firmly in mind (or stories of it, if you’re young enough ), let’s play a game.
What’s the largest value in US dollars that a single share, in any publicly traded company anywhere in the world, could ever reach, and then some?
In other words, if you had to pick an amount that would safely encompass the value of any share you needed to report upon, now and in the lifetime of your program, how high would you go, and then how much safety margin would you build in for the future?
After all, many hugely wealthy and successful companies have stock prices well below $10,000, because they want to avoid having share prices that are out of reach of all but the biggest investors.
They therefore deliberately reduce the price per share without changing the value of the company by using “stock splits” to convert, say, 1 share costing $1000 into 5 shares of $200 each.
The idea is much the same as asking a bank teller to give you five $20s instead of one $100 – the total amount is the same but the lower value of the bills makes them easier to use in stores.
Apple, for example, has split five times since 1987 (2-for-1 in 1987, 2000 and 2005; 7-for-1 in 2014; and 4-for-1 in 2020), so that one original Apple share has now turned into 2x2x2x7x4 = 224 contemporary shares, each worth 1/224th part of the original.
But you may be surprised just how high some individual share prices are.
UK clothing chain Next is currently worth more than $10,000 a share on the London Stock Exchange, for example, and Swiss chocolatiers Lindt are currently trading at over $100,000 a share on the SIX Swiss Exchange. (FYI, we checked at 2021-05-10T16:45Z.)
So if you wanted to record share prices with an accuracy of 1/100 of a US cent (one ten-thousandth of a dollar), you’d need to be able to represent numbers up to and beyond 1,000,000,000 (one billion) , because there are one billion ten-thousandths of a dollar in $100,000.
It’s easier to figure out if you work with exponents and notice that 100,000 = 105 and 10,000 = 104, i.e. 1 followed by 5 zeros and 4 zeros respectively. When you multiply them together you get 105x104 = 105+4 = 109, and a billion has 9 zeros.
DWORDs will do
You could get away with using a 32-bit unsigned binary integer, often referred to as a DWORD, short for double word, where a WORD is 16 bits, or two bytes.
DWORDS can store 232 different values starting at zero and ending at 232−1 (the “minus one” comes from the fact that you need to start counting at zero, which uses up one of the possible values).
And 232−1 = 4,294,967,295, which assembler programmers will tell you off the top of their heads, although they cheat by using base 16 (hexadecimal), where the value just happens to come out as the easily-remembered 0xFFFFFFFF (the 0x prefix is C shorthand that denotes hexadecimal).
So if you use a 32-bit unsigned integer that takes up four bytes of memory, you can exactly represent any share price from $0 to $429,496.7295, if you count in 1/100ths of a cent.
Of course, most computers these days happily and efficiently handle 64-bit integers in calculations, but they consume eight bytes each, and given that Lindt and Next are amongst the priciest shares you can buy right now, more than half the bits in every share price you stored would in theory be wasted if you went for 64 bits instead of 32.
So, coders at Nasdaq apparently settled (probably years ago, when 232 was still considered a huge number, and 4GByte of RAM was still a truly enormous amount) on 32-bit numbers to store their share prices in 1/100ths of a cent.
What could go wrong?
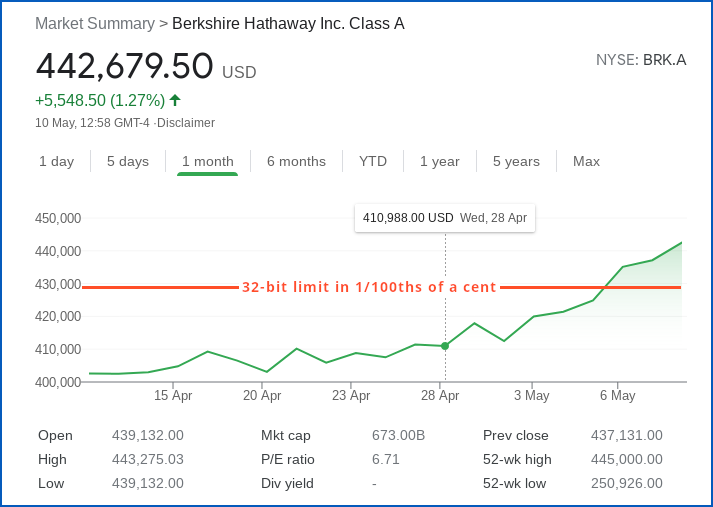
The problem, however, is that the most expensive individual share you can buy right now is not Next or Lindt, but BRK-A, the ticker abbreviation for Warren Buffett’s famous Berskshire Hathway Inc.
And those shares, when last we looked, cost an eye-watering $442,512 each, which comes out at 4,425,120,000 ten-thousandths of a dollar, or 0x107C1F900 in hexadecimal, up from just over $400,000 a month ago.
Let’s do that in binary, so you can see that this value needs a 33-bit number, and won’t fit into 32 bits any more:
---| |--------------------32 bits-----------------|
1 0 7 C 1 F 9 0 0
0001 0000 0111 1100 0001 1111 1001 0000 0000
If we failed to check for that integer overflow into the 33rd bit and just used the bottom 32 bits of the result without realising that our calculation was no longer valid, the BRK-A price would have turned out as 0x07C1F900 instead:
---| |--------------------32 bits-----------------|
? 0 7 C 1 F 9 0 0
---- 0000 0111 1100 0001 1111 1001 0000 0000
That comes out at 130,152,704 ten-thousandths of a dollar (just over $13,000), and you’d need to go back to 1993 to be able to get a BRK-A share at that price.
What to do?
The New York Stock Exchange (NYSE), on which BRK-A shares are actually listed, doesn’t seem to store its prices the same way as Nasdaq, and therefore wasn’t affected by the BRK-A price climbing to $429,497 and beyond.
Nevertheless, Nasdaq provides stock price reports for lots of exchanges, and if it had suddenly started pricing BRK-A at a tiny fraction of its real value, it would have created at least some confusion and trouble, if only for Nasdaq’s PR team.
The good news, however, is that Nasdaq simply stopped reporting the BRK-A price until it had introduced a fix (or at least a workaround) for this issue, thus turning what would have been a bug causing misinformation into a problem causing an outage.
Make sure you do the same in any code you write.
When it comes to cybersecurity, a program that knows it has gone wrong and deliberately stops saying anything at all can be considered much better behaved, and therefore more correct, than software that cheerfully and confidently reports incorrect data in blissful ignorance and ends up misleading you.
Your code should carefully check for possible problems not only when errors are likely but also, perhaps especially, when those errors are unlikely.
Your code review process and testing need to take this into account, too.
Even when correct code is perfectly easy to write in theory, incorrect code often triumphs because it is not only easier but also quicker to write in real life.
Don’t do that!
Never, in a word, say never.
Steve Elliott
I began coding professionally in 1976 and can attest that the code I wrote then was Y2K compliant.
Paul Ducklin
How about Y10K :-)
R.Dale Barrow
Y10K may (or may not) be a problem.
The next thing that’s going to bite (I know, I know, I know …) will be leap year for 2100. The simple MOD(YEAR,4)==0 works most of the time. One of the leap year rules is that years divisible by 100 are NOT a leap year (2100) unless that century year is divisible by 400 (2000). Y2K was merely a warm up.
The “It’ll never happen!” code I wrote in the 70s and 80s probably won’t outlive me, but you never know. Actually at the time I wrote it, I knew it was wrong but I knew I wouldn’t be here to have to fix it. ☺