
Machine learning has many applications in information security. But you can’t take machine learning-generated models everywhere, especially on lower power edge devices. Sometimes you need something more lightweight to investigate possible malware. And in some cases, the only thing available is YARA, the multiplatform classification tool maintained by VirusTotal.
YARA classifies content by applying YARA rules –human-readable rules that identify text artifacts associated with a specific type of malicious code or content. But writing hand-crafted rules for YARA can be time consuming, and how well rules complete their task depends heavily on the rule-writer’s skill and judgement. Bringing the power of machine learning to the processs of creating YARA rules could significantly speed up and simplify their generation.
That’s precisely the idea behind Sophos’s experimental YaraML tool, developed by SophosAI chief scientist Joshua Saxe. YaraML can be used without any prior machine learning experience, but it also allows more advanced users familiar with machine learning projects to set customized parameters.
YaraML analyzes a dataset of benign and malicious labeled string artifacts to create YARA rules, extracting patterns that can be used to identify malicious string artifacts using YARA. Saxe used YaraML to create example YARA rules for detecting PowerShell malware, malware associated with the SolarWinds cyberespionage campaign, and macOS malware, which have also been published on the Sophos GitHub page.
While Sophos doesn’t use YARA as part of its products, YARA rules can be useful for incident responders and malware researchers, especially in situations where other types of tools aren’t available or are impractical to deploy. So the tool and rules have been shared as open source under the Apache 2.0 license in the hopes that they can provide assistance to the blue team and threat research community.
How to train your own model
YaraML is Python-based machine learning tool that lets you generate your own YARA rule from a dataset of malicious/benign labeled data. From that dataset, as final output, YaraML generates a complete, human readable (if not totally comprehensible) YARA rule that can be deployed as-is—or used alongside human-written rules.
To train your own model you need to have Python 3.6 or later installed on your computer. The code for YaraML can be retrieved from Sophos’ GitHub page. Its installation script will retrieve all the libraries required. Once installed, YaraML can be invoked from the command line in the following format:
yaraml [name for created model] [name for created Yara rule]
For example:
yaraml powershell_malware/ powershell_benign/ powershell_model powershell_detector
The script can perform one of two forms of binary classification using the Python scikit-learn library: logistic regression or random forest. By default, the script will use random forest; this can be changed at the command line A maximum number of sample files can also be set at the command line, as well as customized machine learning hyperparameters for those who want to tweak the model generated even further.
As far as how many files should be used when running YaraML, the same rule applies as when doing any model building: typically, the more training data, the better. YaraML can easily scale to hundreds of thousands of examples. Depending on what sort of representative data is available, 10,000 malicious and 10,000 benign samples is a good set to work from to be able to both train the model and verify the generated rules. But practically speaking, you may not have this many samples to work with.
For example, let’s look at how the PowerShell generic malware detection rule included in the GitHub repository was created. First, a collection of about 2,000 PowerShell malware samples was placed in the folder powershell_malware, and another 8,000 harmless PowerShell scripts were placed in a folder named powershell_benign. Then YaraML was launched with the following command line entry:
yaraml powershell_malware/ powershell_benign/ powershell_model powershell_detector --model_type="logisticregression"
This will launch YaraML and create both a machine learning model named powershell_model and a YARA rule named powershell_detector. The –model_type parameter set here set the analysis type to logistic regression. The model_type argument is handled in the YaraML script in the code shown below defining the machine learning task:
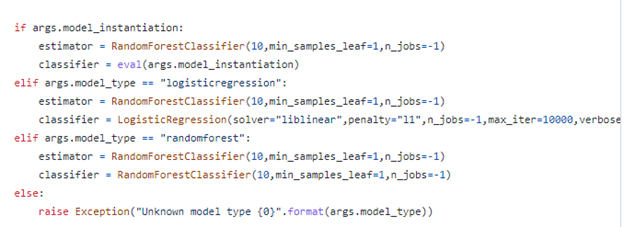
If you want to deviate from the built-in classification schemes in YaraML, you can further tweak the machine learning process by directly specifying hyperparameters that define how the model is built with the model_instantiation command line parameter For example:
--model_instantiation="LogisticRegression(penalty='l1',solver='liblinear')"
Furthermore, it’s possible to set a maximum number of files to use in building the model to speed up creation of the ruleset, which will likely result in lower accuracy but speed up rule deployment, by entering a max_benign_files and max_malicious_files parameter:
--max_benign_files=100 --max_malicious_files=100
When executed, YaraML will extract substring features from the samples and perform feature selection to downselect the number of features to avoid “overfitting” the model. It then trains a model based on the selected model type and features. Finally, YaraML “compiles” the model—turning the selected features and their weights as indicators into a textual Yara rule, which looks like the example below:
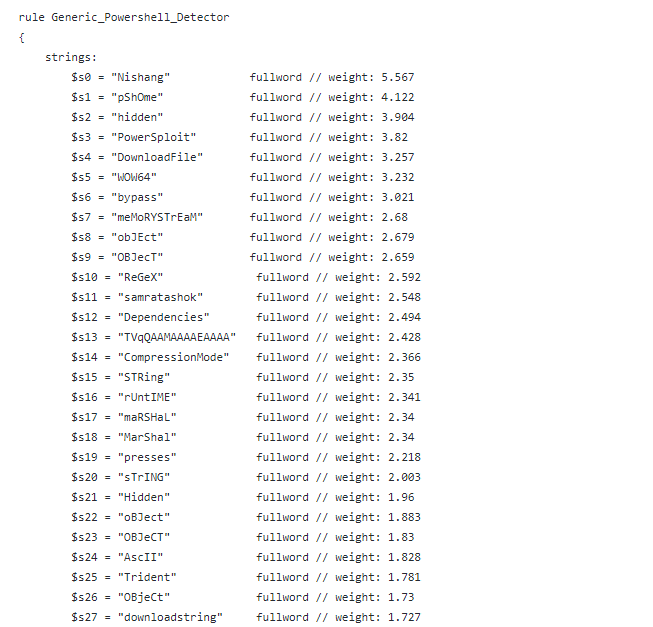
In the rule excerpt above, YaraML used a logistic regression classifier and automatically discovered important set of tokens (defined as $sXX) required for accurate classification of PowerShell commands. Those tokens are then summed together to create the final score.
At the end of the rule, there is a section labeled “condition” that applies a threshold for the weighted score to determine whether the detection rule is triggered. This threshold is automatically set by the tool, but it can be manually edited to tweak how the rule is applied—either to increase overall detection or reduce false positives. For logistic regression defined YARA rules, the condition statement is an equation that checks the sum of the tokens against a specific value:.

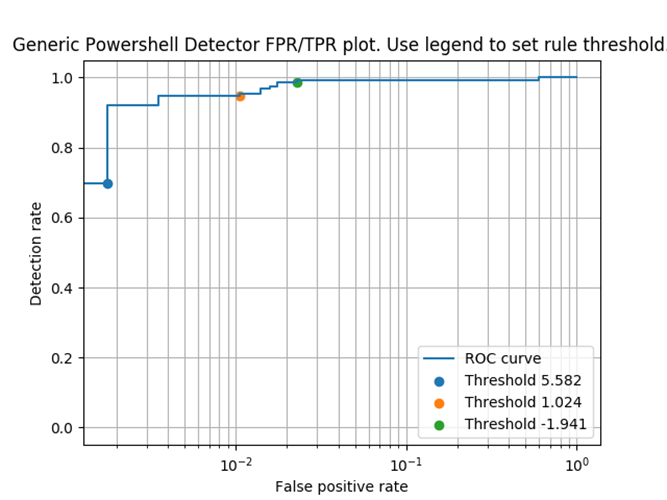
Changing the value after the “>” changes the threshold. Changing this number can either make the rule more aggressive in detecting malicious samples (resulting in more false positives), or reduce the number of false positives (resulting in more missed malicious files). Set it too low, and there will be too many false positives; set it too high and more malicious files will slip by. For example, here’s how different thresholds affected the PowerShell rule:
For rules created with a random forest classifier, the condition set is a collection of Boolean statements representing which defined trees have to be matched for an artifact to match the rule :

Caveat venator
Those using YaraML rules should be cautioned, as with all elements of machine learning systems, that there is no 100 percent accurate ruleset. Additionally, YaraML is an experimental tool, and we’ve posted it to share with the community in that context. There’s not likely to be much, if any, code maintenance, but it is offered under the Apache 2.0 license—so feel free to adapt the code further and use it as you see fit under those terms.