 These days, every company knows that having its website appear at the top of Google’s results for relevant keyword searches makes a big difference in traffic and helps the business. Numerous search engine optimization (SEO) techniques have existed for years and provided marketers with ways to climb up the PageRank ladder.
These days, every company knows that having its website appear at the top of Google’s results for relevant keyword searches makes a big difference in traffic and helps the business. Numerous search engine optimization (SEO) techniques have existed for years and provided marketers with ways to climb up the PageRank ladder.
In a nutshell, to be popular with Google, your website has to provide content relevant to specific search keywords and also to be linked to by a high number of reputable and relevant sites. (These act as recommendations, and are rather confusingly known as “back links,” even though it’s not your site that is doing the linking.)
Google’s algorithms are much more complex than this simple description, but most of the optimization techniques still revolve around those two goals. Many of the optimization techniques that are being used are legitimate, ethical and approved by Google and other search providers. But there are also other, and at times more effective, tricks that rely on various forms of internet abuse, with attempts to fool Google’s algorithms through forgery, spam and even hacking.
One of the techniques used to mislead Google’s page indexer is known as cloaking. A few days ago, we identified what we believe is a new type of cloaking that appears to work very well in bypassing Google’s defense algorithms.
The idea of cloaking is to tell Google’s search engine one thing when it comes looking, but show something completely different to human visitors.
This is possible because search engines give away their presence by setting a special field inside the web request that asks for content. Where your browser might put text like “User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3)” into its web request, Google identifies itself as “Googlebot.”
A cloaked page would serve the Googlebot with content that is stuffed with keywords to suggest that your site is relevant to specific search terms. In the past, this technique was heavily used in malware attacks, so that searching for “Justin Bieber” and then following a link found in search results could actually take you to an exploit-ridden malicious website instead. (This Naked Security article explains how these attacks work.)
But regular visitors would see a regular page, so everything would look normal and no one would realize that there was a problem worth reporting.
The second most important part of search result manipulation is to ensure that Googlebot sees other relevant and well-ranked sites that include links to yours. This lets Googlebot assume that your website isn’t just relevant to those keywords, but is also popular and recognized by other Internet users. To make this happen, legitimate marketers rely on generating attractive content, building cross-linking agreements, promoting sites on social networks and paying for advertisements. On the other side, rogue SEO marketers spam their links on blogs and forums by posting fake comments, create dedicated websites to form a “link farm” and, in the worst case, hack into legitimate sites to plant pages that link to theirs. This technique is known as link spamming.
In response to this, the engineers at Google made a number of improvements to their page-ranking algorithms (notably the Panda engine releases). Those improvements aimed to make it difficult and expensive to achieve high page ranks using malicious methods. Today’s fine-tuned version is doing a good job against known techniques, but this doesn’t stop rogue actors from trying to find loopholes and weaknesses in the algorithm.
Our discovery of a new search poisoning method came from a Sophos Antivirus detection that Jason Zhang of SophosLabs created based on a suspicious-looking PDF file. In short order, we received hundreds of thousands of unique PDF documents per day that triggered this detection.
After quick inspection, we realized that someone was using cloaking techniques to poison search results, but instead of feeding fake HTML pages to the Googlebot, they were using PDFs instead.
As far as we can tell, Google’s cloaking-detection algorithms, which aim to spot web pages that have been artificially (and unrealistically) loaded with keywords, aren’t quite so strict when the bogus content is supplied in a document. It seems that Google implicitly trusts PDFs more than HTML, in the same way that it trusts links on .edu and .gov sites more than those on commercial web pages.
When doing a Google search for keywords found inside those PDFs we found a large amount of similar documents on a number of legitimate, but unrelated and likely compromised, websites. In addition to the heavy use of specific keywords, the PDFs include links to documents planted on other websites, forming a so-called “back link wheel.”
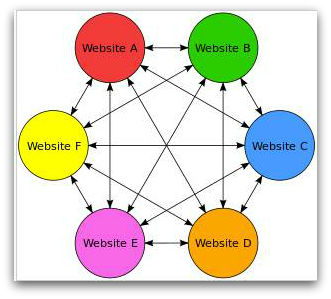
(Image source: Wikipedia)
This trick seems to have been enough to trick Google into giving the documents an artificially high search ranking.
The final step in the scenario was to redirect the unsuspecting users who click on a PDF link to a promoted website.
We suspect that this technique could be used for a variety of purposes, including the distribution of malware. So far, however, we have only seen it in a marketing campaign to promote so-called “binary trading” broker services.
Here is an example of the first page of poisoned search results:
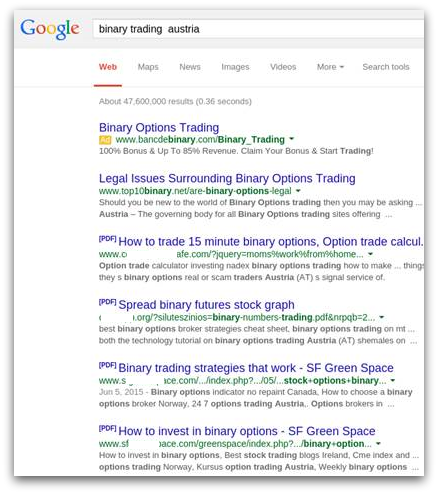
Almost every link that we see on the results page belongs to this campaign. It is particularly successful and obvious when you search for a combination of lower-frequency keywords like “Austria” and “binary trading” as in the example above.
When clicked, the PDF links redirect to the website for a “binary options” trading broker:
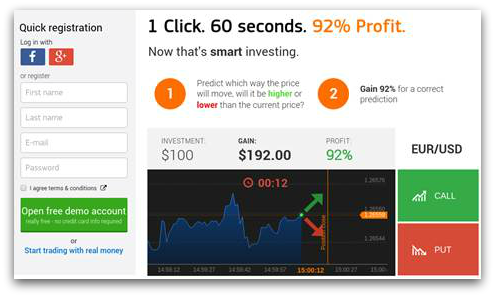
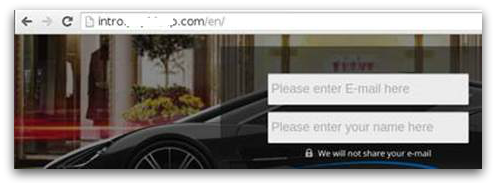
At a later stage the same links pointed to a seemingly different get-rich-fast scheme:
In order to see the actual PDF document, we need to select its cached version in Google’s search result, in the menu next to the link:

A document that looks legitimate at first glance turns into complete nonsense when you start reading it. Also, you can clearly see the hyperlinks placed throughout the document. Those are the links that, when followed, expose the whole link farm to the Googlebot.
Many other phrases and keyword combinations within the document give us a good idea of what else we could search for. A quick analysis reveals that many three-word combinations found in the document would lead to the same PDFs when searched. Even a fairly broad search, like “safe stock trade US” would bring those links to the very top of the results:
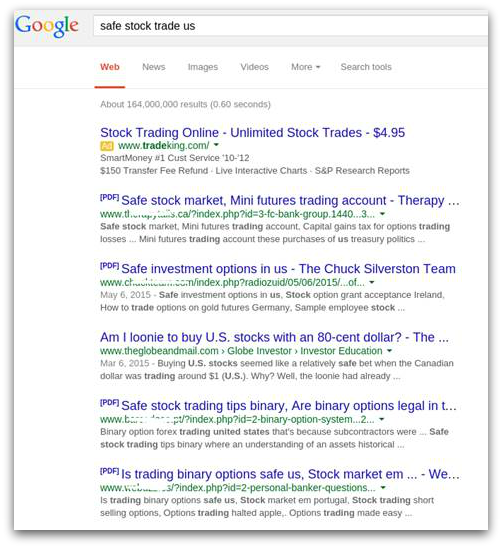
In order to see what happens when Google’s crawler visits the link, we can run a web client program with the User-Agent header string set to “Googlebot”:
$ curl -is --user-agent "Googlebot" "http://www.[WEBSITE].com/?index.php?id=[ARGS]"
HTTP/1.1 200 OK
Date:
Server: Apache
Transfer-Encoding: chunked
Content-Type: application/pdf
%PDF-1.3
1 0 obj
<< /Type /Catalog
/Outlines 2 0 R
[...]
But to observe what unsuspecting users would see if they clicked on what they thought was a link to a PDF document, we can simply use a web browser with developer tools. Here is an example of the redirection chain that takes place:

Not surprisingly, the redirection involves some TDS sites (Traffic Distribution Systems) that pass along a unique ID of the affiliate marketer responsible for this campaign.
We provided detailed information about our findings to Google, along with notice about our intent to publish. Google acknowledged our communication but chose not to comment further. We trust that the necessary measures are being taken to counter these search result poisoning attempts.
Faz
Do you think that’s likely to encourage Google to buy Sophos ?
wally
nice!
Adam
Fascinating.
Jamie E
Most readable and enlightening indeed. Thank you.
Raj
With exactly the same modus operandi, spammers hide links in docs.google.com too. Check it out.
FLAT PACK BART
Just another short term black hat technique..
I wonder if they did benefit from it at all. Do you think a disappointed user would go for such a “get rich fast” scheme?
I certainly would not. ..
MJ
LOL!…..I cant believe this is still possible, I used the same methods to locate, visit and retrieve a very large potion of newly active and relevent malwares before most AV labs had seen the first sample. I fear “The Old Dog” will continue to mock us all for some time to come, following some old timers philosophy, “If it aint broke, dont fix it!” Expanded into something like this….if it aint broke, dont fix it, just clean it up and repack it with a different crypting tool, thus making a brand new,never seen before by anyone, Identical piece of malware code, just dressed differently!
Gonna be a long Friday!