
Well-known cybersecurity researcher Fabian Bräunlein has featured not once but twice before on Naked Security for his work in researching the pros and cons of Apple’s AirTag products.
In 2021, he dug into the protocol devised by Apple for keeping tags on tags and found that the cryprography was good, making it hard for anyone to keep tabs on you via an AirTag that you owned.
Even though the system relies on other people calling home with the current location of AirTags in their vicinity, neither they nor Apple can tell whose AirTag they’ve reported on.
But Bräunlein figured out a way that you could, in theory at least, use this anonymous calling home feature as a sort-of free, very low-bandwidth, community-assisted data reporting service, using public keys for data signalling:
He also looked at AirTags from the opposite direction, namely how likely it is that you’d spot an AirTag that someone had deliberately hidden in your belongings, say in your rucksack, so that they could track you under cover of tracking themselves:
Indeed, the issue of “AirTag stalking” hit the news in June 2022 when an Indiana woman was arrested for running over and killing a man in whose car she later admitted to planting an AirTag in order to keep track of his comings and goings.
In that tragic case, which took place outside a bar, she could probably have guessed were he was anyway, but law enforcement staff were nevertheless obliged to bring the AirTag into their investigations.
When security scans reveal more than they should
Now, Bräunlein is back with another worthwhile warning, this time about the danger of cloud-based security lookup services that give you a free (or paid) opinion about cybersecurity data you may have collected.
Many Naked Security readers will be familiar with services such as Google’s Virus Total, where you can upload suspicious files to see what static virus scanning tools (including Sophos, as it happens) make of it.
Sadly, lots of people use Virus Total to gauge how good a security product might be at blocking a threat in real life when its primary purpose is to disambiguate threat naming, to provide a simple and reliable way for people to share suspicious files, and to assist with prompt and secure sample sharing across the industry. (You only have to upload the file once.)
This new report by Bräunlein looks at a similar sort of public service, this time urlscan.io, which aims to provide a public query-and-reporting tool for suspicious URLs.
The idea is simple… anyone who’s worried about a URL they just received, for example in what they think is a phishing email, can submit the domain name or URL, either manually via the website, or automatically via a web-based interface, and get back a bunch of data about it.
Like this, checking to see what the site (and the community at large) think of the URL http://example.com/whatalotoftextthisis:
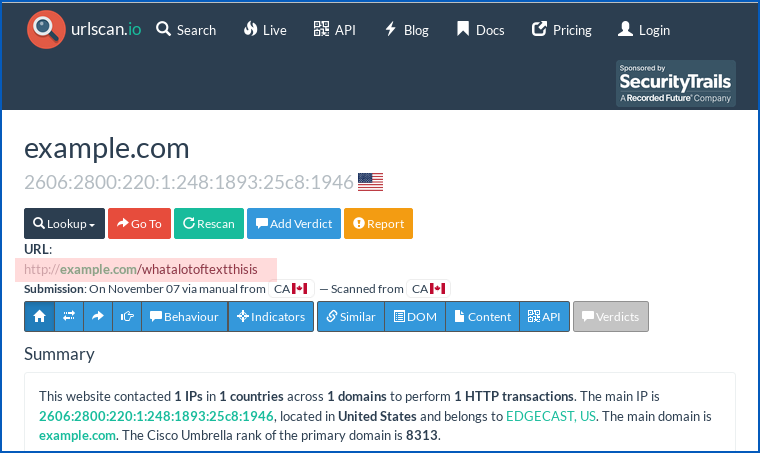
You can probably see where Fabian Bräunlein went with this if you realise that you, or indeed anyone else with the time to keep an eye on things, may be able to retrieve the URL you just looked up.
Here, I went back in with a different browser via a different IP address, and was able to retrieve the recent searches against example.com. including the one with the full URL I submitted above:
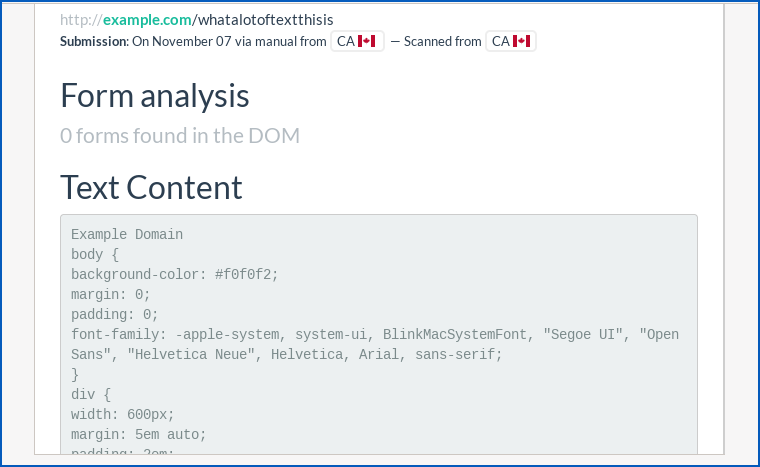
From there, I can drill down into the page content and even access the request headers at the time of the original search:
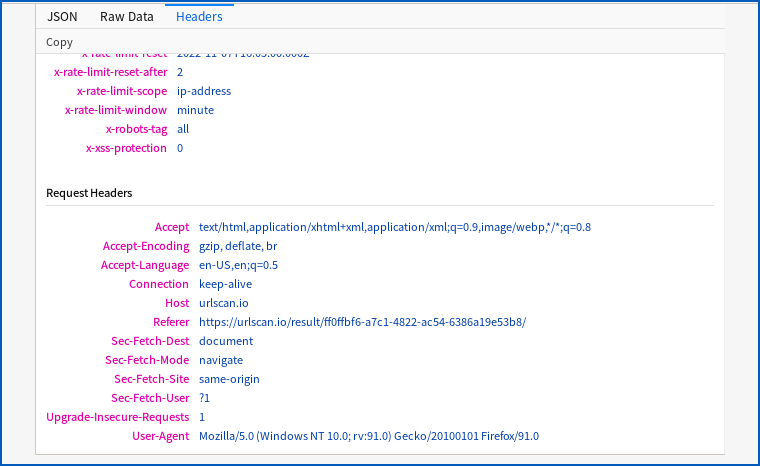
And no matter how hard urlscan.io tries to detect and avoid saving and retrieving private data that happens to be given away in the original search…
…there’s no way that the site can reliably protect you from “searching” for data that you shouldn’t have revealed to a third-party site.
This shouldn’t-really-have-been-revealed data may leak out as a text strings in URLs, perhaps encoded to make them less obvious to casual observers, that denote information such as tracking codes, usernames, “magic codes” for password resets, order numbers, and so on.
Worse still, Bräunlein realised that many third-party security tools, both commerical and open source, perfom automated URL lookups via urlscan.io if so configured.
In other words, you might be making your security situation worse while trying to make it better, by inadvertently authorising your security software to give away personally identifiable information in its online security lookups.
Indeed, Bräunlein documented numerous “sneaky searches” that attackers could potentially use to home in on personal information that could be leeched from the system, including but not limited to (in alphabetical order) data that really ought to kept secret:
- Account creation links
- Amazon gift delivery links
- API keys
- DocuSign signing requests
- Dropbox file transfers
- Package tracking links
- Password reset links
- PayPal invoices
- Shared Google Drive documents
- Sharepoint invites
- Unsubscribe links
What to do?
- Read Bräunlein’s report. It’s detailed but explains not only what you can do to reduce the risk of leaking data this way y mistake, but also what
urlscan.iohas done to make it easier to do searches privately, and to get rogue data expired quickly. - Read
urlscan.io‘s own blog post based on lessons learned from the report. The article is entitled Scan Visibility Best Practices and contains plenty of useful advice summarised as how to: “understand the different scan visibilities, review your own scans for non-public information, review your automated submission workflows, enforce a maximum scan visibility for your account and work with us to clean non-public data fromurlscan.io“. - Review any code of your own that does online security lookups. Be as proactive and as conservative as you can in what you remove or redact from data before you submit it to other people or services for analysis.
- Learn what privacy features exists for online submissions. If there’s a way to identify your submissions as “do not share”, use it unless you are happy for it to be used by the community at large to improve security in general. Use these privacy features as well as, not instead of, redacting the input you submit in the first place.
- Learn how to report rogue data to online service of this sort it you see it. And if you run a service of this sort that publishes data that you later find out (through no fault of your own) wasn’t supposed to be public, make sure you have a robust and quick way to remove it to reduce potential future harm.
Simply put…
To users of online security scanning services: If in doubt/Don’t give it out.
To the operators of those services: If it shouldn’t be in/Stick it straight in the bin.
And to cybersecurity coders everywhere: Never make your users cry/By how you use an API.
A bin, if you aren’t familiar with that pungently useful word, or rubbish bin in full, is what English-speaking people outside North America call a garbage can.
Mahhn
How about requestion VirusTotal to not store that data?
ohh yeah, it’s data hoarder goog, never mind…. that’s likely the only reason they are involved.
To bad we don’t have a government agency that protects consumers. (we aren’t people anymore, we are consumers)
Paul Ducklin
The primary original goal of VT was for sample *sharing*, and suppressing that sharing process was considered a bad idea because otherwise crooks could use VT as an automated way of flagging which products might not yet detect a sample while preventing the vendors of those products from finding that out and being able to investigate. (VT doesn’t share samples with anyone and everyone, for obvious reasons.)
IIRC there is talk of reintroducing a “do not share sample with vendors” option. How that will pan out I can’t tell you. I have seen some well-known researchers suggest it’s a great idea, but I am not so sure, not least if the T&Cs ultimately mean that Google does always gets samples but other vendors don’t.
To be fair to VT, there is an easy-to-find procedure for requesting removal on the grounds of “I have accidentally uploaded something private.”