
** 本記事は、Benchmarking the Security Capabilities of Large Language Models の翻訳です。最新の情報は英語記事をご覧ください。**
大規模言語モデル (LLM) による機械学習技術は急速に普及しており、複数の競合するオープンソースアーキテクチャや独自アーキテクチャが利用可能になっています。LLM は、ChatGPT のようなプラットフォームが主に使用されるテキスト生成タスクに加え、コード記述の補助からコンテンツの分類に至るまで、多くのテキスト処理アプリケーションで有用なことが実証されています。
SophosAI は、サイバーセキュリティ関連のタスクに LLM を利用する方法を数多く研究してきました。しかし、現在はさまざまな LLM が利用できるため、研究者はどのモデルが特定の機械学習課題に最適であるかを判断しかねています。 モデル選択の優れた方法の 1 つは、ベンチマークタスク (モデルの能力を簡単かつ迅速に評価するために使用する典型的な課題) を作成することです。
現在、LLM はいくつかのベンチマークを利用して評価されていますが、これらのテストは基本的な自然言語処理 (NLP) タスクにおけるモデルの汎用的能力を測定するものに過ぎません。たとえば、Huggingface Open LLM (大規模言語モデル) リーダーボードは、Huggingface 上でアクセス可能なすべてのオープンソース LLM モデルを評価するために、7 つの異なるベンチマークを利用しています。
しかし、これらのベンチマークタスクで測定される性能は、サイバーセキュリティのコンテキストでモデルがどの程度機能するかを正確に反映していない可能性があります。これらのタスクは一般化されているため、多くの場合、この学習データから得られた結果は各モデルのセキュリティ分野における専門知識の差を示すものではありません。
この問題に対処するため、ソフォスは、LLM ベースの防御的サイバーセキュリティアプリケーションの基本的な前提条件であると考えられるタスクに基づいて、以下 3 件のベンチマークセットの作成に着手しました。
- テレメトリに関する自然言語による質問を SQL 文に変換することで、インシデント調査アシスタントとして機能する
- セキュリティオペレーションセンター (SOC) のデータからインシデントサマリーを作成する
- インシデントの重大性を評価する
これらのベンチマークには 2 つの目的があります。微調整 (ファインチューニング) の余地がある基盤モデルの特定と、それらの基盤モデルの即戦力性の評価 (未チューニング状態での性能評価) です。ソフォスは、Meta の LlaMa2 と CodeLlaMa の異なるサイズのモデル (各 3 件) を含む 14 件のモデルに対してベンチマークテストを行いました。モデルのサイズ、人気度、コンテキストサイズ、新しさなどの基準に基づいて、以下のモデルを分析対象に選びました。
| モデル名 | サイズ | プロバイダー | <strongコンテキストウィンドウ (最大) |
| GPT-4 | 1.76T? | OpenA! | 8k または 32k |
| GPT-3.5-Turbo | ? | 4k または 16k | |
| Jurassic2-Ultra | ? | AI21 Labs | 8k |
| Jurassic2-Mid | ? | 8k | |
| Claude-Instant | ? | Anthropic | 100k |
| Claude-v2 | ? | 100k | |
| Amazon-Titan-Large | 45B | Amazon | 4k |
| MPT-30B-Instruct | 30B | Mosaic ML | 8k |
| LlaMa2 (Chat-HF) | 7B、13B、70B | Meta | 4k |
| CodeLlaMa | 7B、13B、34B | 4k |
最初の 2 件のタスクでは、OpenAI の GPT-4 が明確に最高のパフォーマンスを示しました。しかし、最後のベンチマークであるインシデントの重大度分類テストでは、どのモデルも無作為に分類した場合と比して十分な精度を示しませんでした。
タスク 1: インシデント調査アシスタント
最初のベンチマークタスクでは、セキュリティインシデントを調査する SOC アナリストのアシスタントとして、自然言語クエリに基づいて関連情報を検索する LLM のパフォーマンスを評価することを主な目的としました。以前にも検証したタスクです。LLM がスキーマのコンテキスト情報に従って自然言語クエリを SQL 文に変換する能力を評価することで、このタスクへの適性を判断することができます。
ソフォスは、このタスクを数段階に分かれたプロンプト課題として設計しました。最初に、あるリクエストを SQL に変換する必要があるという指示をモデルに与えます。次に、この問題用に作成されたすべてのデータテーブルのスキーマ情報を提供します。最後に、3 組のリクエスト例と対応する SQL 文を提示し、モデルが SQL に変換すべき 4 番目のリクエストとともに、モデルの例とします。
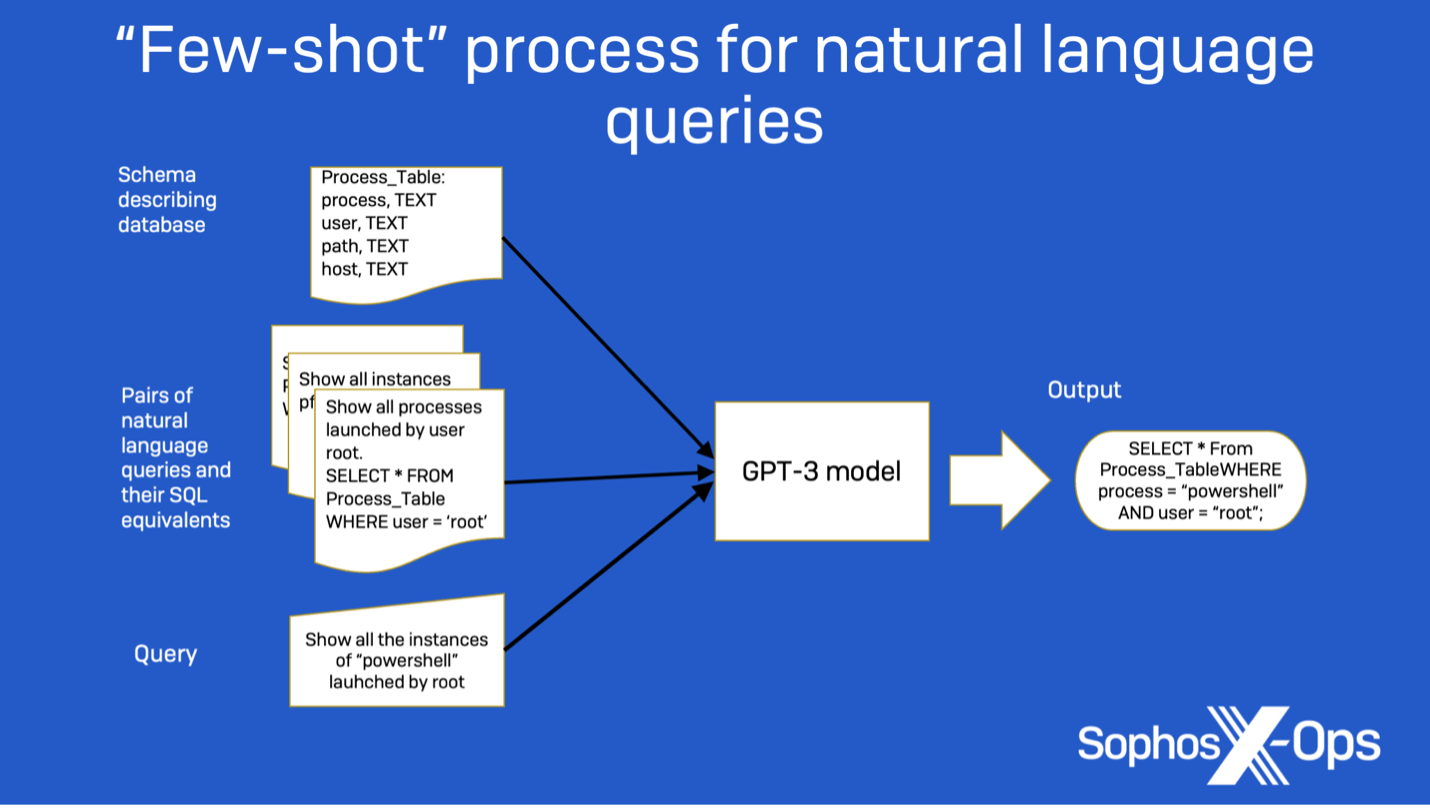
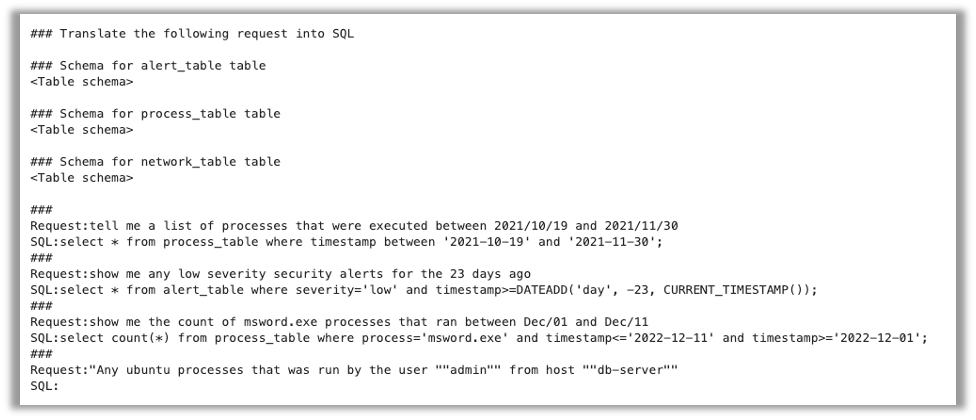
このタスクのプロンプトの例は以下の通りです。
まず、各モデルが生成したクエリの精度を測定するため、出力が期待される SQL 文と完全に一致するかどうかをチェックしました。SQL 文が完全に一致しない場合は、作成したテストデータベースに対してクエリを実行し、結果のデータセットと期待されるクエリの結果を比較しました。最後に、生成されたクエリと期待されるクエリを GPT-4 に渡し、クエリの同一性を評価しました。この方法で、各モデルについて 100 件のクエリの結果を評価しました。
結果
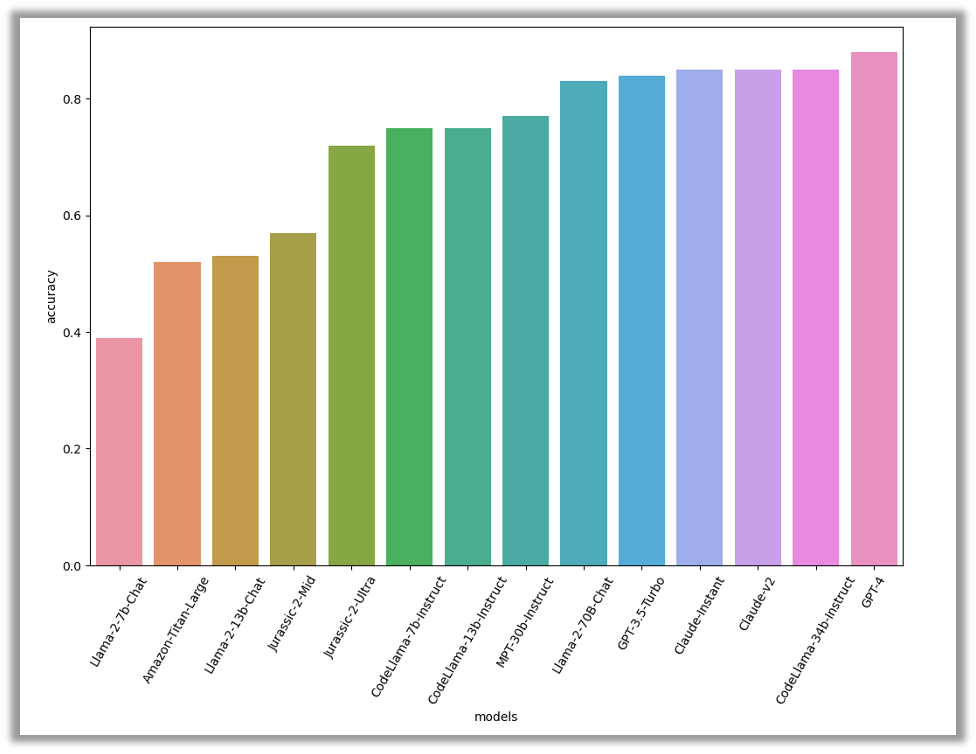
ソフォスの評価では、GPT-4 が 88% の精度で首位に輝きました。さらに、3 件のモデル (CodeLlama-34B-Instruct および 2 件の Claude モデル) が僅差で続きました。この 3 件はいずれも 85% の精度を記録しました。CodeLlama はコードの生成に重点を置いているため、このタスクにおける卓越した性能は予想されていました。
全体として、精度の高いスコアは、そのタスクがモデルにとって容易であることを示しています。この事実は、セキュリティインシデントを調査する際に、これらのモデルはそのままでも脅威アナリストを効果的に支援できる可能性があることを示唆しています。
タスク 2: インシデントサマリーの作成
セキュリティオペレーションセンター (SOC) では、脅威アナリストが毎日数多くのセキュリティインシデントを調査しています。通常、インシデントは検出された不審な活動に関連付けられ、ユーザーのエンドポイントまたはネットワーク上で発生した一連のイベントとして認識されます。脅威アナリストは、この情報を活用してさらなる調査を行います。しかし、この一連のイベントはノイズが多く、アナリストが全体を調査するのには時間を要することが多いため、注目すべきイベントの特定は困難です。大規模言語モデルは、特定のテンプレートに基づいてイベントデータの識別と体系化を支援することで、アナリストによる状況の理解を助け、次のステップの決定を容易にします。
このベンチマークでは、Sophos MDR (Managed Detection and Response) の SOC から取得した 310 件のインシデントのデータセットを使用しました。それぞれがキャプチャするセンサーによってスキーマと属性が異なる一連の JSON イベントとしてフォーマットされています。このデータは、データを要約する指示および要約プロセスのための事前定義されたテンプレートとともにモデルに渡されました。

各モデルによって生成されたサマリーを分析するために、5 つの異なる評価基準を使用しました。まず、生成されたインシデントの説明が、生のインシデントデータから適切な詳細をすべて正しく抽出していることを、絶対的基準となるサマリー (GPT-4 を使用して生成した後、ソフォスのアナリストが手動レビューで改善・修正したサマリー) と比較することで確認しました。

抽出されたデータが完全に一致しない場合、インシデントデータから抽出された各事実について最長共通部分列およびレーベンシュタイン距離を計算し、各モデルの平均スコアを導き出すことで、抽出されたすべての詳細が人力で作成したレポートからどの程度ずれているかを測定しました。さらに、 OpenAI の ADA2 モデルを使用した類似性スコアである BERTScore 指標、および METEOR 評価指標を使用して説明文を評価しました。
結果
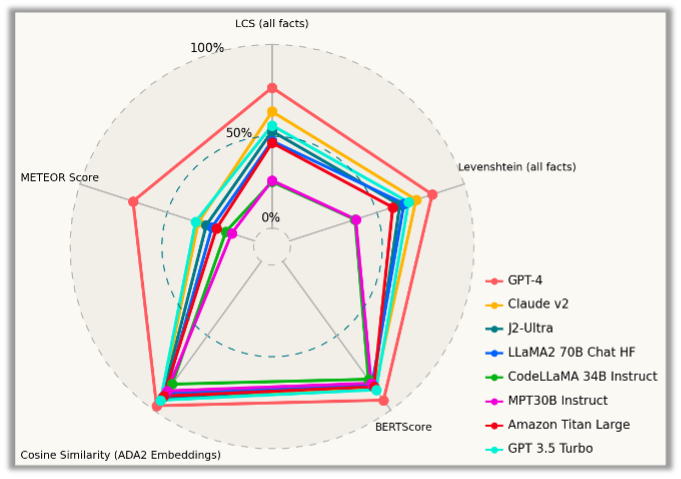
このベンチマークでも GPT-4 は、すべての側面で他のモデルより明確に優れており、再度勝者として際立っています。しかし、GPT-4 は、いくつかの定性的指標 (特に埋め込みベースのもの) において不当に有利です。なぜなら、評価に使用された基準セット自体が GPT-4 自身の助けを借りて作成されたものだからです。
他のモデルの中では、Claude-v2 モデルと GPT 3.5 Turbo が、独自モデルとしてトップクラスのパフォーマンスを発揮しました。オープンソースモデルでは Llama-70B モデルが最高のパフォーマンスを発揮しました。一方、MPT-30B-Instruct モデルと CodeLlama-34B-Instruct モデルは、質の高い記述を生成するのが困難であることがわかりました。
各モデルがどの程度イベントを要約できているのかについては、必ずしも数字がすべてを物語っているわけではありません。各モデルが何をしているのかをより詳しく把握するために、ソフォスはモデルによって生成された説明文を確認し、それらを定性的に評価しました。(お客様の情報を保護するため、生成されたインシデントサマリーの最初の 2 つのセクションのみを表示します。)
GPT-4 は質の高いサマリーを生成しました。記述は少し冗長でしたが、内容は正確でした。GPT-4 はまた、イベントデータから MITRE のテクニックを正しく抽出しました。しかし、MITRE のテクニックと戦術の区別を示すインデントは見落とされていました。

Llama-70B もすべてのアーティファクトを正しく抽出しました。しかし、ある事実 (アカウントがロックアウトされたこと) がサマリーに含まれていませんでした。また、MITRE のテクニックと戦術も区別されていませんでした。

一方、J2-Ultra はそもそもあまり良い結果を示しませんでした。MITRE のテクニックを 3 度も繰り返し記述した上に、戦術を完全に見逃しています。しかし、要約そのものは非常に簡潔で的を射ているように見えます。
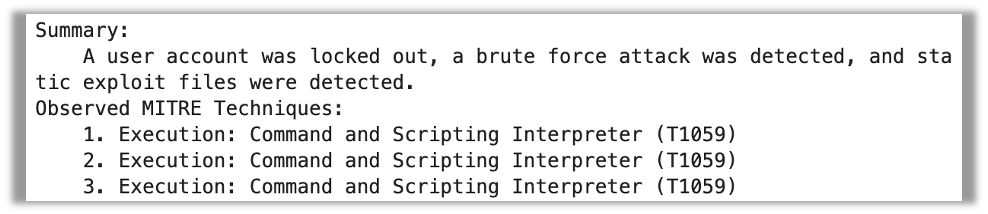
MPT-30B-Instruct は、まったくフォーマットに従わず、生データから得た情報を要約したパラグラフを作成しただけでした。

抽出された事実の多くは正しかったものの、出力結果は、提供したテンプレートに従った、整理されたサマリーに比べると、はるかに役に立ちませんでした。
CodeLlaMa-34B の出力はまったく使い物にならないもので、イベントデータを要約せずにそのまま記載した上に、いくつかのデータでは部分的に 「ハルシネーション」が発生していました。
タスク 3: インシデントの重大性評価
3 件目のベンチマークタスクは、従来の機械学習セキュリティに関する課題を修正したもので、観測されたイベントが無害な活動の一部であるか攻撃であるかを判定するものです。SophosAI では、ポータブル実行 (PE) ファイルやコマンドラインのような、特定のタイプのイベントを評価するために設計された ML モデルを利用しています。
このタスクの目的は、LLM が一連のセキュ リティイベントを調査し、その重大性の評価が可能かどうかを判断することです。各 LLM には、「深刻」「高」「中」「低」「要注意」の 5 つの選択肢から重大性のレーティングを割り当てるよう指示しました。以下が、このタスクのためにモデルに提供したプロンプトの形式です。

このプロンプトは、各重大度が何を意味するかを説明し、上述のタスクで使用したのと同じ JSON 検出データを提供するものです。イベントデータは実際のインシデントから得られたものであるため、各事例の最初の重大性評価と最終的な重大度レベルの両方が確認できます。3,300 件以上の事例に対して各モデルのパフォーマンスを評価し、その結果を測定しました。
今回対象となったすべての LLM の性能が、さまざまな実験設定を用いて評価されましたが、ランダムに割り当てた場合と比して十分な性能を示したものはありませんでした。ゼロショット設定 (青色) と最近傍探索を使った 3 ショット設定 (黄色) でテストを行いましたが、いずれのテストも精度の閾値である 30% に達しませんでした。
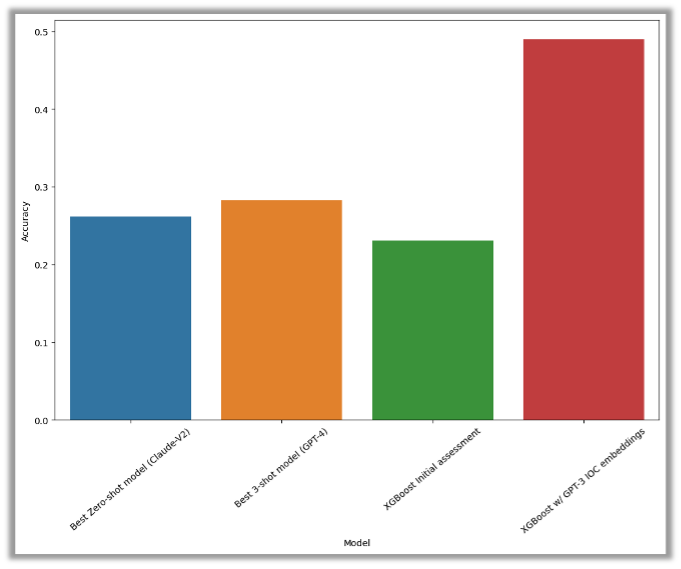
ベースライン比較として、トリガー検出ルールおよびアラートのタイプのみに従って初期の重大性を割り当てる XGBoost モデルを使用しました。このモデルのパフォーマンスは緑のバーで表されています。
さらに、GPT-3 で生成された埋め込みをアラートデータに適用したテストも実行しました (赤いバーで示されています)。その結果、精度が 50% に達するなど、大幅な性能向上が確認されました。
一般的に、大半のモデルはこの種のタスクを実行する能力を備えておらず、しばしばフォーマットに従う際に問題が生じることがわかりました。追加のプロンプト命令を生成したり、検出データを再生成したり、単にラベルを生成する代わりに重大度ラベルを出力するコードを書いたりといった、奇妙な失敗動作も確認されました。
結論
セキュリティアプリケーションにどのモデルを使用するかという問題は、多種多様な要素が絡む微妙な問題です。これらのベンチマークは、検討の出発点となる情報を提供しますが、必ずしもすべての潜在的な問題に対応しているわけではありません。
大規模言語モデルは、確かに脅威の探索やインシデントの調査支援に有効です。しかし現状では、ある程度のガードレールおよびガイダンスが必要です。ソフォスは、現状の LLM を用いた後、注意深く迅速なエンジニアリングを行うことで、この潜在的なアプリケーションを実現できると考えています。
生データからインシデント情報を要約する場合、ほとんどの LLM が (微調整による改善の余地はあるものの) 十分な性能を発揮します。 しかし、個々のアーティファクトやアーティファクトグループを評価することは、事前学習された、一般に利用可能な LLM には依然として困難なタスクです。この問題に取り組むには、サイバーセキュリティデータに特化して学習した専門的な LLM が必要になるかもしれません。
純粋な性能面では、GPT-4 と Claude v2 がすべてのベンチマークで最も優れたスコアを獲得しました。しかし、CodeLlama-34B モデルが最初のベンチマークタスクで好成績を収めたことは注目に値します。このモデルも SOC アシスタントとして導入する際の選択肢になり得るモデルだと考えています。