
Googlebot toujours la cible de nouvelles techniques de SEP
De nos jours, toutes les entreprises savent qu’avoir son site internet en première page de Google, avec les bons mots clés, fait la différence en terme de trafic, et aide largement au développement de l’activité. De nombreuses techniques de existent depuis des années, et ont permis à de nombreux marketeurs de grimper la fameuse échelle du PageRank.
 En résumé, pour être populaire sur Google, votre site web doit proposer du contenu original, en rapport avec les mots clés choisis, mais doit aussi contenir des liens vers un certain nombre de sites pertinents, qui ont déjà une réputation sur la toile (ces derniers agissent comme des recommandations, et sont souvent nommés abusivement «back links», même si en réalité, votre site ne crée pas le lien vers eux).
En résumé, pour être populaire sur Google, votre site web doit proposer du contenu original, en rapport avec les mots clés choisis, mais doit aussi contenir des liens vers un certain nombre de sites pertinents, qui ont déjà une réputation sur la toile (ces derniers agissent comme des recommandations, et sont souvent nommés abusivement «back links», même si en réalité, votre site ne crée pas le lien vers eux).
Les algorithmes de Google sont bien plus complexes que cette simple description. Cependant, la plupart des techniques d’optimisation tournent inlassablement autour de ces 2 objectifs prioritaires. La plupart des techniques d’optimisation qui sont utilisées sont légitimes, éthiques et approuvées par Google et d’autres moteurs de recherche. Or, il existe aussi d’autres techniques, ou plutôt astuces, parfois plus efficaces, qui reposent sur différentes manières illégales d’utiliser internet, telles que la falsification, le spamming et le piratage, avec pour but ultime de tromper les algorithmes de Google.
L’une de ces techniques, connue sous le nom de cloaking, a pour but de tromper le système d’indexation des pages sur Google. Récemment, nous avons identifié une nouvelle technique de cloaking, qui semble fonctionner efficacement dans le contournement des algorithmes de défense de Google.
Le principe du cloaking est de fournir aux moteurs de recherche de Google un certain type d’information lors du crawling, mais montre tout à fait autre chose aux visiteurs du site.
Cette situation est possible car les moteurs de recherche révèlent leur présence par la mise en place d’un champ spécifique au sein de la requête interne, concernant un contenu particulier. Là où votre navigateur afficherait le texte suivant “User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3)” au niveau de la requête web, Google s’identifie comme Googlebot.
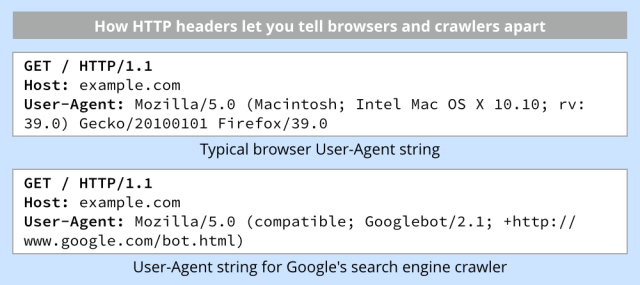
Une page cloakée va fournir au un contenu qui est rempli de mots clés qui permettent de définir votre site comme un site pertinent, par rapport à une recherche de contenu spécifique. Dans le passé, cette technique était utilisée massivement par les attaques de malwares, ainsi en cherchant «Justin Bieber», et en cliquant sur un des liens dans les résultats trouvés, vous pouviez vous retrouver sur un site malveillant sous le contrôle d’exploits (Spamdexing utilisé pour des attaques SEO : comment se protéger?).
Cependant, le visiteur lambda verra uniquement une page normale, tout semblerait tout à fait classique, et personne ne se rendra compte d’un problème à signaler.
La deuxième technique, très utilisée, pour manipuler les résultats de recherche est de s’assurer que le Googlebot voit d’autres sites pertinents et bien classés, qui incluent des liens vers le vôtre. Cette technique permet d’être considéré par un Googlebot comme un site populaire et reconnu par d’autres utilisateurs du net, en plus d’être vu comme un site pertinent, d’un point de vue des mots clés. Pour en arriver à ce résultat, les marketeurs honnêtes se contentent de générer du contenu original et attractif, en établissant des accords de cross-linking, en faisant la promotion de leurs sites sur les réseaux sociaux, et en payant pour se faire connaitre grâce à la publicité. De l’autre côté, les marketeurs moins honnêtes, spamment leurs liens sur des blogs ou des forums, en postant de faux commentaires, et en créant des sites web dédiés pour former une «ferme de liens» (link farm). Enfin, dans le pire des cas, ils pirateront des sites officiels pour y insérer de pages qui pointeront vers leurs sites. Cette technique est connue sous le nom de link-spamming.
En réponse au link-spamming, les ingénieurs de Google ont apporté des améliorations à leurs algorithmes de page-ranking (notamment grâce à la sortie du nouvel algorithme Panda). Ces améliorations ont pour objectif principal de rendre compliqué, et surtout financièrement coûteux, d’atteindre un PageRank élevé, en utilisant des techniques douteuses.
La découverte, que nous avons faite, d’un nouveau moyen de manipuler les résultats de recherche, est venue de la détection, au niveau de notre Antivirus Sophos, créée par Jason Zhang du SophosLabs, et basée sur des fichiers PDF suspects. Au final, nous avons reçu des centaines de milliers de documents PDF du même fichier par jour, ce qui a déclenché tout simplement la détection.
Après une rapide inspection, nous avons réalisé que quelqu’un avait utilisé la technique du cloaking pour fausser les résultats de recherche, mais au lieu de fournir de fausses pages HTML au Googlebot, il avait utilisé des PDFs.
Selon nous, les algorithmes de détection du cloaking de Google, qui ont pour but de repérer les pages web qui ont été artificiellement (et de manière irréaliste) chargées avec des mots clés, ne sont pas si stricts avec du contenu bidon, qui est intégré dans des documents. Il semble que de façon implicite, Google fasse confiance davantage aux fichiers PDF qu’aux pages HTML. De la même manière Google fait davantage confiance aux liens .edu et .gov, qu’aux liens commerciaux, .com.
Ainsi, en faisant une recherche sur Google en utilisant les mots clés trouvés à l’intérieur des fichiers PDF, nous avons trouvé une large quantité de ce type de document sur de nombreux sites officiels, mais sans lien et probablement corrompus. En plus de l’utilisation massive de mots clés spécifiques, les PDFs comprenaient des liens vers des documents localisés sur d’autres sites web, formant ainsi une dénommée “black link wheel”

Cependant, l’astuce semble avoir été assez efficace pour tromper Googlebot, en donnant artificiellement à ces documents un classement assez élevé.
La dernière étape de cette technique, était de rediriger les utilisateurs insouciants qui avaient cliqué sur le lien, vers un site publicitaire.
Nous pensons que cette technique peut être utilisée à d’autres fins, notamment la propagation de malwares. Néanmoins, pour l’instant, nous l’avons seulement observée dans des opérations marketing, pour promouvoir des services de courtage appelés «binary trading».
Voici un exemple de la première page des résultats de recherche faussés :
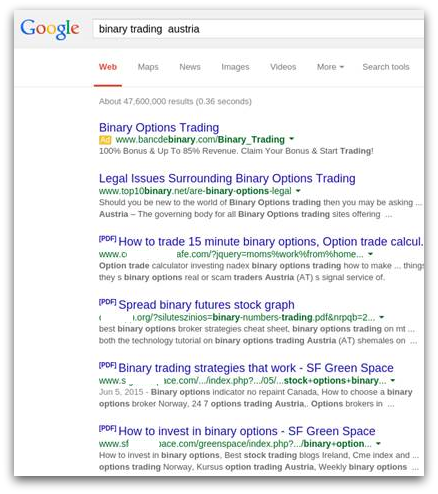
Presque tous les liens que l’on peut voir au niveau des résultats de la recherche appartiennent à cette campagne marketing. Cette technique est particulièrement efficace lorsque vous cherchez des combinaisons de mots clés à faible occurrence, telles que «Austria» et «binary trading», comme le montre l’exemple ci-dessus.
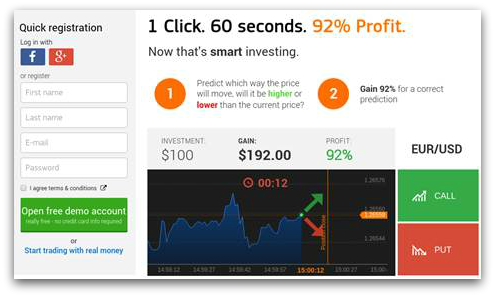
Après avoir cliqué sur le lien PDF, ce dernier vous redirige vers un site web de courtage en bourse, proposant une option binaire :
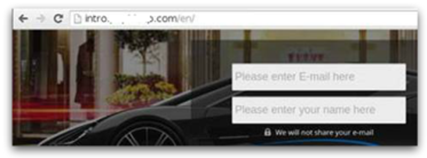
Plus loin, les mêmes liens pointent vers une arnaque, apparemment différente, pour devenir riche rapidement :
Afin de voir le fameux fichier PDF, nous devons sélectionner sa version cachée, dans les résultats de recherche de Google, dans le menu se situant à côté du lien :

Un document qui a l’air valable à première vue, se transforme en une chose complètement insensée lorsque vous commencez à le lire. En plus, vous pouvez clairement voir les hyperliens placés au sein du document. Ces derniers sont les liens qui, lorsqu’ils sont suivis, soumettent l’intégralité de la ferme de liens à Googlebot.
D’autres phrases et davantage de combinaisons de mots clés, dans le document, nous donne une petite idée de ce que nous pourrions encore chercher. Une analyse rapide révèle que beaucoup de combinaisons de 3 mots, trouvées dans le document, en cas de saisie, mèneraient au même PDF. Même une recherche plutôt large comme «safe stock trade US», amèneraient ces liens vers le haut du classement :
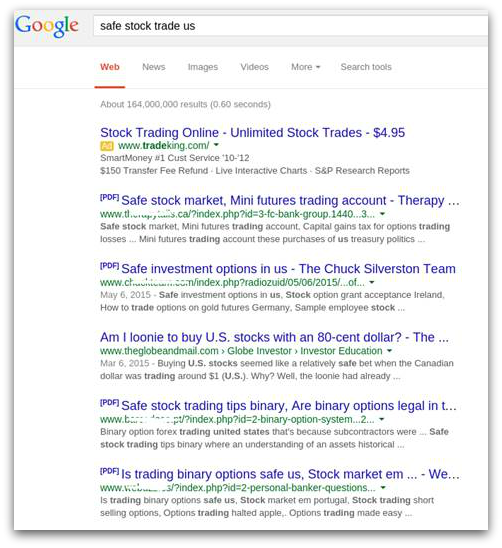
Afin de mieux voir ce qui se passe lorsque Google effectue le crawling du lien, nous pouvons lancer un programme web client avec comme User-Agent header : Googlebot.
$ curl -is --user-agent "Googlebot" "http://www.[WEBSITE].com/?index.php?id=[ARGS]"
HTTP/1.1 200 OK
Date:
Server: Apache
Transfer-Encoding: chunked
Content-Type: application/pdf
%PDF-1.3
1 0 obj
<< /Type /Catalog
/Outlines 2 0 R
[...]
Cependant, pour observer ce que des utilisateurs insouciants verraient s’ils cliquaient sur ce qu’ils penseraient être un lien vers un fichier PDF, nous pouvons tout simplement utiliser un navigateur internet avec les outils développeur. Voici un exemple de la chaîne de redirection qui est mise en place :

Sans surprise, la redirection implique des sites qui vont passer par un identifiant unique du marketeur affilié, responsable de la campagne.
Nous avons fourni des informations détaillées au sujet de nos découvertes à Google, avec une mise en garde concernant notre intention de les publier. Google a pris acte de notre communication, mais n’a pas désiré faire plus de commentaires. Nous leur faisons confiance pour mettre en place les mesures nécessaires afin de bloquer ces tentatives de manipulation des résultats de recherche.
Suivre @SophosFrance
//
// ]]>
Suivre @JeromeVosgien
//
// ]]>
Billet inspiré de : “Google search poisoning – old dogs learn new tricks” de Dmitry Samosseiko du Blog Sophos
Partagez “Googlebot toujours la cible de nouvelles techniques de SEP” avec http://wp.me/p2YJS1-1Xf