
Criminals continue to leverage the features of Adobe’s PDF document format to engage in malware and phishing attacks, with no sign of a slowdown. Last year at Black Hat USA, I gave a presentation about PDF-based malware detection using machine learning. We discovered that the best AV engine could only catch fewer than 85% of not-previously-seen malicious PDF samples, but by combining a machine learning model with the AV engine, we were able to improve our detection to accurately detect more than 95% of novel malicious PDFs.
But at the volumes we see of malicious document file types, that 5% can be pretty significant. So since last year, we’ve continued the work on using machine learning to attack the mal-PDF and malicious Microsoft Office document (maldoc) problem. A few weeks ago, at Black Hat Asia 2019 in Singapore, I presented our latest machine learning (ML) research on malware detection using antivirus (AV) heuristic rules, in which most traditional AV solutions are based: Weapons of Office Destruction: Prevention with Machine Learning.
More specifically, the approach leverages the thousands of heuristic rules already used in traditional AV solutions. We believe that strong, domain knowledge-based heuristic rules in extant AV engines provide a powerful, as-yet untapped signal for training ML detection engines that is highly complementary to more typical statistical features that are used in the absence of strong domain knowledge.
Testing maldoc prevention
We evaluated the effectiveness of our proposed approach against one of the most popular malware delivery vectors – weaponized Microsoft Office documents. The broad-brush popularity of Office documents led them to become one of the main malware delivery mechnisms via email attachments or web downloads.
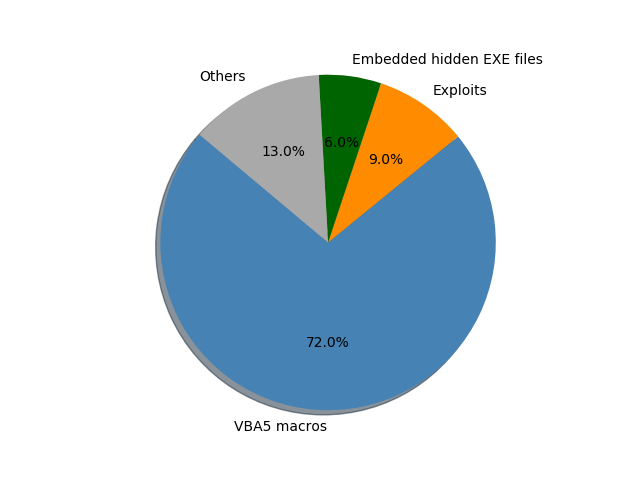
According to a previous Sophos report, over 80% of document-based malware were delivered via either Word or Excel files. Even though these attacks are not new in nature, the increasing volume and complexity of the attacks pose a huge challenge to traditional signature-based AV products.
In the demonstration, we used a comprehensive list of more than 3000 heuristic rules to train the machine learning model. We collected a sample set of about 100,000 Office documents — a mix of malicious and benign files — for testing and to further refine the model.
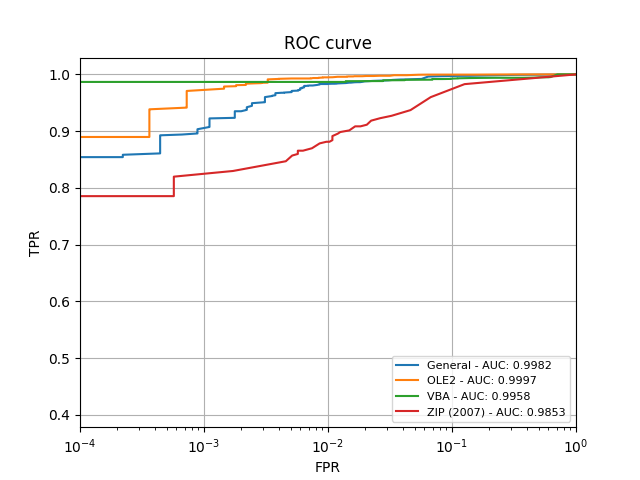
Our results exhibited promising performance and detection rates. Our proposed approach gets us much closer to the accuracy rates we were trying to achieve, which we were able to measure and show in the Receiver Operating Characteristic (ROC) curve shown in the chart above.
The ROC chart compares true- to false-positives, and shows how the model was able to come extremely close to a perfect “true positive” rate, averaging at greater than 99.5% for text and document file types, and more than 98.5% of compressed .zip archives.
One way to characterize the performance of a model across a range of these rates is by measuring the “Area Under the (ROC) Curve”, or AUC. A value of 1.0 means that the model is capable of detecting all malware in the test set without mislabeling any benign files, while a value of 0.5 means that the model is no better than flipping a coin.
Our approach, shown in the plots above, can achieve an AUC of greater than 0.99 on most file types.
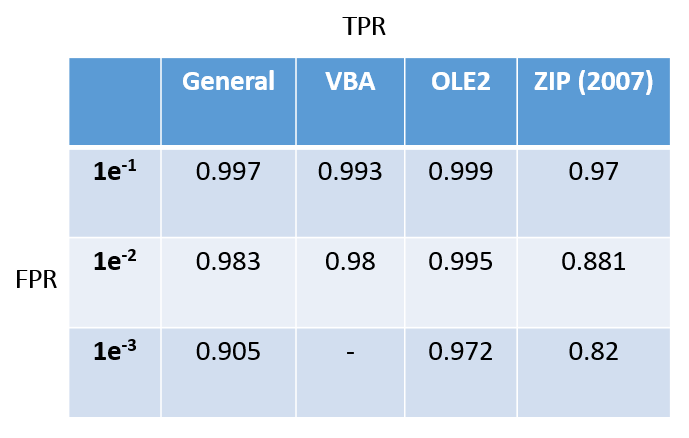
The table below shows the specific true-positive rates (TPR) a model can achieve whilst maintaining certain false-positive rates (FPR). As it shows, TPR deceases when we have less tolerance with FPR. The best model is with the OLE2 model which can achieve 97.2% TPR whilst maintaining an FPR of 1 in 1000. It’s worth noting that, due to the small sample set used in this demonstration, the TPR values are not reliable as FPR goes below 1 in 1000 (or 1 in 100 for VBA model).
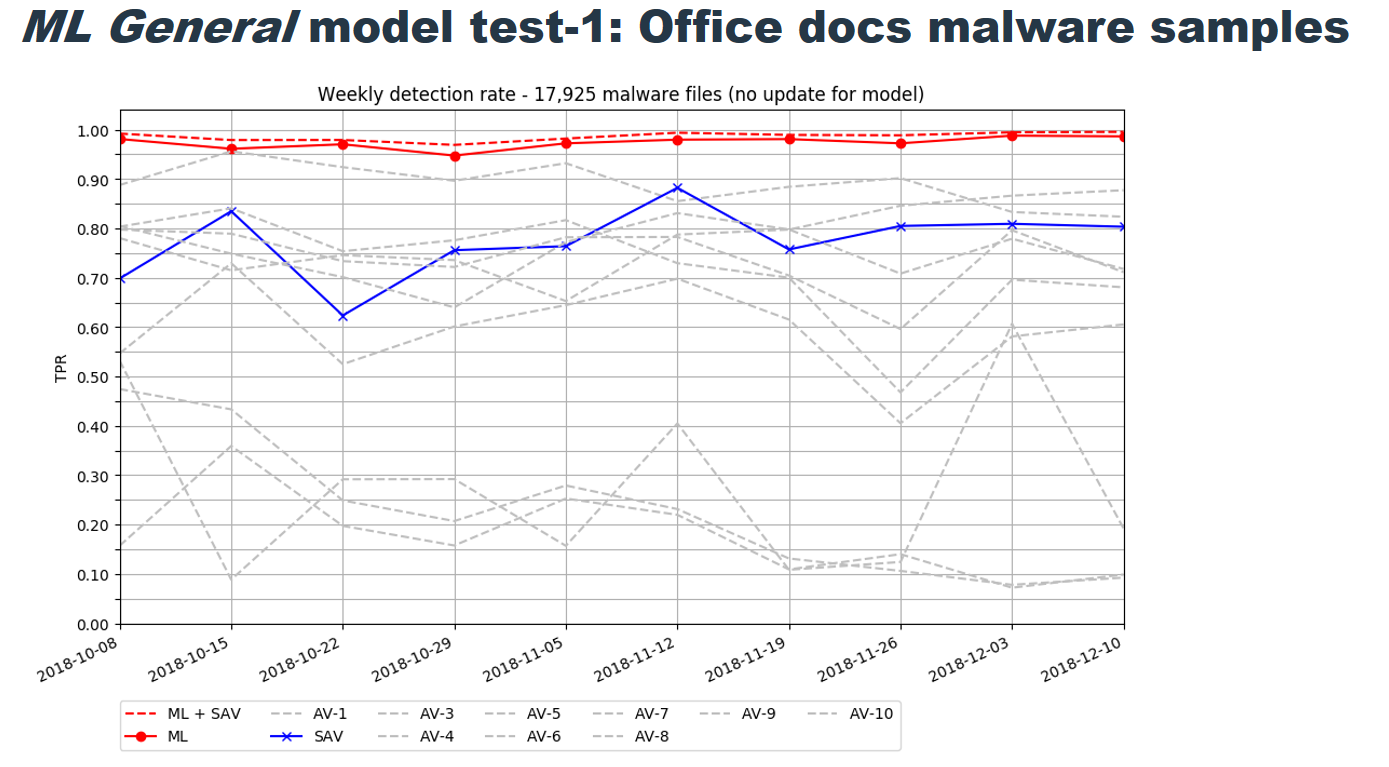
That’s a big win for machine learning in its fight against malware.
Leave a Reply