



I criminali continuano a sfruttare le caratteristiche del formato PDF di Adobe per effettuare attacchi malware e di phishing, senza alcun segno di rallentamento. Lo scorso anno al Black Hat USA ho tenuto una presentazione sull’individuazione dei malware basati su PDF tramite il machine learning. In quell’occasione avevo scoperto che il miglior motore antivirus era in grado di rilevare meno dell’85% dei campioni di PDF dannosi mai visti prima, ma combinando un modello di machine learning con il motore antivirus eravamo in grado di migliorare questo dato fino a rilevare con accuratezza oltre il 95% dei nuovi PDF dannosi.
Tuttavia, visto il volume di documenti dannosi in circolazione, quel 5% può essere piuttosto significativo. Per questo motivo, dall’anno scorso abbiamo continuato a lavorare sull’utilizzo del machine learning per affrontare il problema dei PDF e dei documenti Microsoft Office dannosi (mal-PDF e maldoc). Alcune settimane fa, al Black Hat Asia 2019 tenutosi a Singapore, ho presentato la nostra ultima ricerca sul machine learning per il rilevamento dei virus utilizzando le regole euristiche antivirus, sulle quali si basa la maggior parte delle soluzioni antivirus tradizionali: Weapons of Office Destruction: Prevention with Machine Learning.
Nello specifico, l’approccio sfrutta le migliaia di regole euristiche già usate nelle soluzioni antivirus tradizionali. Crediamo che le forti regole euristiche basate sulla conoscenza del settore dei motori antivirus esistenti siano più accurate ai fini dell’apprendimento rispetto alle funzioni o caratteristiche che l’algoritmo del machine learning deriva automaticamente, non avendo conoscenza di questo settore. In sostanza, le regole euristiche formano e perfezionano l’algoritmo del machine learning in modo che svolga meglio il proprio compito.
Test della prevenzione dei maldoc
Abbiamo valutato l’efficacia dell’approccio da noi proposto nei confronti di uno dei vettori per la trasmissione dei malware più popolari: i documenti di Microsoft Office “armati”. L’ampia popolarità dei documenti Office li ha portati a diventare uno dei principali meccanismi di trasmissione di malware, tramite allegati alle email o download dal Web.
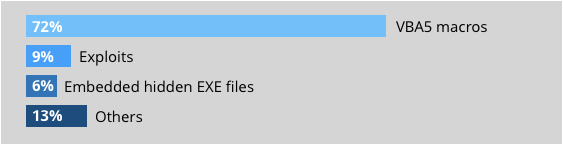
Secondo un report Sophos precedente, oltre l’80% dei malware basati su documenti è stato trasmesso tramite file Word o Excel. Anche se questi attacchi non sono nuovi nel Web, l’aumento del volume e della complessità degli attacchi pone una sfida importante ai prodotti antivirus tradizionali basati su firma.
Nella dimostrazione, abbiamo usato un elenco completo di oltre 3000 regole euristiche per formare il modello di machine learning. Abbiamo raccolto una serie campione di circa 100.000 documenti Office (un mix di file benigni e dannosi) per testare e perfezionare ulteriormente il modello.
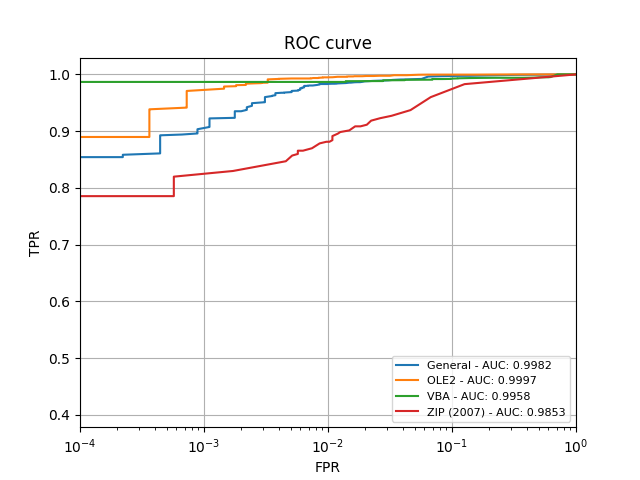
I nostri risultati hanno mostrato prestazioni e tassi di rilevamento incoraggianti. L’approccio da noi proposto si avvicina molto al tasso di accuratezza che cercavamo di raggiungere, che siamo stati in grado di misurare e mostrare nella curva ROC (Receiver Operating Characteristic) rappresentata nel grafico qui sopra.
Il grafico ROC confronta veri e falsi positivi e mostra come il modello è stato in grado di arrivare estremamente vicino a un tasso di “veri positivi” perfetto, in media di oltre il 99,5% per i documenti e i file di testo, e oltre il 98,5% per gli archivi .zip compressi.
L’approccio proposto può ottenere curve ROC con un’AUC maggiore di 0,99 per il modello di machine learning proposto.
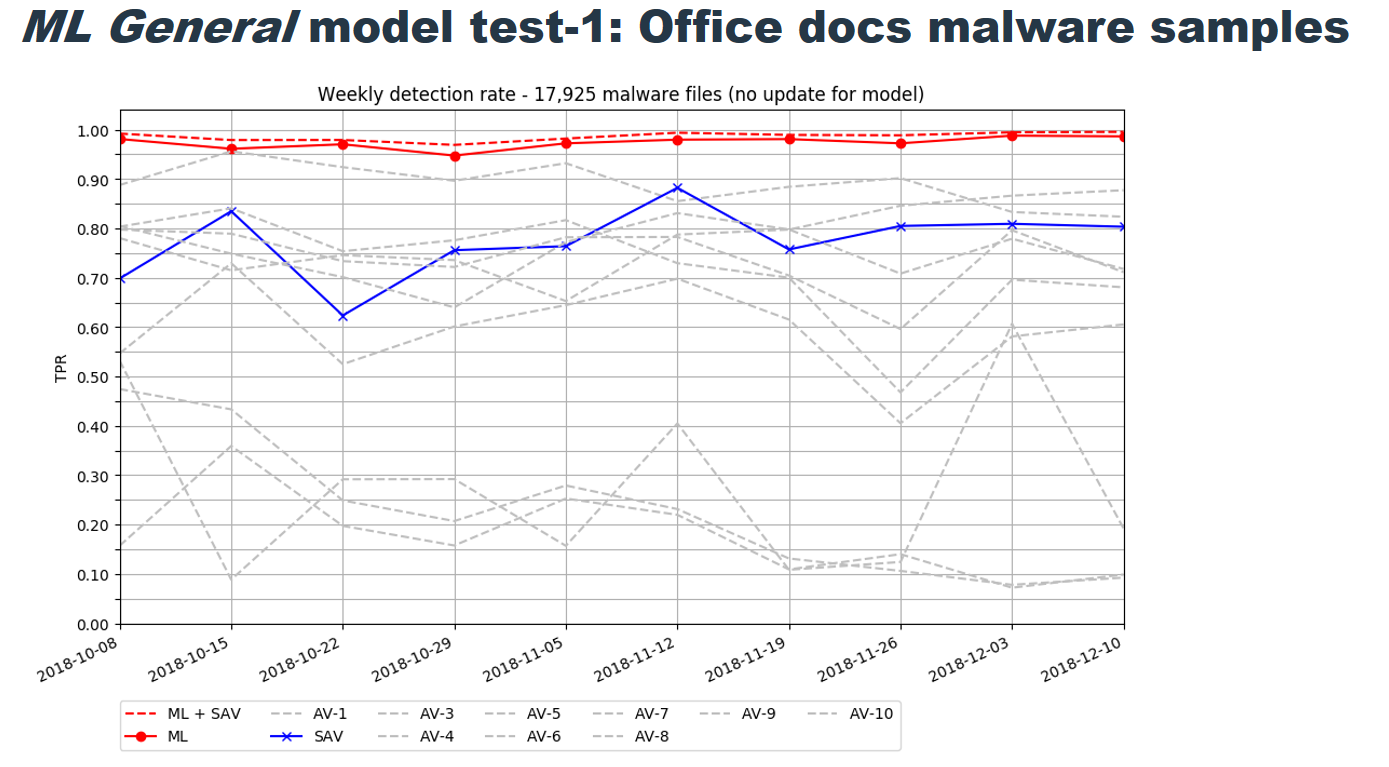
Questi risultati, che hanno usato campioni reali recenti di malware, mostrano prestazioni promettenti. L’applicazione del machine learning per raggiungere un verdetto su un documento sconosciuto ha ottenuto prestazioni migliori rispetto a quelle di dieci celebri programmi antivirus commerciali, con un tasso di veri positivi (TPR) molto più alto.
Si tratta di una grande vittoria per il machine learning nella sua lotta contro i malware.
di Jason Zhang, SophosLabs Senior Threat Researcher