
Vous êtes dans une longue file d’attente à la gare et votre train doit partir bientôt, mais heureusement quatre guichets sont ouverts et la file avance plutôt rapidement et en douceur.
Vous aurez donc tout le temps d’acheter votre billet, de déambuler sur la plateforme et d’être fin prêt(e) pour partir en voyage !
Mais tout d’un coup, l’un des guichetiers sort une pancarte GUICHET FERME et quitte son poste. Au second guichet, le terminal de carte bancaire nécessite une intervention technique, et au troisième guichet un bourrage papier vient de se produire…
…et enfin vous entendez le client au dernier guichet ouvert dire : “j’ai changé d’avis finalement, je ne veux plus passer par le centre de Londres, je voudrais annuler ces billets que je viens d’acheter et trouver une option moins chère”.
Un retard, qui n’aurait causé qu’un léger énervement à un tout autre moment, finit par générer une attaque par déni de service sur votre trajet !
Il ne vous faudra peut-être pas une heure de plus pour acheter votre billet, mais il vous faudra surement attendre une heure supplémentaire pour le prochain train, après avoir manqué de peu celui-ci, que vous pensiez pourtant avoir largement le temps de prendre !
Si ce genre de mésaventure vous est déjà arrivée, vous apprécierez sans aucun doute cette étude provenant de la récente conférence cybersécurité USENIX 2018 : Freezing the Web: A Study of ReDoS Vulnerabilities in JavaScript-based Web Servers.

Le lien entre des trains manqués et des sites web bloqués peut ne pas être évidente de prime abord, alors expliquons-nous.
Les vieux serveurs web (d’accord, disons plutôt les serveurs vieillissants) comme Apache utilisent généralement un processus ou un thread séparé pour gérer chaque connexion entrante.
Les processus et les threads sont différents : en général, un processus est une application, en tant que telle, en cours d’exécution. Chaque processus peut ensuite être subdivisé en plusieurs sous-applications appelées threads, parfois appelées processus “léger” . Néanmoins, vous pouvez considérer les processus et les threads comme des programmes : en effet, ils sont créés, lancés, planifiés, gérés et supprimés par le système d’exploitation. Cela signifie que les démarrages, les basculements et les arrêts peuvent s’avérer relativement lourds, et cette surcharge peut réellement gêner un serveur web occupé à gèrer des centaines ou des milliers de connexions de courte durée, et ce chaque seconde.
Dans notre analogie avec le guichet de la gare, un serveur web multiprocessus ou multithread apparaît au niveau de votre guichet temporaire dès votre arrivée, et on vous affecte celle-ci indépendamment de l’activité au niveau des autres guichets.
Lorsque l’affluence est modeste, cela fonctionne vraiment très bien, car vous êtes à l’abri des effets néfastes d’un éventuel mélange avec d’autres voyageurs, parmi lesquels certains pourront poser des questions chronophages en pénalisant tout le monde.
Mais dans le cas d’une affluence massive, le modèle multiprocessus commence à devenir plus lent : en effet, le serveur et le système d’exploitation mettent plus de temps à créer des guichets séparés pour tout le monde, qu’à émettre des tickets, donc au final tout le monde attend plus longtemps que nécessaire.
Réagir au trafic, pas aux connexions
Cependant, de nombreux serveurs web modernes, notamment ceux écrits en JavaScript et qui utilisent des environnements de programmation tels que Node.js, sont pilotés par les événements plutôt que par les connexions.
En gros, le système confie à un seul processus le soin de gérer tout le trafic réseau, en travaillant sur les transactions en attente de tout utilisateur, et ce uniquement lorsqu’un évènement nouveau se produit.
Ce modèle ressemble plus à la file d’attente d’un fastfood, où vous passez votre commande à l’arrivée, et quand c’est prêt un employé appelle votre numéro pour que vous puissiez récupérer votre commande et partir.
Pendant que vous attendez, il est inutile d’avoir un membre du personnel spécialement chargé de s’occuper de vous, ou une caisse qui vous a déjà été affectée et qui par conséquent est bloquée jusqu’à ce que vous soyez prêt à payer.
Les membres du personnel d’un fastfood ou d’une friterie peuvent vous ignorer complètement pendant que vous attendez, mais vous attendez quand même, et eux continuent, imperturbables, de travailler à d’autres tâches.
Tant que vous êtes prévenu assez rapidement lorsque votre commande est prête, l’efficacité globale sera généralement plus élevée et le temps d’attente global sera donc plus court.
C’est de la théorie, bien évidemment !
Quand les choses se bloquent
Le modèle axé sur les événements a un point faible : il peut s’écrouler de manière désastreuse si quelques étapes clés du processus prennent plus de temps que prévu.
Cela revient à observer votre burger refroidir lentement derrière le comptoir, si par exemple vous avez le numéro de commande 32, mais que la personne en charge des commandes est occupée à résoudre un conflit avec le client numéro 31.
En d’autres termes, les serveurs évènementiels peuvent être très efficaces…
… à condition de ne pas devoir faire face à des événements inhabituels ou inattendus.
Et c’est justement ce que recherchaient nos experts : un code classique de gestion de contenu dans des serveurs web JavaScript qui gérait mal des données inattendues.
Déconstruire des requêtes web
Comme vous pouvez l’imaginer, les serveurs web doivent réaliser de nombreuses correspondances de motif basé sur du texte afin de déconstruire les requêtes web entrantes, ce qui peut ressembler à ceci :
GET /products/info.html HTTP/1.1 Host: example.com User-Agent: Mozilla/5.0 Accept-Language: en;q=0.5
Le terme consacré pour décrire la décomposition du texte saisi en composants majeurs est l’”analyse” (parsing).
Dans la demande web ci-dessus :
- La requête doit être découpée en lignes à chaque marqueur de fin de ligne ou retour chariot.
- La ligne
GETdoit être découpée à chaque caractère “espace”. - Les lignes d’entête doivent être séparées des deux côtés des “deux points”.
- L’entête
Accept-languagedoit ensuite être divisé au niveau du “point-virgule”. - Le paramètre
q=0.5doit être décomposé sous la forme “key=value” au signe “égal” (Q est un raccourci d’entête HTTP pour “qualité”, bien qu’il désigne ici de manière plutôt insignifiante “preference”).
Dans de nombreux langages de programmation modernes, notamment JavaScript, la technique de référence pour la correspondance de texte est un outil appelé Expression Régulière, ou ER en abrégé.
C’est de là que provient le nom de la menace ReDoS dans le titre de l’article : cela signifie Déni de Service (paralysie du serveur) via des Expressions Régulières.
La correspondance de texte simplifiée
Examinons le problème de prendre la chaîne de texte q=0.5 et de la diviser en q et 0.5, afin d’interpréter sa signification.
L’ancienne manière de procéder, familière à tous ceux qui ont utilisé le langage de programmation BASIC, serait de la coder à la main, en commençant par quelque chose comme ceci :
POS = FIND(STR$,'=')
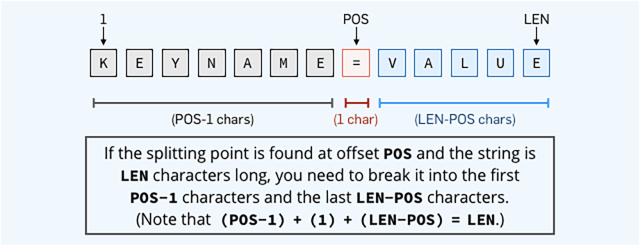
Nous supposons que FIND recherche la position du premier signe “=” dans la variable de texte STR$ et renvoie sa position, de 1 (la position du premier caractère) à LEN(STR $), la longueur de la chaîne (la position du dernier caractère).
Si FIND retourne la valeur zéro, cela signifie qu’il n’a rien trouvé. Sinon, il nous indiquera l’endroit où la recherche s’est avérée fructueuse, nous indignant ainsi où exactement décomposer l’entrée en “key” (le côté gauche) et en “value” (le côté droit).
Nous devons prendre les “POS-1” caractères à gauche du signe égal pour la “key“. Pour la “value“, nous prenons les “POS” caractères soustrait à la longueur de la chaîne à partir de l’extrémité droite :
POS = FIND(STR$,"=") : REM Look for an equals IF POS > 0 THEN : REM If there is one... KEY$ = LEFT$(STR$,POS-1) : REM ...chop from the left VAL$ = RIGHT$(STR$,LEN(STR$)-POS) : REM ...and to the right END
Ce code est assez facile à comprendre et très efficace, car il code précisément et simplement l’algorithme qui consiste à “rechercher le point de division et à effectuer ensuite le découpage”.
Mais c’est un peu pénible de devoir faire appel au processus de recherche de correspondance au niveau d’un motif, au lieu de simplement exprimer un motif et laisser un utilitaire faire la recherche, ce que vous pouvez faire avec les Expressions Régulières.
Voici une ER qui pourrait être utilisé, pas de manière optimale mais assez efficacement tout de même, à la place du code plutôt rigide ci-dessus : (.+)=(.+).
Les Expressions Régulières ont l’air énigmatique, du fait de la manière étrange et déroutante d’utiliser des caractères comme abréviations. En effet, leur côté cryptique favorise les erreurs :
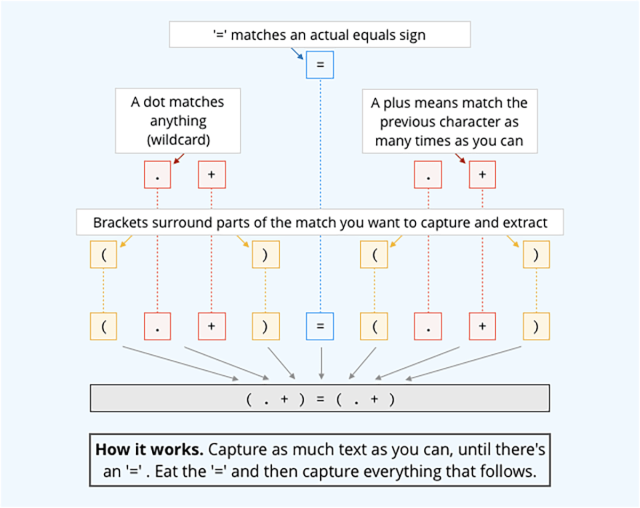
Facile de se tromper
Une fois que vous vous êtes habitué aux Expressions Régulières, elles sont difficiles à éliminer, car elles sont simples et expressives.
Dans un langage de programmation moderne, vous pourriez être en mesure de remplacer le code suivant : où str.find correspond à un caractère et str.sub extrait explicitement une sous-chaîne…
pos = str.find('=')
if pos then
key = str.sub(1,pos-1)
val = str.sub(pos+1)
else
key = nil
end
… par l’utilisation d’une bibliothèque de correspondance-ER, plus élégante et plus facile à adapater :
key,val = str.match('(.+)=(.+)')
Le problème, comme le soulignent les chercheurs ayant travaillé sur le document ReDoS, est que les Expressions Régulières, comme celle ci-dessus, font le travail que vous souhaitez et passent facilement les tests d’acceptation des logiciels, tout en faisant en même temps du mauvais travail.
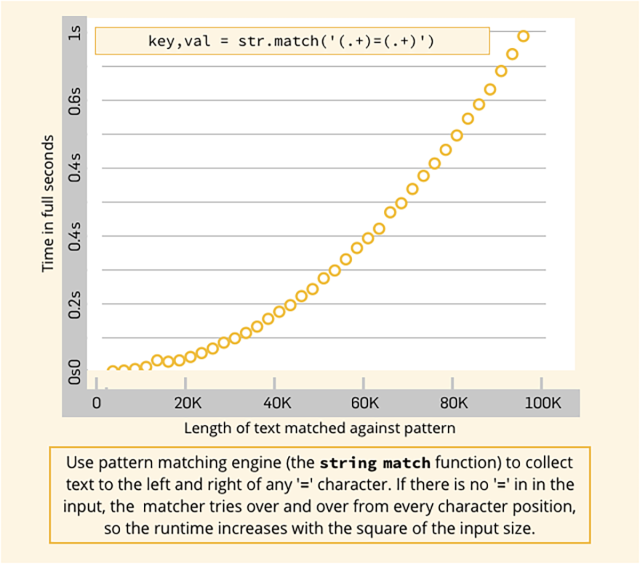
Le problème est que l’ER ci-dessus travaille sur n’importe quelle zone du texte d’entrée, et la fonction str.match essaie autant que possible de trouver une correspondance, ayant un effet secondaire très chronophage que vous ne remarquerez probablement pas avant que :
- L’entrée ait une longueur de plus de quelques milliers de caractères.
- L’entrée ne contienne pas DU TOUT de signe “égal”.
Notez que le seul caractère que cette ER ait à verrouiller explicitement est un signe “égal”.
S’il n’y a pas de signe “égal”, l’ER testera sa correspondance de motif à partir de la position 1 dans la chaîne d’entrée, mais échouera, elle réessayera alors à partir de la position 2 et échouera de nouveau, puis à partir du troisième caractère, et ainsi de suite.
Par conséquent, elle testera son motif par rapport aux caractères 1 à LEN au niveau de l’entrée, puis de manière redondante avec les caractères 2 à LEN, mais de nouveau sans succès, et ainsi de suite jusqu’à obtenir moins de trois caractères (l’ER ne peut établir de correspondance avec moins de trois caractères, le motif a besoin d’au moins un caractère avant le signe “égal”, en plus de ce dernier, et d’au moins un caractère après celui-ci).
S’il y a LEN caractères au niveau de l’entrée, la fonction de correspondance finit par s’exécuter LEN fois, contre une moyenne de caractères de LEN/2, ce qui est proportionnel au carré de LEN, provoquant ainsi une baisse massive des performances lorsque LEN augmente !
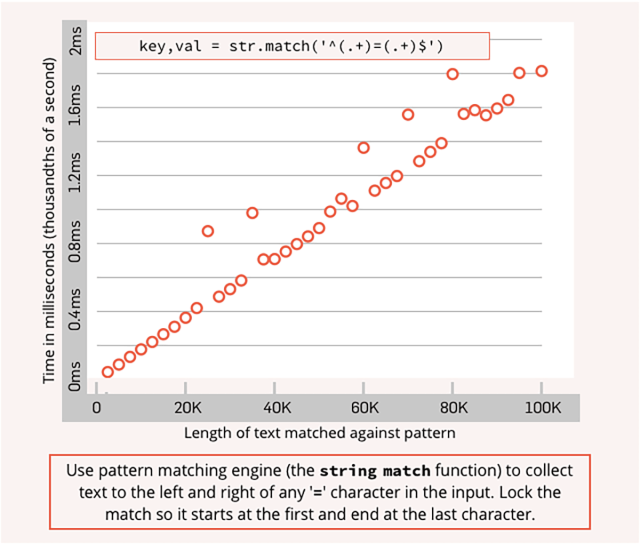
Vous devez indiquer à la fonction ER de verrouiller la recherche de correspondance au début de l’entrée afin qu’elle ne parcoure les données d’entrée qu’une seule fois.
Pour cela, vous pouvez utiliser les caractères ER spéciaux tels que ^, signifie ainsi “ne rechercher des correspondances qu’au tout début”, et $, qui signifie “ne rechercher des correspondances qu’à la toute fin”.
C’est ce qu’on appelle l'”ancrage” (anchoring) de la recherche.
La différence en matière de performance est énorme et devient quadratiquement pire pour des correspondances non ancrées à mesure que l’entrée devient plus longue.
Notez que dans les graphiques ci-dessous, l’axe indiquant les performances linéaires de la correspondance ancrée atteint au maximum 2/1000ème de seconde pour une chaîne d’entrée de 100K, tandis que la correspondance non ancrée prend plus d’une seconde complète pour le même travail !
C’est 500 fois moins rapide en raison du caractère de verrouillage ^ manquant au début de l’ER, avec un écart qui se creuse à un rythme toujours croissant à mesure que la taille de l’entrée augmente :
Quoi faire ?
L’article ReDoS n’est pas vraiment une mauvaise nouvelle, mais c’est un rappel fort que le code qui semble correct, et qui fonctionne réellement, risque de ne pas fonctionner correctement dans la vraie vie.
En particulier, saturer un serveur web événementiel avec des entêtes HTTP conçus de manière pathologique (à savoir avec une analyse effectuée systématiquement pour chaque requête entrante) pourrait permettre de bloquer un serveur, par ailleurs sécurisé, avec une attaque ReDoS.
Les chercheurs ont découvert de nombreux exemples de code dans le monde réel qui, en théorie, pourraient très facilement être réduits à néant en raison d’une utilisation trop occasionnelle des Expressions Régulières pour pré-traiter les entêtes web.
Si vous parvenez à identifier un entête mal structuré sur lequel une chaîne mal choisie bloquera une ER de correspondance, vous disposez de la matière première pour un ReDoS.
Dans certains cas, les Expressions Régulières dangereuses, à savoir celles potentiellement à l’origine d’un ReDoS, n’étaient pas propres au code personnalisé d’une entreprise, mais étaient héritées d’une bibliothèque de programmation standard.
Heureusement, les problèmes sont facilement résolus :
- Examinez attentivement le code correspondant au motif. Les performances sont importantes, en particulier lorsqu’elles peuvent être affectées par des données non fiables envoyées de l’extérieur.
- Inclure des échantillons pathologiques dans votre ensemble de test. Ne testez pas la correspondance de motif uniquement pour ses capacités d’acceptation/de rejet. Vérifiez qu’elle peut accepter ou rejeter des données dans des délais bien définis.
- Limitez la durée pendant laquelle une fonction de correspondance de motif peut être exécutée. Les chercheurs ont découvert au moins une ER côté serveur qui fonctionnait de manière exponentielle avec la longueur de l’entrée, ce qui est bien plus dramatique et risqué que les performances quadratiques présentées ci-dessus.
- Traitez les modèles qui fonctionnent mal comme de réels problèmes. Les Expressions Régulières complexes qui fonctionnent parfois longtemps sont plus susceptibles de trouver des correspondances là où elles ne devraient pas : ce que l’on appelle un faux positif. Plus le temps de réponse est long, plus il est difficile de trouver une correspondance et plus le temps nécessaire pour trouver une correspondance imprévue est long également.
- Lisez l’article sur ReDoS. Certaines des Expressions Régulières problématiques rencontrées dans le monde réel proviennent de bibliothèques standards, donc ce n’est pas seulement votre propre code qui présente un risque. Ainsi, apprenez à repérer les problèmes avant qu’ils ne surviennent !
- Diviser et conquérir. Une série de vérifications simples et faciles à comprendre est beaucoup plus aisé à tester et à gérer qu’une super-combinaison méga-complexe qui tente de regrouper plusieurs tests dans une seule formule obscure.

Billet inspiré de Serious Security: How to stop dodgy HTTP headers clogging your website, sur Sophos nakedsecurity.
Qu’en pensez-vous ? Laissez un commentaire.