



Aunque no parezca tan central para la seguridad como la protección contra el malware y la detección de infracciones, el filtrado de contenidos web desempeña un papel importante para garantizar el cumplimiento de la normativa y la seguridad de los lugares de trabajo, así como la seguridad de la red. A diferencia de la clasificación de seguridad de las URL, que busca contenido malicioso como malware o phishing, el filtrado web tiene que etiquetar el contenido basándose no en mecanismos de ataque, sino en la naturaleza de su contenido, un problema mucho más generalizado que la comprobación de patrones maliciosos en el contenido que hay detrás de una URL.
Las etiquetas de categorías de sitios web describen generalmente cuál es el contenido o el propósito del sitio. Algunas categorías son clasificaciones amplias, como “negocios”, “ordenadores e Internet”, “comida y cena” y “entretenimiento”. Otras se centran en la intención, como “banca”, “compras”, “motores de búsqueda”, “medios sociales”, “búsqueda de empleo” y “educación”. Y luego hay categorías que pueden incluir contenido preocupante: “sexualmente explícito”, “alcohol”, “marihuana” y “armas”, por ejemplo. Las organizaciones pueden querer establecer diversas políticas para filtrar o medir los tipos de sitios web a los que se accede desde sus redes.
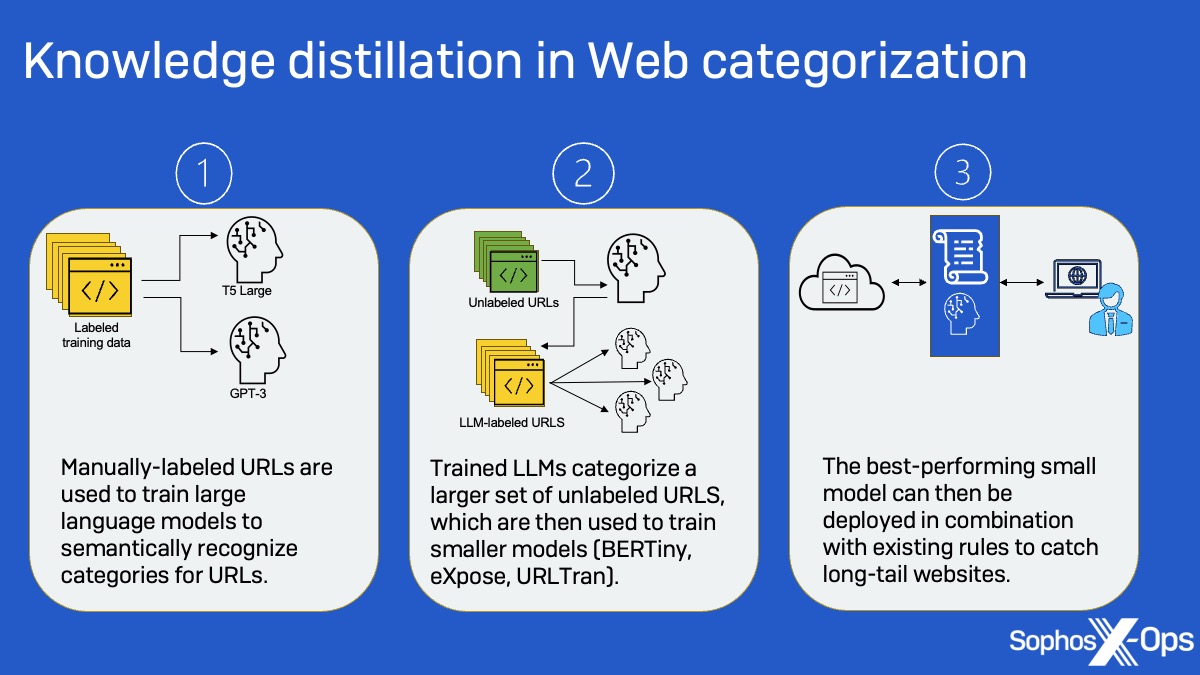
Sophos X-Ops ha estado investigando formas de aplicar el machine learning de grandes modelos de lenguaje (LLM) al filtrado web para ayudar a capturar la “larga cola” de sitios web: esos millones de dominios que tienen relativamente pocos visitantes y poca o ninguna visibilidad para los analistas humanos. Los LLM en sí mismos no son prácticos para esta aplicación debido a su tamaño y al coste de los recursos informáticos. Sin embargo, pueden utilizarse a su vez como modelos “maestros” para entrenar a modelos más pequeños en la categorización, reduciendo los recursos informáticos necesarios para generar etiquetas sobre la marcha para los dominios recién encontrados.
Utilizando LLM como el GPT-3 de OpenAI y el T5 Large de Google , el equipo de SophosAI pudo entrenar sobre la marcha modelos mucho más pequeños para clasificar URL nunca antes vistas. Y lo que es más importante, la metodología empleada aquí podría utilizarse para crear modelos pequeños y económicamente desplegables basados en los resultados de los LLM para otras tareas de seguridad.
La investigación del equipo, detallada en un artículo publicado recientemente y titulado “Web Content Filtering Through Knowledge Distillation of Large Language Models” (Filtrado de contenidos web mediante la destilación de conocimientos de grandes modelos lingüísticos), explora las formas en que los LLM pueden utilizarse para reforzar la actual clasificación de sitios realizada por humanos, y para crear sistemas que puedan desplegarse para realizar el etiquetado en tiempo real de URL nunca antes vistas.
El problema de la “larga cola”
La categorización de los sitios se ha basado en gran medida en el mapeo de dominio a categoría basado en reglas, en el que se utilizan firmas elaboradas por analistas para buscar indicios en las URL y asignar rápidamente etiquetas a los nuevos dominios. Este tipo de mapeo es vital para etiquetar rápidamente las URL de sitios conocidos y evitar falsos positivos que bloqueen contenidos importantes. La identificación humana práctica de patrones de clasificación de sitios se reincorpora a los conjuntos de funciones de las herramientas de mapeo de dominios.
El problema surge con la “larga cola” de los sitios web, es decir, los dominios menos visitados a los que normalmente no se asignan firmas. Con la aparición diaria de miles de nuevos sitios web, y con más de mil millones de sitios web existentes, mantener y ampliar manualmente los enfoques basados en firmas para la larga cola se ha convertido en un reto cada vez mayor. Esto se hace evidente en la pronunciada caída del etiquetado de los dominios menos visitados: mientras que los sitios conocidos y de gran tráfico obtienen una cobertura de casi el 100% en la mayoría de los esquemas de etiquetado, como se muestra en el diagrama siguiente, la proporción de dominios etiquetados por los analistas comienza a caer rápidamente más allá de los cien primeros dominios visitados. Los sitios clasificados por debajo de los 5000 primeros tienen menos del 50% de probabilidades de haber sido etiquetados por su contenido.
Figura 1. Etiquetado del contenido relativo a la popularidad de los dominios, derivado de la telemetría. Una forma de solucionar esto es mediante la aplicación del machine learning para procesar dominios no etiquetados previamente. Pero hasta ahora, la mayoría de los esfuerzos de machine learning (como URLTran de Microsoft) han utilizado modelos de aprendizaje profundo para centrarse en la tarea de detectar amenazas a la seguridad, en lugar de categorizar los sitios según su contenido. Estos modelos podrían reentrenarse para realizar una clasificación multicategoría, pero requerirían conjuntos de datos de entrenamiento extremadamente grandes. URLTran utilizó más de 1 millón de muestras solo para entrenarse en la detección de URL maliciosas.
Automatización con IA
Ahí es donde entran en juego los LLM. Como están preentrenados en cantidades masivas de texto sin etiquetar, el equipo de SophosAI creyó que los LLM podían utilizarse para realizar el etiquetado de URL con mayor precisión y con muchos menos datos iniciales. Cuando se perfeccionaron con datos etiquetados con firmas de propagación de dominios, el equipo de SophosAI descubrió que los LLM tenían un 9% más de precisión que la arquitectura de modelos de última generación de Microsoft a la hora de abordar el problema de la categorización de “larga cola”, y solo necesitaban un conjunto de entrenamiento de miles de URL, en lugar de millones.
Los LLM, utilizando relaciones semánticas entre las clases de sitios y las palabras clave dentro de las URL en un conjunto de datos más pequeño, se utilizaron después para crear etiquetas para un conjunto de datos sin etiquetar de sitios de larga cola que, a su vez, se utilizaron para entrenar modelos más pequeños (los modelos transformadores BERTiny y URLTran basados en BERT y el modelo convolucional 1D eXpose). Este enfoque de “destilación de conocimientos” permitió al equipo alcanzar niveles de rendimiento similares a los del LLM con modelos 175 veces más pequeños, reduciendo el número de parámetros de 770 millones a sólo 4 millones.
Aunque los conjuntos de modelos más precisos creados funcionaron mucho mejor que los modelos entrenados únicamente mediante “aprendizaje profundo”, su precisión no alcanzó la perfección: incluso los mejores modelos obtuvieron una precisión inferior al 50%. Muchas URL no se etiquetaron correctamente simplemente porque no tenían suficientes “señales” incrustadas, mientras que otras tenían palabras clave que podían asociarse a múltiples clasificaciones, creando una incertidumbre que solo podía aclararse mediante un examen más profundo del contenido que había detrás de la URL.
Sin embargo, el modelo T5 Large funcionó razonablemente bien en categorías que potencialmente se filtrarían, como se muestra en la matriz de confusión de abajo: los sitios de apuestas y de intercambio entre iguales tuvieron un etiquetado casi perfecto en los datos de prueba. Los sitios de alcohol, armas y pornografía también tuvieron tasas de detección de verdaderos positivos superiores al 60%.
El equipo de SophosAI ha sugerido varias formas de mejorar esta precisión en el futuro. En primer lugar, permitir la asignación de múltiples categorías a un sitio eliminaría los problemas de solapamiento de categorías. Aumentar las muestras de URL con HTML recuperado e imágenes de las mismas también podría proporcionar un mejor reconocimiento de su categorización, Y podrían utilizarse LLM más recientes, como el GPT-4, como profesor.
Combinada con los procesos existentes, esta forma de clasificación basada en la IA puede mejorar mucho el tratamiento de los sitios web de cola larga. Y hay otras tareas relacionadas con la seguridad a las que podría aplicarse la metodología de “destilación de conocimientos” probada en este experimento.
Para más detalles, consulta el artículo escrito por Tamas Voros, Sean Bergeron y el Director de SophosAI Konstantin Berlin en arxiv.org.