
We recently wrote up a fascinatingly scary warning about server hard drives that might abruptly and utterly fail.
HPE warned its customers that a wide variety of its solid state disks (SSDs) needed an urgent firmware update to prevent them sailing over the edge of the earth into oblivion.
The disks weren’t badly manufactured; they weren’t going to fail for reasons of physics, electronics or electromagentism; and the disk circuitry would remain intact afterwards.
In fact, as far as we can tell, the data actually stored in the chips on the failed devices would still be there…
…you just wouldn’t be able to access it.
The failure was, in fact, down to a bug in the firmware of the drive. (Firmware is a fancy name for software that’s permanently stored in hardware so that the hardware can boot up by itself.)
Simply put, after approximately 32,000 hours of operation – a little under four years – the device firmware would crash, and refuse to initialise again.
Not only would the crashed firmware prevent the drive starting up, it seems that the bug would also prevent the firmware from accepting an update to fix the bug.
Catch-22.
But why a sudden failure at ‘about 32,000 hours’?
To answer that question properly, and to avoid this sort of bug in future, we need to investigate how computers count.
Let’s start by looking at how we ourselves count, or, more precisely, how we account, for time.
In the West, we generally keep track of years using the Christian era, which is currently at AD 2019.
To represent the year exactly, therefore, you need at least four digits.
It’s fine to use more than four digits – after all, 02019 and 002019 both work out to be 2019 because those left-most zeros don’t contribute to the magnitude of the number.
But you have to be careful if you have fewer than four digits at your disposal, because you can no longer be precise about the year – all you can do is come up with some sort of approximation.
As it happens, we do that sort of thing rather often, using two digits to denote a specific year, and sometimes we get away with it.
When we talk about the ‘Swinging 60s’, for example, we’re probably safe to assume that the listener knows we mean the 1960s, rather than the 960s or the 1860s, or even the 2060s, which are still 40 years away.
But sometimes we risk ambiguity when we aren’t precise about the year.
If you were to mention ‘The 20s’, it might not be clear at all whether you were referring to the tumultuous decade right after the First World War, or to the who-knows-how-tumultuous-it-will-be decade that will start in just a few weeks time.

The ‘millennium bug’, often ironically squeezed into the acronym Y2K, short for ‘Year 2000 bug’, was an example of this sort of problem.
The Y2K problem arose because of the once-widespread programming practice of using just two characters for the year, instead of four, in order to to save storage space.
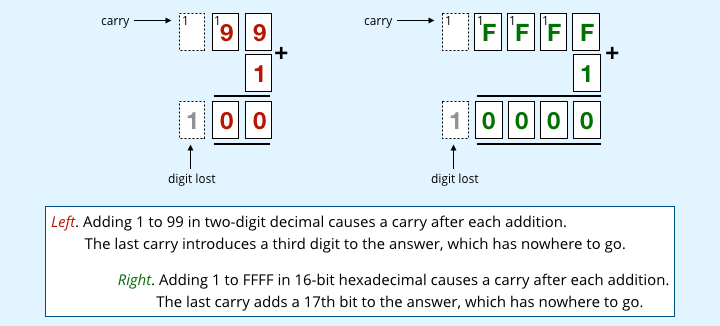
For programs using two-digit years, 99 unambiguously meant AD 1999, but 99+1 didn’t unambiguously advance you to AD 2000.
That’s because 99+1 = 100, which has three digits, and therefore can’t be squeezed back into two characters.
The number overflows its storage space, so the extra ‘carry one’ digit at the left hand end gets lost, along with 100 years.
In a two-digit-year system, 99+1 actually turns back into 00, so that adding one year to AD 1999 loops you back to AD 1900, shooting you 99 years into the past instead of one year into the future.
Some software ‘solved’ this by taking, say, 50-99 to mean AD 1950 to AD 1999, and 00-49 to mean AD 2000 to 2049, but that didn’t fix the overflow problem – it merely shifted the problem year along the number line from 1999 to 2049. In fact, even with four-digit years we’ll face a similar problem again in AD 9999, because 9999+1 needs five digits, but we shall disregard the Y10K problem for now.
A latter-day Y2K bug
As far as we can tell, a very similar sort of numeric overflow – a latter-day Y2K bug, if you like – was what caused the HPE storage device flaw.
We’re making this assumption because the HPE security notification said that the failure happened when the total count of power-on hours for the device reached exactly 32,768.
Programmers will recognise that number at once, because it’s a power of two – in fact, it’s fifteen 2s multiplied together, or 215.
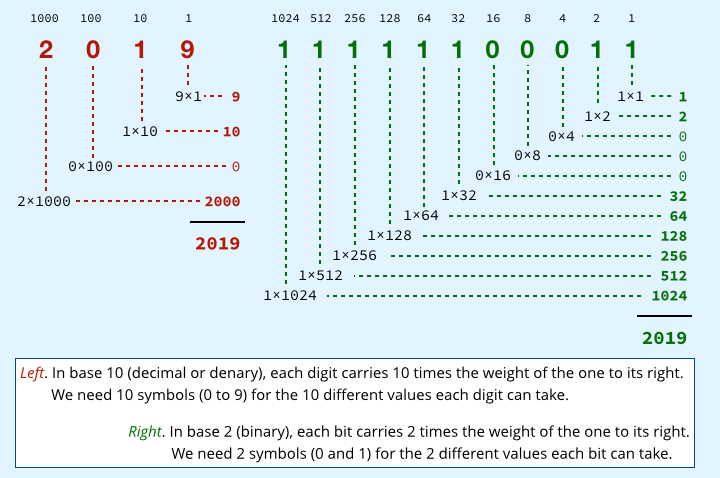
In regular life, however, we usually count in tens, using what’s called base 10.
It’s called base 10 because each digit can have ten different values, needing 10 different symbols, written (in the West, at least) as 0,1,2,3,4,5,6,7,8,9.
And each digit position carries 10 times more numeric weight as we move from right to left in the number.
Thus the number 2019 decomposes as 2×1000 + 0×100 + 1×10 + 9×1.
Curiously, the notation we know as Arabic numerals in the West came to us from India via the Arabic world, where they were known as Indian numerals. They’re written left-to-right because that’s how the Indian mathematicians did it, and that’s the practice the Arabian mathematicians adopted. Indeed, written Arabic uses left-to-right numbers to this day, even though Arabic text runs from right to left.
But computers almost always use base 2, also known as binary, because a counting system with just two states for each ‘digit’ is much easier to implement in electronic circuitry than a system with 10 different states.
These two-state values, denoted with the symbols 0 and 1, are known simply as ‘bits’, short for ‘binary digits’.
Additionally, almost all modern computers are designed to perform their basic operations, including arithmetical calculations, on 8 bits at a time (a memory quantity usually referred to as a byte or an octet), or on some doubling of 8 bits.
Modern Intel processors, for example, can perform calculations on 8, 16, 32 or 64 bits at a time.
So, in programming languages such as C, you can choose between various different sizes, or precisions, of integer values when you want to work with numbers.
This allows you to trade off precision (how many different values each number can represent) with memory usage (the number of bytes needed to store each number, even if it’s zero).
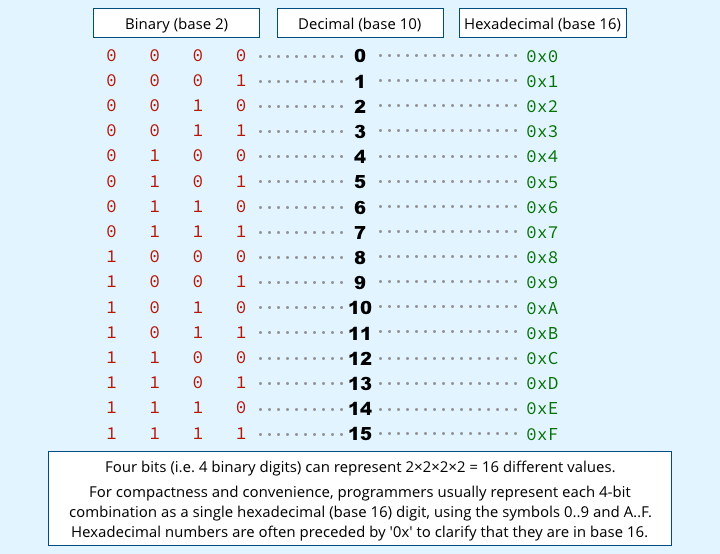
A 16-bit number, which uses two bytes, can range from 0000 0000 0000 0000 in binary form (or the more compact equivalent of 0x0000 in hexadecimal notation), all the way to 1111 1111 1111 1111 (or 0xFFFF – see table above).
The 16-bit number 0xFFFF is a bit like the decimal number 99 in the millennium bug – when all your digit positions are already maxed out, adding one to the number causes a ‘carry one’ to happen at every stage of the addition, including at the left-hand end, producing a result of 0x10000 (65,536 in decimal).
The number 0x10000 takes up 17 bits, not 16, so the left-hand ‘1’ is lost because there’s nowhere to store it.
In other words, just like the decimal sum 99+1 wraps back to zero in the Y2K bug, the binary sum 0xFFFF+1 wraps back to zero in 16-bit arithmetic, so your ‘millennium bug’ overflow moment comes immediately after the number 65,535.
Half of 65,536 = 32,768
At this point, you’ve probably spotted that HPE’s danger value of 32,768 (215) is exactly half of 65,536 (216).
Computers don’t usually do 15-bit arithmetic, but most processors let you choose between working with unsigned and signed 16-bit values.
In the former case, the range you can represent with 65,536 different values is used to denote 0 to 65,535 (0 to 216-1); in the latter, you get -32,768 to 32,767 (-215 to 215-1).
So, if you’re using signed 16-bit numbers, rather than unsigned numbers, then your ‘millennium bug’ overflow point comes when you add 1 to 32,767 instead of when you add 1 to 65,535.
When you try to calculate 32,767+1, you wrap around from the end of the range back to the lowest number in the range, which for signed numbers is -32,768.
Not only do you jump backwards by a total distance of 65,535 instead of going forwards by 1, you end up flipping the sign of the number from positive to negative as well.
It’s therefore a good guess that HPE’s firmware bug was caused by a programmer using a signed 16-bit memory storage size (in C jargon, signed short int) – perhaps trying to be parsimonious with memory – under the misguided assumption that 16 bits would ‘be big enough’.
Getting away with it
If the code were counting the power-on time of the device in days, rather than hours, the programmer would almost certainly have got away with it, because 32,767 days is nearly 90 years.
Today’s SSDs will almost certainly have failed by then of their own accord, or be long retired on account of being too small, so the firmware would never be active long enough to trigger the bug.
On the other hand, if the code were counting in minutes or seconds, then the programmer would almost certainly have spotted the fault during testing (32,767 minutes is a little over three weeks, and 32,767 seconds is only 9 hours).
Sadly, counting in hours using a signed 16-bit number – assuming no one questioned your choice during a code review – might easily get you through initial testing and the prototype stage, and out into production…
…leaving your customers to encounter the overflow problem in real life instead.
We’re guessing that’s how the bug happened.
Exactly when each customer would run out of hours would depend on how long each device sat on the shelf unused before it was purchased, and how much each server was turned on.
That would make the cause of at least the first few failures hard to pin down.
Why a catastrophic failure?
What still isn’t obvious is how a simple numeric overflow like this could cause such catastrophic failure.
After all, even if the programmer had used a 32-bit signed integer, which would last for 231-1 hours (an astonishing quarter of a million years), they wouldn’t – or shouldn’t – have written their code to fail abruptly, permanently and without notice if the hour count went haywire.
Sure, it would be confusing to see a storage device suddenly having a Back to the Future moment and reporting that it’s been turned on for a negative number of hours…
…but it’s not obvious why a counting error of that sort would not only stop the drive working, but also prevent it being reflashed with new firmware to fix the counting error.
Surely software just doesn’t fail like that?
Unfortunately, it can, and it does – when your counting goes awry inside your software, even a single out-of-range number can have a devastating outcome if you don’t take the trouble to detect and deal with weird and unexpected values.
We can’t give a definitive answer about what went wrong in the HPE case without seeing the offending source code, but we can usefully speculate.
If a negative number of power-on hours is never supposed to happen – and it shouldn’t, because time can’t run backwards – then the code may never have been tested to see how it behaves when an ‘impossible’ value comes along.
Or the code might use an ‘impossible’ value, such as a negative timestamp, as some sort of error flag that causes the program to terminate when something bad happens.
If so, then reaching 32,768 hours of trouble-free usage would accidentally trigger an error that hadn’t happened – an error that would continue forever once the counter overflowed backwards.
Or the code might have used the count of hours as an index into a memory array to decide what sort of status message to use.
If the programmer mistakenly treated the 16-bit number as if it were unsigned, then they could divide the number of hours by, say, 4096 and assume that the only possible answers, rounded down to the nearest integer, would be 0,1,2,3…15. (65,535/4096 = 15 remainder 4095.)
That number might be used as an index into a table to retrieve one of 16 different messages, and because it’s impossible to get a number outside the range 0..15 when dividing an unsigned integer by 16, the programmer wouldn’t need to check whether the result was out of range.
But if the number were in fact treated as a signed integer, then as soon as the count overflowed from 32,767 to -32,768, the value of the count divided by 16 would swing from +7 to -8. (32,767/4096 = 7 remainder 4095, while -32,768/4096 = -8 exactly.)
What the programmer assumed would be a safe memory index would suddenly read from the wrong part of memory – what’s known as a buffer overflow (or, in this case, a buffer underflow).
What to do?
The bottom line here is that even trivial-sounding faults in arithmetical calculations can have ruinous consequences on software, causing it to crash or hang unrecoverably.
- Never assume that you will always have enough precision. Always check for overflows, even if you’re convinced they are impossible. Your software may last a lot longer than you think, or be fed with erroneous data due to a bug somewhere else.
- When creating device firmware, build in a fail-safe that allows a secure reset, even if the current firmware turns out to have a bug that stops it booting at all.
- Test even the most unlikely situations in your code. Writing test suites is hard, because you often need to provoke situations that would otherwise never happen in the time available for testing, such as asking “What if the hard disk runs for 10 years? 100 years? 10,000 years?”
- Never approve code until it has been reviewed by someone else who is at least as experienced as the programmer who wrote it in it the first place. You are unlikely to pick up your own errors once you’re convinced your code is correct – it’s hard to be truly objective about something you’re already close to.
- Consider a continuous development process where you retest your code after (almost) every change. Don’t allow code changes to accumulate and then try to test everything in one big pre-release test.
Oh, and if you have any HPE storage devices, check if they’re on HPE’s list of affected products and get the firmware update right now – it’ll be too late to patch after the event!
Bacchanalia
That is seriously incompetent design! The Y2K issue was at least excusable in that available memory was scarce and expensive in the 70s and 80s, and Y2K was a long way off. (I was writing TI Assembler for embedded and inaccessible firmware, and if I wanted to put more code in I had to reduce it somewhere else, we were worrying about a few bytes). But there is no excuse for anything post Y2K, having had the hassle of the Y2K resolution, and memory addresses are cheap readily available
kls
Well written; clearly explained. Hope programmers (and non-programmers) read it all the way through!
BaliRob
This article is unbelievable in its simplification of a subject that sends 99.9% of humanity into oblivion (mentally) – I only wish that my Calculus teacher had had the writer’s clarity of explanation. Love the Indian connection because, not Pythagoras, was the birth of Maths which DID take place in India (quodos so generous as I am an English scholar hahaha) – thank you so much for taking my mind off other problems this day.
Hans
Absolutely spectacular article, thanks.