
In the first part of this series, we took a close look at CVSS and how it works, concluding that while CVSS may offer some benefits, it’s not designed to be used as a sole means of prioritization. In this article, we’ll cover some alternative tools and systems for remediation prioritization, how they can be used, and their pros and cons.
Exploit Prediction Scoring System (EPSS)
EPSS, first published at Black Hat USA 2019, is (like CVSS) maintained by a FIRST Special Interest Group (SIG). As noted in the whitepaper that accompanied the Black Hat talk, the creators of EPSS aim to fill a gap in the CVSS framework: predicting the probability of exploitation based on historic data.
The original version of EPSS used logistic regression: a statistical technique to measure the probability of a binary outcome by considering the contribution several independent variables make to that outcome. For instance, if I wanted to use logistic regression to measure the probability of a yes/no event occurring (say, whether a given person will purchase one of my products), I’d look to collect a large sample of historical marketing data for previous customers and would-be customers. My independent variables would be things like age, gender, salary, disposable income, occupation, locale, whether a person already owned a rival product, and so on. The dependent variable would be whether the person bought the product or not.
The logistic regression model would tell me which of those variables make a significant contribution to that outcome, either positive or negative. So, for example, I might find that age < 30 and salary > $50,000 are positively correlated to the outcome, but already owns similar product = true is, unsurprisingly, negatively correlated. By weighing up the contributions to these variables, we can feed new data into the model and get an idea of the probability of any given person wanting to buy the product. It’s also important to measure the predictive accuracy of logistic regression models (as they may result in false positives or false negatives), which can be achieved with Receiver Operating Characteristic (ROC) curves.
The creators of EPSS analyzed over 25,000 vulnerabilities (2016 – 2018), and extracted 16 independent variables of interest including the affected vendor, whether exploit code existed in the wild (either in Exploit-DB or in exploit frameworks like Metasploit and Canvas), and the number of references in the published CVE entry. These were the independent variables; the dependent variable was whether the vulnerability had actually been exploited in the wild (based on data from Proofpoint, Fortinet, AlienVault, and GreyNoise).
The authors found that the existence of weaponized exploits made the most significant positive contribution to the model, followed by Microsoft being the affected vendor (likely due to the number and popularity of products Microsoft develops and releases, and its history of being targeted by threat actors); the existence of proof-of-concept code; and Adobe being the affected vendor.
Interestingly, the authors also noted some negative correlation, including Google and Apple being the affected vendors. They surmised that this may be due to Google products having many vulnerabilities, of which relatively few were exploited in the wild, and Apple being a closed platform that threat actors haven’t historically targeted. The inherent characteristics of a vulnerability (i.e., the information reflected in a CVSS score) appeared to make little difference to the outcome – although, as one might expect, remote code execution vulnerabilities were more likely to be exploited compared to, say, local memory corruption bugs.
EPSS was originally implemented in a spreadsheet. It provided an estimate of probability that a given vulnerability would be exploited within the next 12 months. Subsequent updates to EPSS adopted a centralized architecture with a more sophisticated machine learning model, expanded the feature set (including variables such as public vulnerability lists, Twitter / X mentions, incorporation into offensive security tools, correlation of exploitation activity to vendor market share and install base, and the age of the vulnerability), and estimated the probability of exploitation within a 30-day window rather than 12 months.
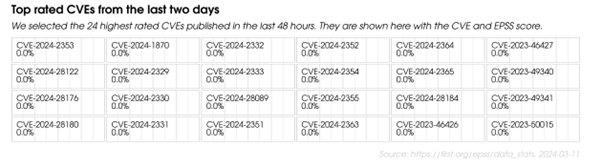
Figure 1: A screenshot from the EPSS Data and Statistics page, showing the top EPSS scores from the last 48 hours at the time the image was captured. Note that EPSS doesn’t conclude that many of these CVEs will end up being exploited
While a simple online calculator is available for v1.0, using the latest version requires either downloading a daily CSV file from the EPSS Data and Statistics page, or using the API. EPSS scores are not shown on the National Vulnerability Database (NVD), which favors CVSS scores, but they are available on other vulnerability databases such as VulnDB.
As noted in our previous article in this series, CVSS scores have not historically been a reliable predictor of exploitation, so EPSS, in principle, seems like a natural complement — it tells you about the probability of exploitation, whereas CVSS tells you something about the impact. As an example, say there’s a bug with a CVSS Base score of 9.8, but an EPSS score of 0.8% (i.e., while severe if it is exploited, the bug is less than 1% likely to be exploited within the next 30 days). On the other hand, another bug might have a much lower CVSS Base score of 6.3, but an EPSS score of 89.9% – in which case, you might want to prioritize it.
What you shouldn’t do (as the EPSS authors point out) is multiply CVSS scores by EPSS scores. Even though this theoretically gives you a severity * threat value, remember that a CVSS score is an ordinal ranking. EPSS, its creators say, communicates different information from that of CVSS, and the two should be considered together but separately.
So is EPSS the perfect companion to CVSS? Possibly – like CVSS, it’s free to use, and offers useful insight, but it does come with some caveats.
What does EPSS actually measure?
EPSS provides a probability score which indicates the likelihood of a given vulnerability being exploited in general. It does not, and is not intended to, measure the likelihood of your organization being targeted specifically, or the impact of successful exploitation, or any incorporation of an exploit into (for instance) a worm or a ransomware gang’s toolkit. The outcome it predicts is binary (exploitation either occurs or it doesn’t – although note that it’s actually more nuanced than that: either exploitation occurs or we don’t know if it has occurred), and so an EPSS score tells you one thing: the probability of exploitation occurring within the next 30 days. On a related note, it’s worth making a note of that time period. EPSS scores should, by design, be recalculated, as they rely on temporal data. A single EPSS score is a snapshot in time, not an immutable metric.
EPSS is a ‘pre-threat’ tool
EPSS is a predictive, proactive system. For any given CVE, assuming the requisite information is available, it will generate a probability that the associated vulnerability will be exploited in the next 30 days. You can then, if you choose to, factor in this probability for prioritization, provided the vulnerability has not already been exploited. That is, the system does not provide any meaningful insight if a vulnerability is being actively exploited, because it’s a predictive measure. To go back to our earlier example of logistic regression, there’s little point running your data through my model and trying to sell you my product if you already bought it six weeks ago. This seems obvious, but it’s still worth bearing in mind: for vulnerabilities which have been exploited, EPSS scores cannot add any value to prioritization decisions.
Lack of transparency
EPSS has a similar issue to CVSS with regard to transparency, although for a different reason. EPSS is a machine learning model, and the underlying code and data is not available to most members of the FIRST SIG, let alone the general public. While the maintainers of EPSS say that “improving transparency is one of our goals,” they also note that they cannot share data because “we have several commercial partners who requested that we not share as part of the data agreement. As far as the model and code, there are many complicated aspects to the infrastructure in place to support EPSS.”
Assumptions and constraints
Jonathan Spring, a researcher at Carnegie Mellon University’s Software Engineering Institute, points out that EPSS relies on some assumptions which make it less universally applicable than it may appear. EPSS’s website claims that the system estimates “the likelihood (probability) that a software vulnerability will be exploited in the wild.” However, there are some generalizations here. For example, “software vulnerability” refers to a published CVE – but some software vendors or bug bounty administrators might not use CVEs for prioritization at all. As Spring notes, this may be because a CVE has yet to be published for a particular issue (i.e., a vendor is coordinating with a researcher on a fix, prior to publication), or because the vulnerability is more of a misconfiguration issue, which wouldn’t receive a CVE in any case.
Likewise, “exploited” means exploitation attempts that EPSS and its partners were able to observe and record, and “in the wild” means the extent of their coverage. The authors of the linked paper also note that, because much of that coverage relies on IDS signatures, there is a bias towards network-based attacks against perimeter devices.
Numerical outputs
As with CVSS, EPSS produces a numerical output. And, as with CVSS, users should be aware that risk is not reducible to a single numerical score. The same applies to any attempt to combine CVSS and EPSS scores. Instead, users should take numerical scores into account while maintaining an awareness of context and the systems’ caveats, which should impact how they interpret those scores. And, as with CVSS, EPSS scores are standalone numbers; there are no recommendations or interpretation guidance provided.
Possible future disadvantages
The authors of EPSS note that attackers may adapt to the system. For instance, a threat actor may incorporate lower-scoring vulnerabilities into their arsenal, knowing that some organizations may be less likely to prioritize those vulnerabilities. Given that EPSS uses machine learning, the authors also point out that attackers may in the future attempt to perform adversarial manipulation of EPSS scores, by manipulating input data (such as social media mentions or GitHub repositories) to cause overscoring of certain vulnerabilities.
Stakeholder-specific Vulnerability Categorization (SSVC)
SSVC, created by Carnegie Mellon University’s Software Engineering Institute (SEI) in collaboration with CISA in 2019, is very dissimilar to CVSS and EPSS in that it does not produce a numerical score as its output at all. Instead, it’s a decision-tree model (in the traditional, logical sense, rather than in a machine learning sense). It aims to fill what its developers see as two major issues with CVSS and EPSS: a) users are not provided with any recommendations or decision points, but are expected to interpret numerical scores themselves; and b) CVSS and EPSS place the vulnerability, rather than the stakeholder, at the center of the equation.
As per the SSVC whitepaper, the framework is intended to enable decisions about prioritization, by following a decision tree along several branches. From a vulnerability management perspective, for example, you start by answering a question about exploitation: whether there’s no activity, a proof-of-concept, or evidence of active exploitation. This leads to decisions about exposure (small, controlled, or open), whether the kill chain is automatable, and ‘value density’ (the resources that a threat actor would obtain after successful exploitation). Finally, there are two questions on safety impact and mission impact. The ‘leaves’ of the tree are four possible decision outcomes: defer, scheduled, out-of-cycle, or immediate.

Figure 2: A sample decision tree from the SSVC demo site
Usefully, the latest version of SSVC also includes several other roles, including patch suppliers, coordinators, and triage/publish roles (for decisions about triaging and publishing new vulnerabilities), and in these cases the questions and decision outcomes are different. For instance, with coordination triage, the possible outcomes are decline, track, and coordinate. The labels and weightings are also designed to be customizable depending on an organization’s priorities and sector.
Having gone through the decision tree, you can export a result to either JSON or PDF. The result also includes a vector string, which will be familiar to anyone who read our analysis of CVSS in the previous article. Notably, this vector string contains a timestamp; some SSVC results are intended to be recalculated, depending on the context. The authors of the SSVC whitepaper recommend recalculating scores which depend on the ‘state of exploitation’ decision point once a day, for example, because this can change rapidly – whereas other decision points, such as technical impact, should be static.
As the name suggests, SSVC attempts to put stakeholders at the center of the decision by emphasizing stakeholder-specific issues and decision-based outcomes, rather than numerical scores. One useful outcome of this is that you can apply the framework to vulnerabilities without a CVE, or to misconfigurations; another is that stakeholders from disparate sectors and industries can adapt the framework to suit their own needs. It’s also fairly simple to use (you can try it out here), once you’ve got a handle on the definitions.
To our knowledge, there hasn’t been any independent empirical research into the effectiveness of SSVC, only a small pilot study conducted by SSVC’s creators. The framework also prefers simplicity over nuance in some respects. CVSS, for example, has a metric for Attack Complexity, but SSVC has no equivalent decision point for ease or frequency of exploitation or anything similar; the decision point is simply whether or not exploitation has occurred and if a proof-of-concept exists.
And, presumably to avoid over-complicating the decision tree, none of the decision points in any of the SSVC trees have an ‘unknown’ option by default; instead, users are advised to make a “reasonable assumption” based on prior events. In certain cases, this may skew the eventual decision, particularly with regards to decision points outside an organization’s control (such as whether a vulnerability is being actively exploited); analysts may be uncomfortable with ‘guessing’ and err on the side of caution.
That being said, it’s perhaps no bad thing that SSVC avoids numerical scores (although some users may see this as a downside), and it has several other factors in its favor: It’s designed to be customizable; is fully open-source; and provides clear recommendations as a final output. As with most of the tools and frameworks we discuss here, a solid approach would be to combine it with others; inputting EPSS and CVSS details (and the KEV Catalog, discussed below), where applicable, into a tailored SSVC decision tree is likely to give you a reasonable indication of which vulnerabilities to prioritize.
Known Exploited Vulnerabilities (KEV) Catalog
The KEV Catalog, operated by the Cybersecurity and Infrastructure Security Agency (CISA), is a continually updated list of which CVEs threat actors are known to have actively exploited. As of December 2024, there are 1238 vulnerabilities on that list, with provided details including CVE-ID, vendor, product, a short description, an action to be taken (and a due date, which we’ll come to shortly), and a notes field, often containing a link to a vendor advisory.
As per CISA’s Binding Operational Directive 22-01, “federal, executive branch, departments and agencies” are required to remediate applicable vulnerabilities in the KEV Catalog, along with some other actions, within a certain timeframe (six months for CVE-IDs assigned before 2021, two weeks for all others). CISA’s justification for creating the KEV Catalog is similar to points we made in our previous article: Only a small minority of vulnerabilities are ever exploited, and attackers do not appear to rely on severity ratings to develop and deploy exploits. Therefore, CISA argues, “known exploited vulnerabilities should be the top priority for remediation…[r]ather than have agencies focus on thousands of vulnerabilities that may never be used in a real-world attack.”
The KEV Catalog is not updated on a scheduled basis, but within 24 hours of CISA becoming aware of a vulnerability that meets certain criteria:
- A CVE-ID exists
- “There is reliable evidence that the vulnerability has been actively exploited in the wild”
- “There is a clear remediation action for the vulnerability”
According to CISA, evidence of active exploitation – whether attempted or successful – comes from open-source research by its own teams, as well as “information directly from security vendors, researchers, and partners…information through US government and international partners…and through third-party subscription services.” Note that scanning activity, or the existence of a proof-of-concept, are not sufficient for a vulnerability to be added to the Catalog.
Full disclosure: Sophos is a member of the JCDC, which is the part of CISA that publishes the KEV Catalog
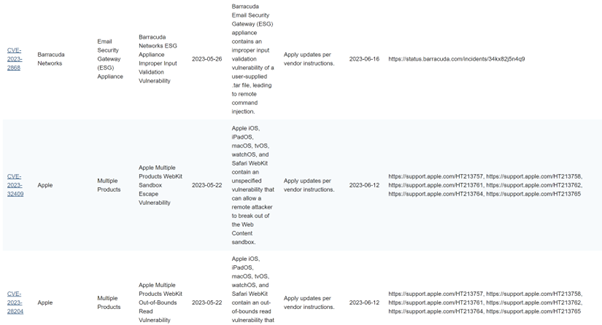
Figure 3: Some of the entries in the KEV Catalog
While primarily aimed at US federal agencies, many private sector organizations have adopted the list for prioritization. It’s not hard to see why; the Catalog provides a simple and manageable collection of active threats, in CSV or JSON formats, which can easily be ingested and, as CISA suggests, incorporated into a vulnerability management program for prioritization. Crucially, CISA is clear that organizations should not rely solely on the Catalog, but take other sources of information into account
Like EPSS, the KEV Catalog is predicated on a binary outcome: if a bug is on the list, it’s been exploited. If it’s not, it hasn’t (or, more accurately, we don’t know if it has or not). But there’s a lot of contextual information KEV doesn’t provide, which could aid organizations with prioritization, particularly in the future as the list continues to grow and become more unwieldy (and it will; there is only one reason a vulnerability would ever be removed from the list, which is if a vendor update causes an “unforeseen issue with greater impact than the vulnerability itself”).
For instance, the Catalog does not detail the volume of exploitation. Has a bug been exploited once, or a handful of times, or thousands of times? It doesn’t provide any information about affected sectors or geographies, which could be useful data points for prioritization. It doesn’t tell you what category of threat actor is exploiting the vulnerability (other than ransomware actors), or when the vulnerability was last exploited. As with our discussion of EPSS, there are also issues around what is considered a vulnerability, and the transparency of data. Regarding the former, a KEV Catalog entry must have a CVE – which may be less useful for some stakeholders – and regarding the latter, its exploitation coverage is limited to what CISA’s partners can observe, and that data is not available for inspection or corroboration. However, a curated list of vulnerabilities which are believed to have been actively exploited is likely useful for many organizations, and provides additional information on which to base decisions about remediation.
You’re perhaps starting to get a sense of how some of these different tools and frameworks can be combined to give a better understanding of risk, and lead to more informed prioritization. CVSS gives an indication of a vulnerability’s severity based on its inherent characteristics; the KEV Catalog tells you which vulnerabilities threat actors have already exploited; EPSS gives you the probability of threat actors exploiting a vulnerability in the future; and SSVC can help you reach a decision about prioritization by taking some of that information into account within a customized, stakeholder-specific decision-tree.
To some extent, CVSS, EPSS, SSVC, and the KEV Catalog are the ‘big hitters.’ Let’s now turn to some lesser-known tools and frameworks, and how they stack up. (For clarity, we’re not going to look at schemes like CWE, CWSS, CWRAF, and so on, because they’re specific to weaknesses rather than vulnerabilities and prioritization.)
Other frameworks and tools
Vendor-specific schemes
Several commercial entities offer paid vulnerability ranking services and tools designed to assist with prioritization; some of these may include EPSS-like prediction data generated by proprietary models, or EPSS scores in conjunction with closed-source data. Others use CVSS, perhaps combining scores with their own scoring systems, threat intelligence, vulnerability intelligence, and/or information about a customer’s assets and infrastructure. While these offerings may provide a more complete picture of risk and a better guide to prioritization compared to, say, CVSS or EPSS alone, they’re not typically publicly available and so aren’t open to evaluation and assessment.
Some product vendors have devised their own systems and make their scores public. Microsoft has two such systems for vulnerabilities in its own products: a Security Update Severity Rating System which, like CVSS, provides a guide to the severity of a vulnerability (Microsoft states that its ratings are based on “the worst theoretical outcome were that vulnerability to be exploited”); and the Microsoft Exploitability Index, which aims to provide an assessment of the likelihood of a vulnerability being exploited. This appears to be based on Microsoft’s analysis of the vulnerability; how difficult it would be to exploit; and past exploitation trends, rather than a statistical model, although not enough information is provided to confirm this.
Red Hat also has a Severity Ratings system, comprising four possible ratings along with a calculated CVSS Base score. Like the Microsoft systems, this only pertains to vulnerabilities in proprietary products, and the means by which the scores are calculated are not transparent.
CVE Trends (RIP) and alternatives
CVE Trends, which at the time of writing is not active due to X’s restrictions on usage of its API, is a crowdsourced dashboard of information scraped from X, Reddit, GitHub, and NVD. It showed the ten most currently discussed vulnerabilities based on that data.
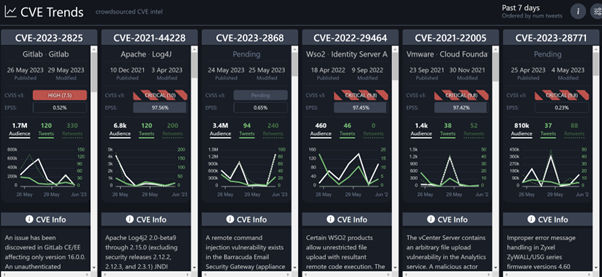
Figure 4: The CVE Trends dashboard
As shown in the screenshot above, the dashboard included CVSS and EPSS scores, CVE information, and sample tweets and Reddit posts, as well as ‘published’ dates and a measurement of discussion activity in the last few days (or 24 hours).
While CVE Trends could be useful for getting an idea of the current ‘flavor of the month’ CVEs among the security community – and could also be helpful in obtaining breaking news about new vulnerabilities – it didn’t aid in prioritization above and beyond new, high-impact bugs. It only showed ten vulnerabilities at a time, and some of those – including Log4j, as you can see in the screenshot – were relatively old, though still being discussed because of their prevalence and notoriety.
As noted above, CVE Trends is currently inactive, and has been since mid-2023. As of this writing, visitors to the site receive the following message, which also appeared as the final message on its creator’s Twitter feed:
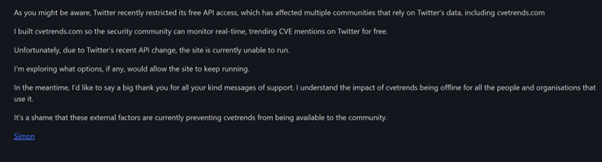
Figure 5: CVE Trends’ farewell message / tweet
It remains to be seen whether X will relax its API usage restrictions, or if the creator of CVE Trends, Simon J. Bell, will be in a position to explore other options to restore the site’s functionality.
After the demise of Bell’s site, a company called Intruder developed their own version of this tool, in beta as of this writing, which is also called ‘CVE Trends.’ It comes complete with a 0-100 temperature-style ‘Hype score’ based on social media activity.
SOCRadar also maintains a similar service, called ‘CVE Radar,’ which includes details of the number of tweets, news reports, and vulnerability-related repositories in its dashboard; in a touching gesture, it acknowledges Simon Bell’s CVE Trends work on its main page (as Intruder does on its About page). Both CVE Radar and Intruder’s version of CVE Trends usefully incorporate the texts of related tweets, providing an at-a-glance digest of the social media discussion about a given bug. Whether the developers of either tool intend to incorporate other social media platforms, given the exodus from X, is unknown.
CVEMap
Introduced in mid-2024, CVEMap is a relatively new command-line interface tool by ProjectDiscovery that aims to consolidate several aspects of the CVE ecosystem – including CVSS score, EPSS score, the age of the vulnerability, KEV Catalog entries, proof-of-concept data, and more. CVEMap doesn’t offer or facilitate any new information or scores, as it’s solely an aggregation tool. However, the fact that it combines various sources of vulnerability information into a simple interface – while also allowing filtering by product, vendor, and so on – may make it useful for defenders seeking a means to make informed prioritization decisions based on multiple information sources.
Bug Alert
Bug Alert is a service designed to fill a specific gap for responders: It aims to alert users solely to critical, high-impact vulnerabilities (the ones that always seem to hit on a Friday afternoon or just before a public holiday) as quickly as possible via email, SMS, or phone notifications, without having to wait for security bulletins or CVE publication. It’s intended to be a community-driven effort, and relies on researchers submitting notices of new vulnerabilities as pull requests to the GitHub repository. It’s not clear if Bug Alert’s author is still maintaining it; at the time of writing, the last activity on the Github repository was in October 2023.
As with CVE Trends, while Bug Alert may fill a useful niche, it’s not designed to be used for prioritization in general.
vPrioritizer
vPrioritizer is an open-source framework designed to allow users to assess and understand contextualized risk on a per-asset or per-vulnerability basis, thereby merging asset management with prioritization. This is achieved by using CVSS scores together with “community analytics” and results from vulnerability scanners. Sadly, despite being mentioned in the SSVC whitepaper in 2019 and presented at the Black Hat USA Arsenal in 2020, it is not clear if vPrioritizer’s developer still maintains the project; as of this writing, the last commit to the GitHub repository was in October 2020.
Vulntology
Vulntology is a NIST-led effort to characterize vulnerabilities (the name is a portmanteau of ‘vulnerability’ and ‘ontology’) according to how they can be exploited, the potential impact of exploitation, and mitigating factors. Its stated goals include the standardization of description of vulnerabilities (for example, in vendor advisories and security bulletins); improving the level of detail in such descriptions; and enabling easier sharing of vulnerability information across language barriers. An example of a ‘vulntological representation’ is available here.
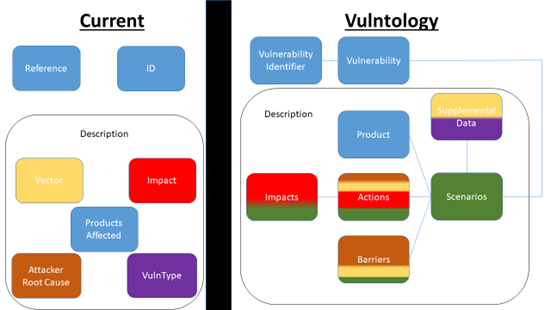
Figure 6: An illustration of Vulntology’s proposed work, taken from the project’s GitHub repository
Vulntology is therefore not a scoring framework, or even a decision tree. Instead, it’s a small step towards a common language, and one which may, if it becomes widely-adopted, be of significant value when it comes to vulnerability management. A standardized approach to describing vulnerabilities would certainly be of use when evaluating multiple vendor security advisories, vulnerability intelligence feeds, and other sources. We mention it here because it does have some implications for vulnerability prioritization, albeit in the long-term, and it is attempting to solve a problem within the vulnerability management field. The last commit to the project’s Github appears to have occurred in spring 2023.
Criminal marketplace data
Finally, a quick word on criminal marketplace data and how future research might utilize it for prioritization. Back in 2014, researchers from the University of Trento conducted a study on whether CVSS scores are a good predictor for exploitation. They concluded that CVSS scores don’t match the rates of exploitation, but they did conclude that remediation “in response to exploit presence in black markets yields the largest risk reduction.” It would be an interesting avenue of research to see if the same is still true today; exploit markets have increased in size since 2014, and there is a large underground economy dedicated to the marketing and selling of exploits.
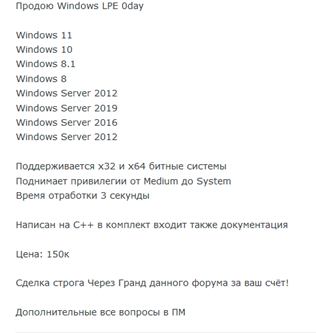
Figure 7: A user offers a Windows local privilege escalation exploit for sale on a criminal forum
Looking not only at the existence of exploits in criminal marketplaces, but also at prices, levels of interest, and customer feedback, could be further useful data points in informing prioritization efforts.
The challenge, of course, is the difficulty of accessing those marketplaces and scraping data; many are closed to registration and only accessible via referral, payment, or reputation. And while the underground economy has increased in size, it’s also arguably less centralized than it once was. Prominent forums may serve as an initial place to advertise wares, but many of the salient details – including prices – are sometimes only available to interested potential buyers via private messages, and the actual negotiations and sales often occur in out-of-band channels like Jabber, Tox, and Telegram. Further research on this issue is needed to determine if it could be a feasible source of data for prioritization.
Combination and customization are key
Having examined CVSS, EPSS, SSVC, and the KEV Catalog in depth – and some other tools and frameworks more briefly – you won’t be surprised to learn that we didn’t find a magic solution, or even a magic combination of solutions, that will solve all prioritization problems. However, a combination is almost always better than using a single framework. More data points mean a more informed view, and while this might require some technical effort up front, the outputs of most of the tools and frameworks we’ve discussed are designed to be easily ingested in an automated manner (and tools like CVEMap have done some of the heavy lifting already).
As well as combining outputs, customization is also really important. This is often overlooked, but prioritization isn’t just about the vulnerabilities, or even the exploits. Of course, they’re a big part of the issue, but the key point is that a vulnerability, from a remediation perspective, doesn’t exist in isolation; considering its inherent properties may be helpful in some circumstances, but the only truly significant data point is how that vulnerability could impact you.
Moreover, every organization treats prioritization differently, depending on what it does, how it works, what its budget and resources look like, and what its appetite is for risk.
Single, one-size-fits-all scores and recommendations don’t often make much logical sense from the perspective of assessing frameworks, but they make even less sense from the perspective of individual organizations trying to prioritize remediation. Context is everything. So whatever tools or frameworks you use, put your organization – not a score or a ranking – at the center of the equation. You may even want to do this at a more granular level, depending on the size and structure of your organization: prioritizing and contextualizing per division, or department. In any case, customize as much as you can, and remember that however prominent and popular a framework may be, its outputs are only a guide.
With some systems, like CVSS or SSVC, there are built-in options to customize and tailor outputs. With others, like EPSS and the KEV Catalog, customization isn’t really the point, but you can still add context to those results yourself, perhaps by feeding that information into other tools and frameworks and looking at the entire picture as much as possible.
Prioritization also goes beyond the tools we discuss here, of course. We’ve focused on them in this series because they’re an interesting component of vulnerability management, but the information that should feed into prioritization decisions will ideally come from a variety of other sources: threat intelligence, weaknesses, security posture, controls, risk assessments, results from pentests and security audits, and so on.
To reiterate a point from our first article, while we’ve pointed out some of the downsides to these tools and frameworks, we don’t intend in in any way to denigrate their developers or their efforts, and we’ve tried to be fair and even-handed in our assessments. Creating frameworks like these is a lot of hard work and requires considerable thought and planning – and they’re there to be used, so you should use them when and where it makes sense to do so. We hope that this series will allow you to do this in a safe, informed, and effective manner.