



You’re in a long queue at the station and your train is due soon, but there are four ticket windows open and things are moving quickly and smoothly.
You’ll have plenty of time to buy your ticket, saunter to the platform and be off on your journey.
But then one of the ticket officials puts up a POSITION CLOSED sign and goes off shift; IT arrives to service the credit card machine at the second window; the third window gets a paper jam…
…and you hear the customer at the last working window say, “I’ve changed my mind – I don’t want to travel via Central London after all, so I’d like to cancel these tickets I just bought and find a cheaper route.”
A delay that would have been little more than a irritation at any other time ends up causing a Denial of Service attack on your travel.
It won’t take you an extra hour to buy your ticket, but it will take you an extra hour to wait for the next train after you’ve narrowly missed the one you thought you’d timed perfectly.
If this has ever happened to you, you’ll appreciate this research paper from at the recent USENIX 2018 conference: Freezing the Web: A Study of ReDoS Vulnerabilities in JavaScript-based Web Servers.

The connection between missed trains and frozen websites might not immediately be obvious, so let’s explain.
Old-school (OK, old-school-ish) web servers like Apache typically use a separate process or thread to handle each connection that arrives.

Processes and threads aren’t quite the same – typically a process is a running app in its own right; each process can then subdivided into a number of sub-applications called threads, sometimes referred to as lightweight processes. Nevertheless, you can think of a both processes and threads as programs – they’re created, launched, scheduled, managed and killed off by the operating system. This means there’s quite a lot of overhead in starting, switching and stopping them – load that can really get in the way on a busy web server that’s handling hundreds or thousands of short-lived connections every second.
In our station ticket office analogy, a multi-process or multi-threaded web server wheels out your very own temporary ticket window when you arrive, and you’re assigned to it regardless of what’s going on at other ticket windows.
Under modest load, this works really well, because you’re insulated from the effects of being mixed in with other travellers, some of whom might ask questions that unexpectedly take a long time to answer and hold everyone up.
But under heavy load, the the multi-process model starts to get sluggish – the server and operating system take longer building separate ticket windows for everyone than they do issuing tickets, so everyone waits longer than necessary.
React to traffic, not to connections
Many modern web servers, therefore, notably those written in JavaScript using progamming environments such as Node.js, are event-driven rather than connection-driven.
Loosely speaking, the system assigns one process to handle all the network traffic, working on any user’s outstanding transactions only when there’s something new to go on.
This model is more like the waiting area in a burger joint or a fish-and-chip shop, where you place your order on arrival; when it’s ready, someone calls your number so you can collect your food and leave.
While you’re waiting, there’s no point in having a member of staff assigned specially to look after you, or a cash register already allocated to you but tied up until it’s your time to pay.
The staff in a burger bar or chip shop might as well ignore you while you’re waiting – you’ll be waiting anyway, after all – and get on undistracted with other work.
As long as they alert you promptly enough when your order is ready, overall efficiency will typically be higher and therefore everyone’s overall waiting time will be shorter.
That’s the theory, anyway.
When things lock up
The event-driven model does have one weak spot: it can clog up disastrously if even a few key steps in the process take longer than anticipated.
That’s a bit like seeing your burger congealing slowly and sadly behind the counter if you’re order number 32 but the person who calls out the orders is side-tracked trying to sort out an argument with customer 31.
In other words, event-driven servers can be highly efficient…
…provided that they don’t get bogged down dealing with unusual or unexpected events.
And that’s what our researchers went looking for: routine content-handling code in JavaScript web servers that handled unexpected data badly.
Deconstructing web requests
As you can imagine, web servers need to do a lot of text-based pattern matching in order to deconstruct incoming web requests, which might look like this:
GET /products/info.html HTTP/1.1 Host: example.com User-Agent: Mozilla/5.0 Accept-Language: en;q=0.5
The jargon term for pulling text input apart into its important components is parsing.
In the web request above:
- The request needs to be sliced into lines at each line-end marker or carriage return.
- The
GETline needs to be chopped up at each space character. - The header lines need to be teased apart either side of the colon.
- The
Accept-languageheader then needs splitting up at the semicolon. - The setting
q=0.5need to be broken into “key=value” form at the equals sign. (Q is HTTP header shorthand for ‘quality’, although here it rather meaninglessly denotes ‘preference’.)
In many modern programming languages, notably JavaScript, the go-to technique for text matching is a tool called the Regular Expression, or RE for short.
That’s where the cool-sounding threat name ReDoS in the paper title comes from: it means Denial of Service (bogging down the server) through Regular Expressions.
Text matching made simple
Let’s look at the problem of taking the text string q=0.5 and splitting it up into q and 0.5, so we can interpret its meaning.
The old-school way of doing it, familiar to anyone who’s used BASIC, would be to code it by hand, starting with something like this:
POS = FIND(STR$,'=')
We’re assuming that that FIND looks for the position of the first ‘=’ character sign in the text variable STR$, and returns its position, from 1 (the offset of the first character) to LEN(STR$), the length of the string (the offset of the last character).
If FIND comes back with zero, it means it found nothing; otherwise, it tells us where the match happened, so we know where to split the input into the key (the left-hand side) and the value (the right-hand side).
We need to take (POS-1) characters from the left of the equals sign for the key; for the value, we take POS characters less than the length of the string from the right hand end:
POS = FIND(STR$,"=") : REM Look for an equals IF POS > 0 THEN : REM If there is one... KEY$ = LEFT$(STR$,POS-1) : REM ...chop from the left VAL$ = RIGHT$(STR$,LEN(STR$)-POS) : REM ...and to the right END

That code is fairly easy to understand, and very efficient, because it precisely encodes the simple algorithm of “look for the splitting point and then do the chopping”.
But it’s a bit of a pain to have to spell out the process of matching the pattern instead of just being able to express a pattern and let a matching utility do the work, which is what you can do with regular expressions.
Here’s an RE that could be used, not correctly but effectively enough, in place of the hard-wired code above: (.+)=(.+).
REs look cryptic, because of the weird and confusing way they use characters as abbreviations – indeed, their cryptic look makes them easy to get wrong:
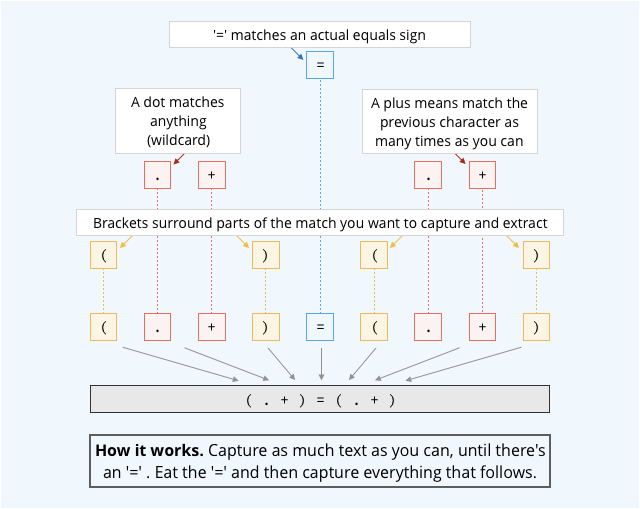


Easy to get wrong
Once you get used to REs, however, they’re hard to wean yourself off, because they’re simple and, well, expressive.
In a contemporary programming language, you might be able to replace something like this, where str.find matches a character and str.sub explicitly extracts a substring…
pos = str.find('=')
if pos then
key = str.sub(1,pos-1)
val = str.sub(pos+1)
else
key = nil
end
…with the rather more elegant-looking, and more easily tweaked, use of an RE-matching library:
key,val = str.match('(.+)=(.+)')
The problem, as the researchers of the ReDoS paper point out, is that REs like the one above do the job you want, and easily pass software acceptance tests, yet do their job wrongly.
The problem is that the RE above matches anywhere in the input text, and the str.match function tries as hard as it can to find a match – a time-consuming side-effect that you probably won’t notice until:
- The input is longer than a few thousand characters.
- The input does NOT contain an equals sign anywhere.
Note that the only character this RE has to latch onto explicitly is an equals sign.
If there isn’t an equals sign, the RE will try to match its pattern starting at offset 1 in the input string, but will fail; the matcher will then try again from offset 2, and fail again; then from the third character along; and so on.
As a result, it will test out its pattern against characters 1 to LEN in the input; then redundantly against characters 2 to LEN, which will fail again; and so on until there are fewer than three characters left. (The RE can’t match fewer than three characters – the pattern calls for at least one before the equals, the equals itself, and at least one after it.)
If there are LEN characters in the input, the matching function ends up running LEN times, against an average of LEN/2 characters, which is proportional to the square of LEN, causing a massive crunch in performance as LEN increases.
You need to tell the RE matcher to lock the match to the start of the input so that it only goes through the input data once.
For that, you can use the special RE characters ^, which means “match only at the very start”, and $, which means “match only the the very end”.
This is known as anchoring the search.
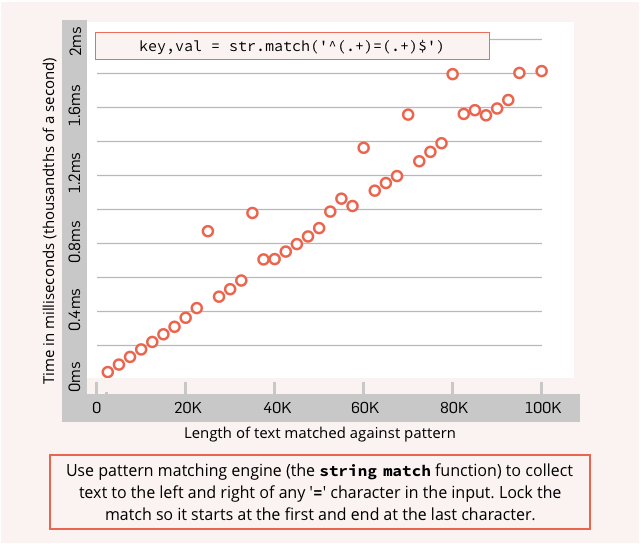
The difference in performance is enormous, and gets quadratically worse for the unanchored match as the input gets longer.
Note that in the graphs below, the axis showing the linear performance of the anchored match tops out at 2/1000ths of second for a 100K input string, while the quadratically performing unanchored match takes more than one full second for the same job.
That’s 500 times slower because of the missing lockdown character ^ at the start of the RE, with the discrepancy getting worse at an ever increasing rate as the input size increases further:



What to do?
The ReDoS paper isn’t terribly bad news, but it is a potent reminder that code that looks right, and that actually works, may fail badly in real life.
In particular, clogging up an event-driven web server with pathologically devised HTTP headers – parsing that is performed as matter of routine for every incoming request – could make an otherwise-secure server easy to “freeze” with a ReDoS attack.
The researchers discovered numerous examples of real-world code that could, in theory, very easily be brought to its knees because of an overly casual use of regular expressions to pre-process web headers.
If you can figure out a malformed header that a badly-chosen string matching RE will choke on, you’ve got the raw material for a ReDoS.
In some cases, the risky REs – the possible causes of a ReDoS – were not unique to one company’s customised code, but were inherited from a standard programming library.
Fortunately, the problems are easily fixed:
- Review pattern matching code carefully. Performance is important, especially when it can be affected by untrusted data sent in from outside.
- Include pathological samples in your test set. Don’t test pattern matching only for its accept/reject capabilities – test that it can accept or reject input within well-defined time limits.
- Limit how much long any pattern matching function can run. The researchers found at least one server-side RE than ran in a time that was exponential with the length of the input – that’s way more dramatic and risky than the quadratic performance we showed above.
- Treat patterns that perform badly as a sign of trouble. Complex REs that occasionally run for ages are more likely to match where they shouldn’t – what’s known as a false positive. The longer an RE runs, the harder it’s trying to find a match and the more time it has to find an unanticipated one.
- Read the ReDoS paper. Some of the problematic REs found in real-world use come from standard libraries, so it’s not just your own code that’s at risk – learn how to spot trouble before it happens.
- Divide and conquer. A series of simple, easy-to-understand checks is much easier to test and to maintain than a mega-complex super-combination RE that tries to pack multiple tests into one arcane formula.

