



Keeping malware detections up to date is a never-ending journey and one that is made harder for defenders since the latest-and-greatest malware is rarely completely “new.” Instead, it is more likely to be a combination of “something old, something borrowed, and something new.” Take document malware for example, it spent years in dormancy then resurfaced in 2014 when Dridex used documents to deploy its payload, and it still remains on the SophosLabs team’s “Most Wanted” list, as referenced in Sophos’ 2021 Threat Report.
Artificial intelligence (AI) is capable of learning patterns from millions of malware samples within a matter of days, allowing it to detect both samples it has seen during training and samples it has not. Over time, however, the threat landscape evolves in such a way that samples in the wild will deviate from those patterns, requiring it to be updated. Training models on both old and new samples provides the best detection, but it is both time-consuming and computationally expensive. The tempting short-cut is to train the model on only new samples, but just like in real life, AI rarely gives us a “free lunch.” Retraining old models on new samples alone will cause them to update in such a way that they will “forget” older samples. This issue is such a headache that there is even a name for it: “catastrophic forgetting.”
Currently, the only solution to catastrophic forgetting is to retrain the entire neural network, which takes about one week, and requires all new and old samples. In the fast-moving world of cyberattacks, this is too much “down time.” Ideally, updates to learn new malware – without losing the old – should take about one hour.
Below is an overview, based Hillary Sanders’ deep-dive technical articles Catastrophic Forgetting, Part 1, and Catastrophic Forgetting, Part 2, of how SophosAI is solving the detection degradation and downtime problems for defenders.
Analysis of Different Approaches to Catastrophic Forgetting
AI provides security vendors a better chance of keeping up with the “something new” but must be updated constantly to avoid a significant performance dip when new malware changes the threat landscape (as shown in Figure 1).
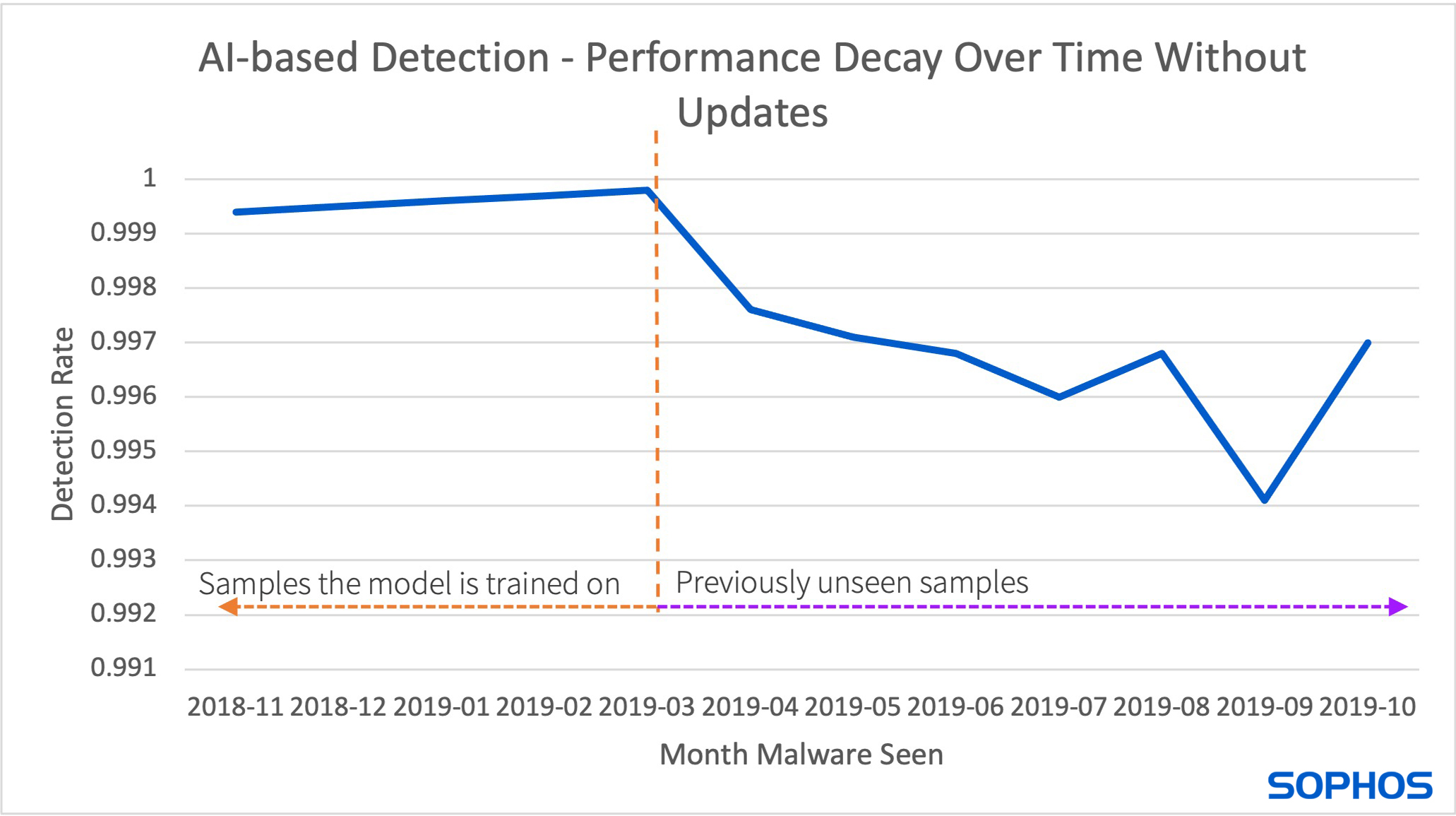

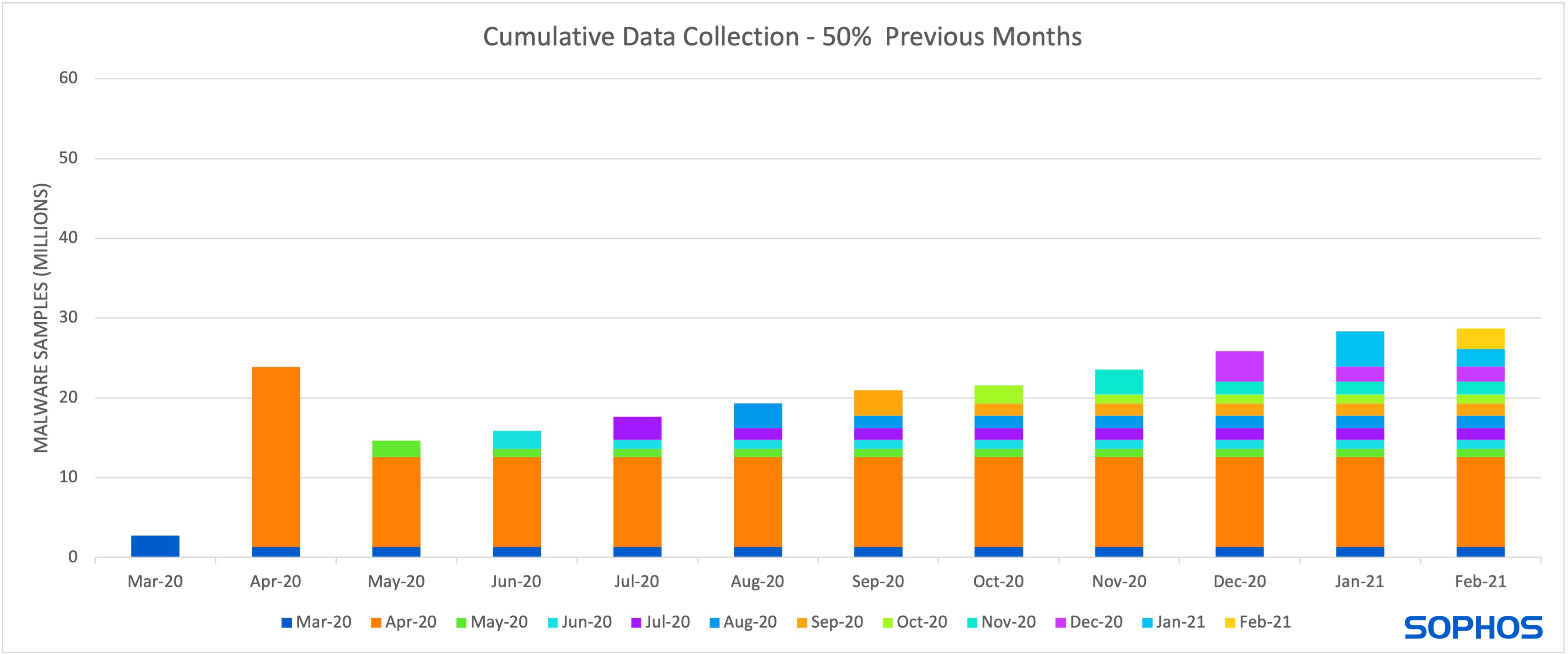
Updating models requires collecting new samples, which increases the cost of both data storage and computation hours for model training (as shown in figure 2).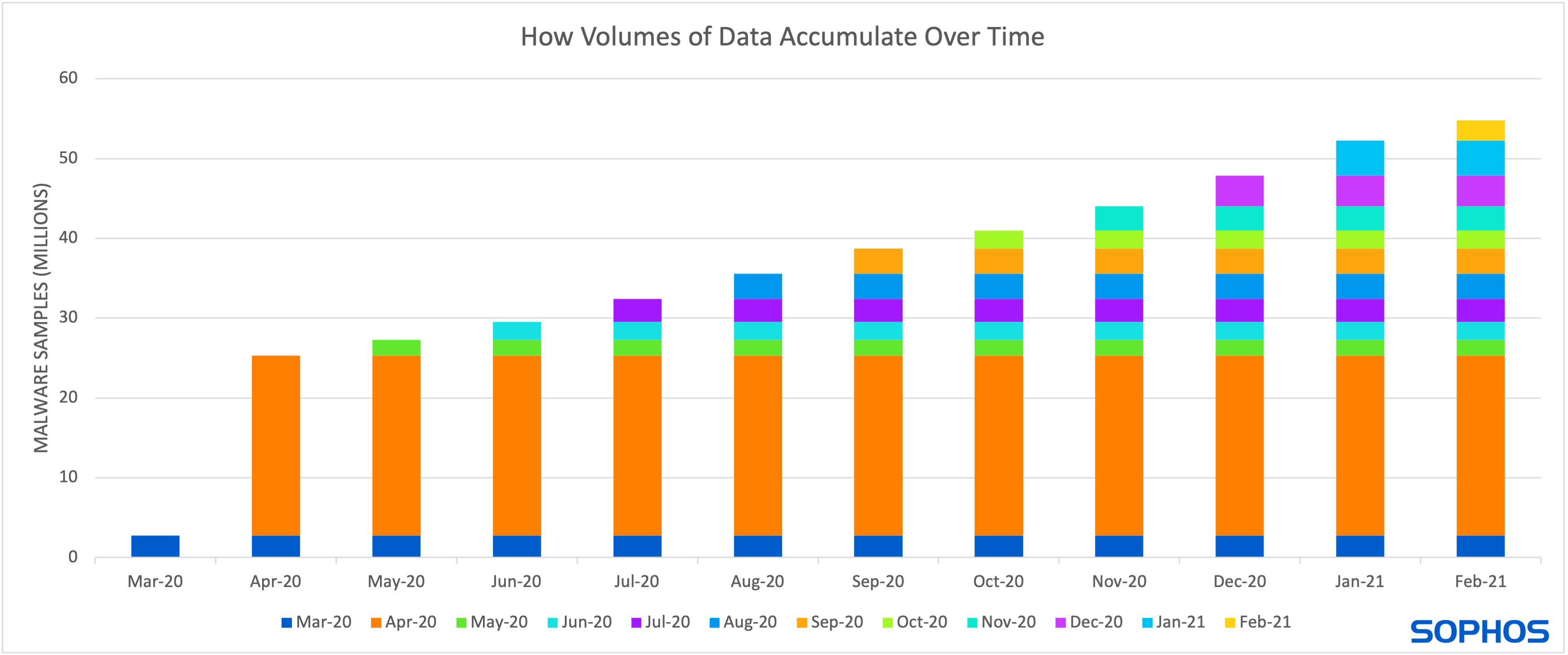
Figure 2. This figure shows the increase in data storage if vendors collect 25% of malware released each month, starting in March, in order to train a model from scratch. The number of samples released per month are provided by AVTest.
To reduce these costs and speed up model turn-around, it is common to fine-tune a model rather than to train a new model from scratch (as shown in figure 3). This means that the existing model is trained for additional steps on only new samples. During each step, the model updates its understanding, making it possible for the model to update itself in such a way that it “forgets” the old patterns. This is what researchers call catastrophic forgetting.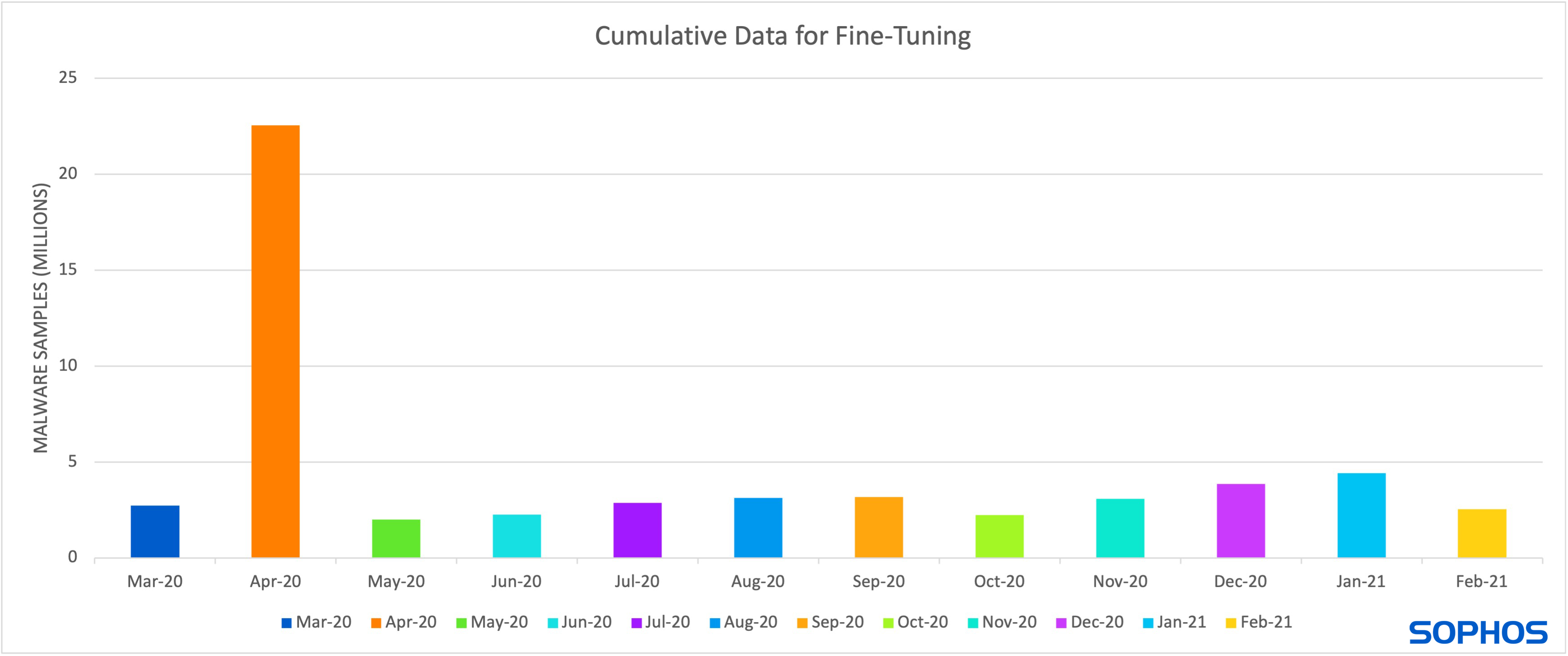
How SophosAI Solves Catastrophic Forgetting
Researcher Hillary Sanders evaluated model performance on three potential solutions to catastrophic forgetting: (1) Data rehearsal, or altering the data exposed to the model, (2) adjusting the rate of learning (3) and modifying feedback given to the model after each training step.
Data Rehearsal
Data rehearsal mixes a selection of old samples with new ones when fine-tuning the model. This approach “reminds” the model of old information needed to detect older samples while at the same time learning to detect newer ones. The drawback is it requires maintenance and access to at least some older data, which will increase storage costs over time, although it is still a noticeable improvement over storing all past data.
The percentage of older samples maintained can vary based on the desired performance. Sanders experimented with different variations in the proportion of new samples to old when fine-tuning a model. She found a trade-off between (1) performance on unknown samples, and (2) performance on old samples. When the percentage of new samples was greater than old samples, the model performed better on unknown samples but worse on older samples, and vice versa.
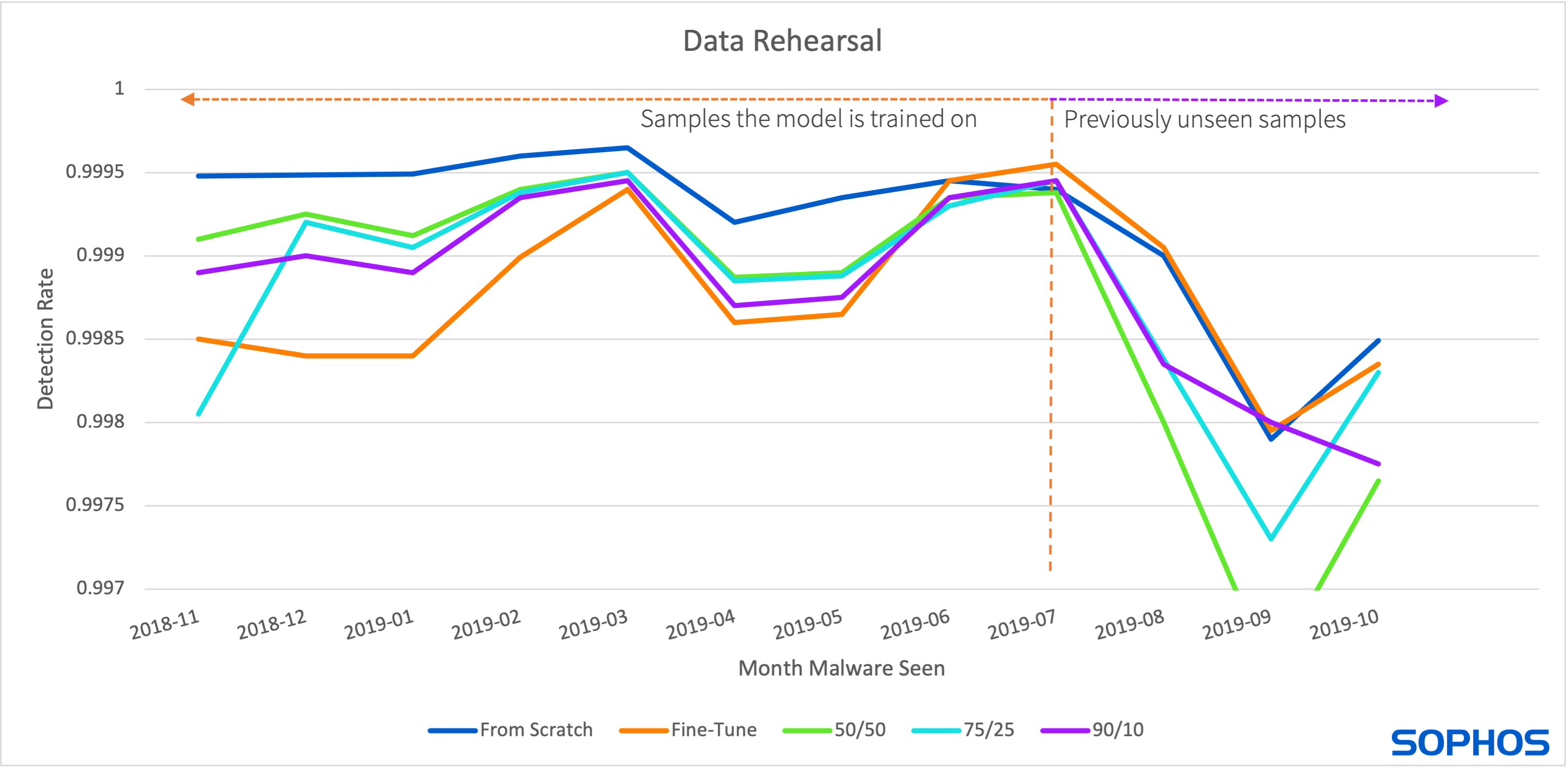
Figure 4. The above figure shows the results of data-rehearsal compared to fine-tuning (green) and training from scratch (blue). The gray line uses 50% of newer samples and 50% of older samples and performs well on older months (left of the dotted line) and worst on newer months (right of the dotted line). The yellow line uses 75% of newer samples and 25% of older samples, while orange uses 90% of newer samples and 10% of older samples. Both perform better than the 50/50 approach on newer samples.
Learning Rate
The second approach modifies how quickly the model learns by adjusting the learning rate – the amount that a model can change after seeing any given sample. Too high a learning rate, and the model will only “remember” the most recent samples that it has seen; too small a learning rate and it takes too long to learn anything at all. But, by limiting the learning rate, the model does not change drastically from its original form, allowing some remembering of previously learned patterns from older data. However, this also limits the learning of new patterns, hurting detection rates on new malware.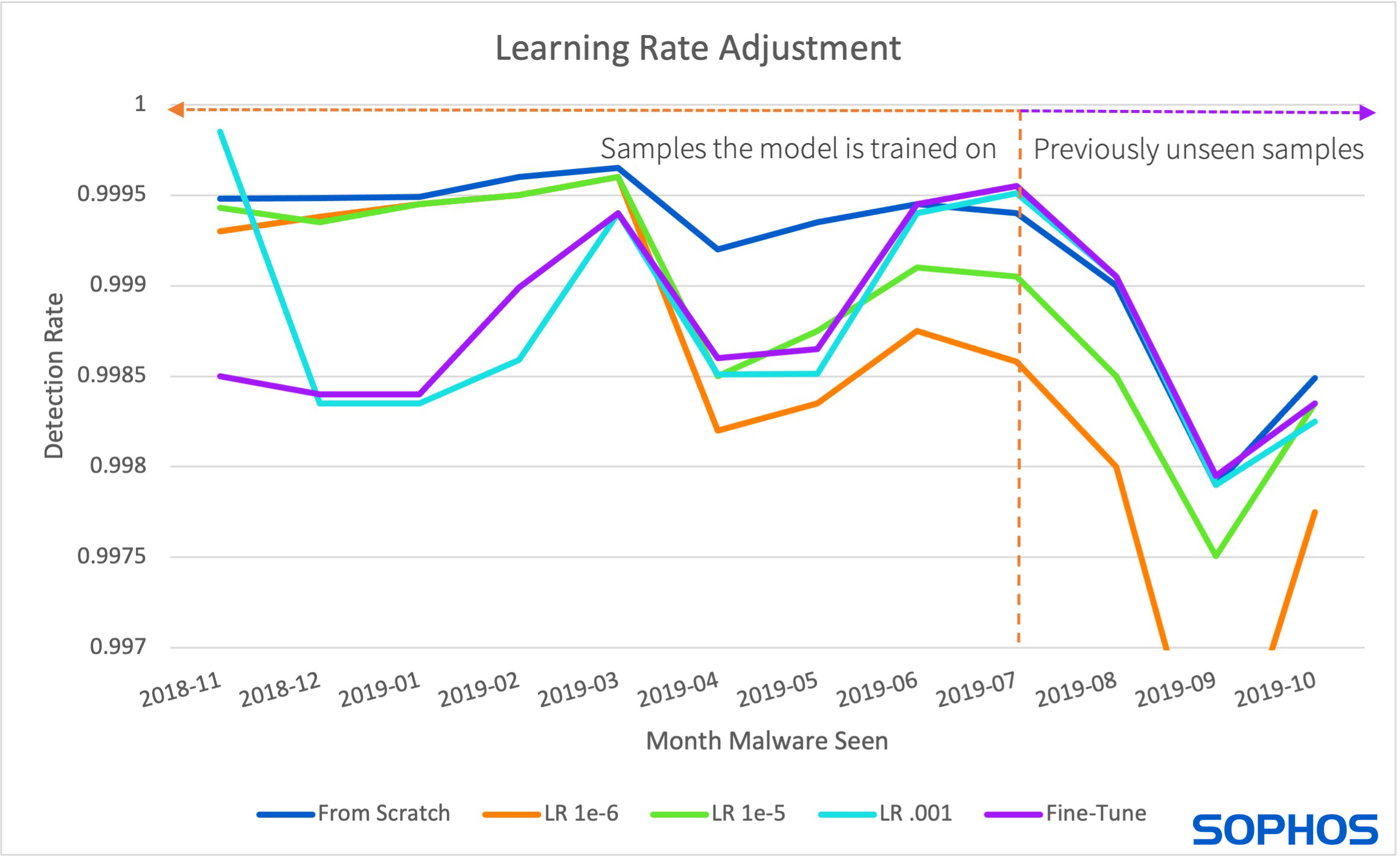
Figure 5. The above figure shows how altering the learning rate impacts model performance. The two smallest learning rates perform well on older malware (left of the dotted line), but perform relatively worse on newer malware (right of the dotted line). The higher learning rate performs relatively worse on older malware, but better than the smaller learning rates on newer malware.
Elastic Weight Consolidation
Work by Google’s DeepMind in 2017 addresses catastrophic forgetting in an academic setting and inspired the final approach. At high level, the old model is used to keep a new model grounded. If the new model starts to “forget,” the old model acts as a spring and pulls it right back. This approach is termed “elastic-weight consolidation.” Because “real-world” models tend to be larger and trained on monumentally more data, SophosAI altered the original formulation to better “pull” the new model back when it starts forgetting. This approach reduces data storage costs because it only requires new samples.

Figure 6. The above figure compares the three approaches. Fine-tuning (green), Elastic Weight Consolidation (EWC) (purple) and a higher learning rate (orange) performed the worst on older malware samples (left of the dotted line) but performed relatively well on newer samples (right of the dotted line). Data rehearsal (yellow) and data rehearsal combined with EWC (gray) performed best on old samples compared to the other approaches.
Findings
When comparing all three approaches, it is important to consider the trade-offs between (1) performance, (2) computation costs, and (3) data maintenance costs. Elastic weight consolidation and changing the learning rate do not require older samples, but they are not the highest performers either. Meanwhile, data-rehearsal has stronger comparative performance to a model trained from scratch on both old and new data. It also reduces the overall cost of computation and data storage. Sanders’ evaluation concluded that data rehearsal was the most effective for Sophos in terms of detection rate and cost.
For an in-depth explanation of catastrophic forgetting, read Hillary Sanders’ blog posts, Catastrophic Forgetting, Part 1, and Catastrophic Forgetting, Part 2.
To learn more about SophosAI, follow the team at SophosAI and via the SophosAI blog.